

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Можно показать (см. задачу 12.2), что, во-первых, последнее слагаемое в правой части равенства (12.4) равно нулю, т. е.
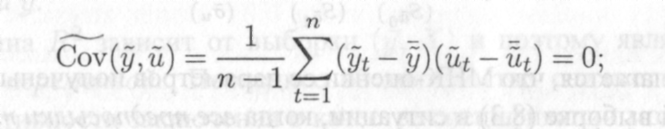 12.7
12.7
а во-вторых, второе слагаемое в правой части (12.4)
12.8
Следовательно, в качестве меры, объясняющей способности регрессора в модели (8.1'), может служить в пределах обучающей выборки (у, X) величина
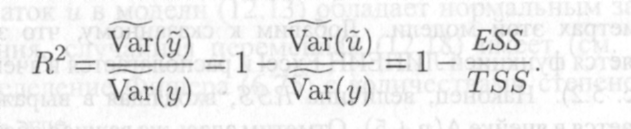 12.9
12.9
Она именуется коэффициентом детерминации модели и равна доле эмпирической дисперсии переменной у, которая в рамках обучающей выборки (у, X) объясняется в модели (8.1') ее регрессором х. Из равенств (12.5), (12.7) и (12.9) следует, что всегда
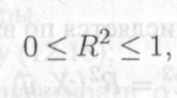 12.10
12.10
причем если Я2 = 1, то значения уг переменной у полностью объясняются в выборке (у, X) значениями хг регрессора х, поскольку ESS = 0 и, следовательно,
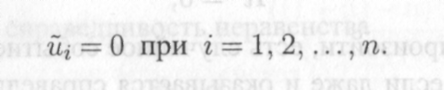 12.11
12.11
Напротив, когда В? = 0, то спецификация (8.1'), очевидно, совершенно плоха, так как в рамках такой модели регрессор х абсолютно неспособен объяснять значения переменной у. Заметим, что ситуация совершенно плохой спецификации равносильна справедливости статистической гипотезы (см. занятие 7)
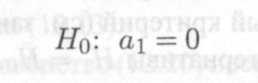 12.12
12.12
о коэффициенте ai модели (8.1').
Выше выяснили смысл коэффициента детерминации R2 и правило (12.9) его вычисления. Сейчас обратим внимание на то обстоятельство, что R2 вычисляется по выборочным данным
 12.15
12.15
а следовательно, является случайной переменной. По этой причине событие R2=0
которое может произойти, есть случайное событие (см. занятие 6). В то же время, если даже и оказывается справедливым желаемое неравенство R2˃0
то в силу опять-таки случайного характера величины R2 еще нет полного основания для отклонения гипотезы (12.12) или (12.14) о неудовлетворительной спецификации линейной модели (12.13). Нужен формализованный критерий (см. занятие 7) проверки гипотезы (12.14) против альтернативы Н1= Н0
26. Связь коэффициента детерминации с коэффициентом корреляции экзогенной и эндогенной переменных модели.
Если факторные признаки различны по своей сущности и/или имеют различные единицы измерения, то коэффициенты регрессии ![]() при разных факторах являются несопоставимыми. Поэтому уравнение регрессии дополняют соизмеримыми показателями тесноты связи фактора с результатом, позволяющими ранжировать факторы. К ним относят: частные коэффициенты эластичности, β-коэффициенты, частные коэффициенты корреляции.
при разных факторах являются несопоставимыми. Поэтому уравнение регрессии дополняют соизмеримыми показателями тесноты связи фактора с результатом, позволяющими ранжировать факторы. К ним относят: частные коэффициенты эластичности, β-коэффициенты, частные коэффициенты корреляции.
Парные коэффициенты корреляции. Для измерения тесноты связи между двумя из рассматриваемых переменных (без учета их взаимодействия с другими переменными) применяются парные коэффициенты корреляции. Методика расчета таких коэффициентов и их интерпретации аналогичны линейному коэффициенту корреляции в случае однофакторной связи.
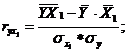
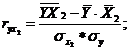
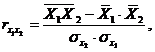
![]() - среднее квадратическое отклонение факторного признака;
- среднее квадратическое отклонение факторного признака;
![]() среднее квадратическое отклонение результативного признака.
среднее квадратическое отклонение результативного признака.
