

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Значения неучтенных факторов будут равняться разнице между фактическим значением переменной и ее прогнозным значением. Т. о впоследствии можно будет оценить влияние неучтенных факторов.
5. Схема построения эконометрических моделей.
Построение эконометрических моделей состоит из нескольких этапов.
1. Спецификация или построение математической модели на основании данных.
2.Сбор статистических данных об объекте-оригинале в виде значений эндогенных и экзогенных переменных.
3.Оценивание неизвестных параметров модели с помощью обучающей выборки в результате которого мы получаем оценочное значение параметров и оценочное значение СКО. В результате этого мы получаем оцененную модель.
4.Проверка адекватности оцененной модели, т. е проверка соответствия построенной модели объекту-оригиналу с помощью контрольной выборки.
6. Линейная модель множественной регрессии. Порядок её оценивания методом наименьших квадратов в Excel. Смысл выходной статистической информации функции ЛИНЕЙН.
Система состоит из равенств:1)y=a0+a1*x1+a2*x2+u; 2)E(u/x1,xt)=0; 3)E(u2/x1,x2)=r2u. x1,x2- экзоген перем, y-эндоген перемен. случ возмещен предполаг гомоскедастичн. спецификация содержит 4 параметра. это модель линейная эконометрич в виде изолир уравнений с несколькими объясняющ перемен или модель лин множ регрессии. эконом смысл коэф-ов а1 и а2-ожидаемые предельн знач перемен у по перемен х. это базовая модель, т.к.1)к такой модели мб приближенна практич любая эконометрич модель в виде изолир уравнения;2)поведен ур-ия в линейн моделях имеют такой же вид. эконометрич инвестиц модель Самуэльсона-Хикса явл частн случаем модели
Дана линейная эконометрическая модель со спецификацией вида
7. Регрессионные модели с переменной структурой (фиктивные переменные).
(фиктивные переменные)
Термин “фиктивные переменные” используется как противоположность “значащим” переменным, показывающим уровень количественного показателя, принимающего значения из непрерывного интервала. Как правило, фиктивная переменная — это индикаторная переменная, отражающая качественную характеристику. Это могут быть разного рода атрибутивные признаки, такие, например, как профессия, пол, образование, климатические условия, принадлежность к определенному региону. Чтобы ввести такие переменные в регрессионную модель, им должны быть присвоены те или иные цифровые метки, т. е. качественные переменные преобразованы в количественные. Такого вида сконструированные переменные в эконометрике принято называть фиктивными переменными. В литературе можно встретить термины «структурные переменные» или «искусственные переменные»
Например, в результате опроса группы людей 0 может означать, что опрашиваемый — мужчина, а 1 — женщина. К фиктивным переменным иногда относят регрессор, состоящий из одних единиц (т. е. константу, свободный член), а также временной тренд.
Использование фиктивных переменных в моделях с временными рядами
В регрессионных моделях с временными рядами используется три основных вида фиктивных переменных:
1) Переменные-индикаторы принадлежности наблюдения к определенному периоду — для моделирования скачкообразных структурных сдвигов. Границы периода (моменты “скачков”) должны быть установлены из априорных соображений. Например, 1, если наблюдение принадлежит периоду 1941-45 гг. и 0 в противном случае. Это пример использования для моделирования временного структурного сдвига. Постоянный структурный сдвиг моделируется переменной равной 0 до определенного момента времени и 1 для всех наблюдений после этого момента времени.
2) Сезонные переменные — для моделирования сезонности. Сезонные переменные принимают разные значения в зависимости от того, какому месяцу или кварталу года или какому дню недели соответствует наблюдение.
3) Линейный временной тренд — для моделирования постепенных плавных структурных сдвигов. Эта фиктивная переменная показывает, какой промежуток времени прошел от некоторого “нулевого” момента времени до того момента, к которому относится данное наблюдение (координаты данного наблюдения на временной шкале). Если промежутки времени между последовательными наблюдениями одинаковы, то временной тренд можно составить из номеров наблюдений.
Временной тренд отличается от бинарных фиктивных переменных тем, что имеет смысл использовать его степени: t2 , t3 и т. д. Они помогают моделировать гладкий, но нелинейный тренд. (Бинарную переменную нет смысла возводить в степень, потому что в результате получится та же самая переменная.)
Можно также комбинировать указанные виды фиктивных переменных, создавая переменные “взаимодействия” соответствующих эффектов.