Коэффициент частной корреляции измеряет тесноту линейной связи между отдельным фактором и результатом при устранении воздействия прочих факторов модели.
Для качественной оценки тесноты связи можно использовать следующую классификацию:
0.1- 0.3- слабая связь
0.3-0.5 – умеренная связь
0.5-0.7- заметная связь
0.7-0.9- тесная связь
0.9-0.99- весьма тесная
Для расчета частных коэффициентов корреляции могут быть использованы парные коэффициенты корреляции.
Для случая зависимости Y от двух факторов можно вычислить 2 коэффициента частной корреляции:
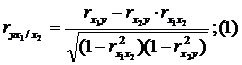 (2-ой фактор
(2-ой фактор ![]() фиксирован);
фиксирован);
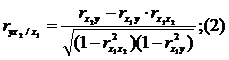 (1-ый фактор
(1-ый фактор ![]() фиксирован).
фиксирован).
Это коэффициенты частной корреляции 1-ого порядка (порядок определяется числом факторов, влияние которых на результат устраняется).
Частные коэффициенты корреляции, рассчитанные по таким формулам изменяются от -1 до +1. Они используются не только для ранжирования факторов модели по степени влияния на результат, но и также для отсева факторов. При малых значениях 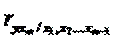 нет смысла вводить в уравнение m-ый фактор, т. к. качество уравнения регрессии при его введении возрастет незначительно (т. е. теоретический коэффициент детерминации увеличится незначительно).
нет смысла вводить в уравнение m-ый фактор, т. к. качество уравнения регрессии при его введении возрастет незначительно (т. е. теоретический коэффициент детерминации увеличится незначительно).
Совокупный коэффициент множественной корреляции или индекс множественной корреляцииопределяет тесноту совместного влияния факторов на результат:
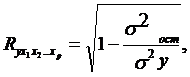
![]() остаточная дисперсия;
остаточная дисперсия;
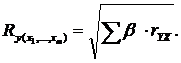
![]()
![]() . Он принимает значения от 0 до 1 (в отличие от парного коэффициента корреляции, который может принимать отрицательные значения, R используется без учета направления связи). Чем плотнее фактические значения
. Он принимает значения от 0 до 1 (в отличие от парного коэффициента корреляции, который может принимать отрицательные значения, R используется без учета направления связи). Чем плотнее фактические значения ![]() располагаются относительно линии регрессии, тем меньше остаточная дисперсия и, следовательно, больше величина
располагаются относительно линии регрессии, тем меньше остаточная дисперсия и, следовательно, больше величина ![]() . Таким образом, при значении R близком к 1, уравнение регрессии лучше описывает фактические данные и факторы сильнее влияют на результат; при значении Rблизком к 0 уравнение регрессии плохо описывает фактические данные и факторы оказывают слабое воздействие на результат.
. Таким образом, при значении R близком к 1, уравнение регрессии лучше описывает фактические данные и факторы сильнее влияют на результат; при значении Rблизком к 0 уравнение регрессии плохо описывает фактические данные и факторы оказывают слабое воздействие на результат.
При трех переменных для двух факторного уравнения регрессии данная формула совокупного коэффициента множественной корреляции легко приводится к следующему виду:
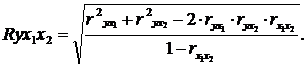
Чем R ближе к единице, тем совокупное влияние изучаемых показателей x1 и x2 на результативный факторy больше (корреляционная связь более интенсивная).
Множественный (совокупный) коэффициент детерминации определим как квадрат множественного коэффициента корреляции. Показывает, какая доля вариации изучаемого показателя объясняется влиянием факторов, включенных в уравнение множественной регрессии. Его значение - в пределах от нуля до единицы. Чем ближе множественный коэффициент детерминации к единице, тем вариация изучаемого показателя в большей мере характеризуется влиянием отобранных факторов. ![]()
27.Показатели качества регрессии: F-тест.
F-тест - оценивание качества уравнения регрессии - состоит в проверке гипотезы Н0 о статистической незначимости уравнения регрессии и показателя тесноты связи. Для этого выполняется сравнение фактического Fфакт и критического (табличного) Fтабл значений F-критерия Фишера. Fфакт определяется как
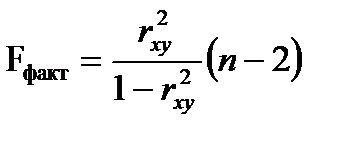

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