Комбинация рассмотренных фиктивных переменных позволяет моделировать еще один эффект — изменение наклона тренда с определенного момента. Помимо тренда в регрессию следует тогда ввести следующую переменную: в начале выборки до некоторого момента времени она равна 0, а вторая ее часть представляет собой временной тренд (1, 2, 3 и т. д. в случае одинаковых интервалов между наблюдениями).
Использование фиктивных переменных имеет следующие преимущества:
1) Интервалы между наблюдениями не обязательно должны быть одинаковыми. В выборке могут быть пропущенные наблюдения.
2) Коэффициенты при фиктивных переменных легко интерпретировать, они наглядно представляют структуру динамического процесса.
3) Для оценивания модели не приходится выходить за рамки классического метода наименьших квадратов.
8. Выборочные значения основных количественных характеристик случайной переменной и их вычисление в Excel.
Закон (ряд) распределения дискретной СВ даёт исчерпывающую информацию о ней, так как позволяет вычислить вероятности любых событий, связанных со СВ. Однако такой закон (ряд) распределения бывает трудно обозримым, не всегда удобным (и даже необходимым) для анализа.
Поэтому для описания случайных величин часто используются их числовые характеристики – числа, в сжатой форме выражающие наиболее существенные черты распределения СВ. Наиболее важными из них являются математическое ожидание, дисперсия, среднее квадратическое отклонение и др. Обращаем внимание на то, что в силу определения, числовые характеристики случайных величин являются числаминеслучайными, определёнными.
Математическим ожиданием, или средним значением, М(Х) дискретной случайной величины Хназывается сумма произведений всех её значений на соответствующие им вероятности:
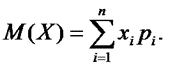
Для мат. ожидания используют также обозначения: E(X),
При n→∞ мат. ожидание представляет сумму ряда 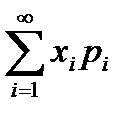 , если он абсолютно сходится.
, если он абсолютно сходится.
Свойства мат. ожидания:
1) M(C)=C, где C – постоянная величина;
2) M(kX)=kM(X);
3)M(X±Y)=M(X)±M(Y);
4) M(XY)=M(X)·M(Y), где X, Y – независимые случайные величины;
5) M(X±C)=M(X)±C
6) M(X-a)=0, где a=M(X).
Дисперсией D(X) случайной величины Х называется математическое ожидание квадрата её отклонения от математического ожидания: D(X)=M[X-M(X)]2 или D(X)=M(X-a)2 (3), где a=M(X).
(Для дисперсии СВ Х используется также обозначение Var(X).)
Дисперсия характеризует отклонение (разброс, рассеяние, вариацию) значений СВ относительно среднего значения.
Если СВ Х – дискретная с конечным числом значений, то
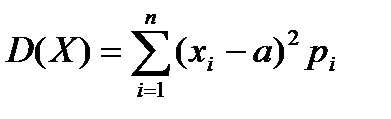 .
.
Дисперсия D(X) имеет размерность квадрата СВ, что не всегда удобно. Поэтому в качестве показателя рассеяния используют также величину 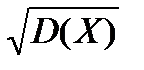 .
.
Средним квадратическим отклонением (стандартным отклонением или стандартом) σх случайной величины Х называется арифметическое значение корня квадратного из её дисперсии:
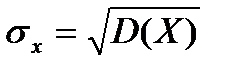 .
.
Свойства дисперсии СВ:
1) D(C)=0, где C – постоянная величина;
2) D(kX)=k2D(X);
3) D(X)=M(X2)-a2 где a=M(X);
4)D(X+Y)=D(X-Y)=D(X)+D(Y), где X и Y – независимые случайные величины.
9. Ковариация, Cov(x, y), и коэффициент корреляции, Cor(x, y), пары случайных переменных (x, y).
Под случайной величиной понимается переменная, которая в результате испытания в зависимости от случая принимает одно из возможного множества своих значений (какое именно – заранее не известно).
Ковариация служит для характеристики тесноты связи между случайными величинами. Если (x, y) — пара случайных переменных, то их ковариацией называется константа Сху=Cov(x, y)=E(x·y)-E(x)·E(y)
Свойства математического ожидания позволяют представить Сху и так: Сху=E((x-mx)·(y-my)), где mx=E(x), my=E(y)
Для вычисления Сху нужно знать закон распределения Pxy(q, r) пары (x, y). Если он неизвестен, то ковариацию можно оценить по выборке из генеральной совокупности Ω(x, y): {(x1, y1), (x2, y2),…,(xn, yn)}
Оценкой ковариации служит величина
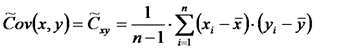

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
