

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
· Модель данных линейна по ![]() и
и ![]() (
(![]() и
и ![]() линейны по
линейны по ![]() );
);
· Отсутствует недоопределённость (то есть ситуация, когда упущены важные факторы) и переопределённость (то есть когда, наоборот, приняты во внимание ненужные факторы); (отсутствие коллинеарности)
· Модель данных адекватна устройству данных (модель данных и устройство данных имеют одинаковую функциональную форму).
Устройство данных — это наблюдения случайной величины. Модель данных — это уравнение регрессии. «Иметь одинаковую функциональную форму» означает «иметь одинаковую функциональную зависимость». Например, если точки наблюдений очевидно расположены вдоль невидимой экспоненты, логарифма или любой нелинейной функции, нет смысла строить линейное уравнение регрессии.
Второе условие: все ![]() детерминированы и не все равны между собой. Если все
детерминированы и не все равны между собой. Если все ![]() равны между собой, то
равны между собой, то ![]() и в уравнении оценки коэффициента наклона прямой в линейной модели в знаменателе будет ноль, из-за чего будет невозможно оценить коэффициенты
и в уравнении оценки коэффициента наклона прямой в линейной модели в знаменателе будет ноль, из-за чего будет невозможно оценить коэффициенты ![]() и вытекающий из него
и вытекающий из него ![]() При небольшом разбросе переменных
При небольшом разбросе переменных ![]() модель сможет объяснить лишь малую часть изменения
модель сможет объяснить лишь малую часть изменения ![]() . Иными словами, переменные не должны быть постоянными.
. Иными словами, переменные не должны быть постоянными.
Третье условие: ошибки не носят систематического характера. Случайный член может быть иногда положительным, иногда отрицательным, но он не должен иметь систематического смещения ни в каком из двух возможных направлений. Если уравнение регрессии включает постоянный член (![]() ), то это условие чаще всего выполняется автоматически, так как постоянный член отражает любую систематическую, но постоянную составляющую в
), то это условие чаще всего выполняется автоматически, так как постоянный член отражает любую систематическую, но постоянную составляющую в ![]() , которой не учитывают объясняющие переменные, включённые в уравнение регрессии.
, которой не учитывают объясняющие переменные, включённые в уравнение регрессии.
Четвёртое условие: дисперсия ошибок одинакова. Одинаковость дисперсии ошибок также принято называть гомоскедастичностью. Не должно быть априорной причины для того, чтобы случайный член порождал бо́льшую ошибку в одних наблюдениях, чем в других. Так как ![]() и теоретическая дисперсия отклонений
и теоретическая дисперсия отклонений ![]() равна
равна ![]() то это условие можно записать так:
то это условие можно записать так: ![]() Одна из задач регрессионного анализа состоит в оценке стандартного отклонения случайного члена. Если рассматриваемое условие не выполняется, то коэффициенты регрессии, найденные по методу наименьших квадратов, будут неэффективны, а более эффективные результаты будут получаться путём применения модифицированного метода оценивания (взвешенный МНК или оценка ковариационной матрицы по формуле Уайта или Дэвидсона—Маккинона).
Одна из задач регрессионного анализа состоит в оценке стандартного отклонения случайного члена. Если рассматриваемое условие не выполняется, то коэффициенты регрессии, найденные по методу наименьших квадратов, будут неэффективны, а более эффективные результаты будут получаться путём применения модифицированного метода оценивания (взвешенный МНК или оценка ковариационной матрицы по формуле Уайта или Дэвидсона—Маккинона).
Пятое условие: ![]() распределены независимо от
распределены независимо от ![]() при
при ![]() Это условие предполагает отсутствие систематической связи между значениями случайного члена в любых двух наблюдениях. Если один случайный член велик и положителен в одном направлении, не должно быть систематической тенденции к тому, что он будет таким же великим и положительным (то же можно сказать и о малых, и об отрицательных остатках). Теоретическая ковариация
Это условие предполагает отсутствие систематической связи между значениями случайного члена в любых двух наблюдениях. Если один случайный член велик и положителен в одном направлении, не должно быть систематической тенденции к тому, что он будет таким же великим и положительным (то же можно сказать и о малых, и об отрицательных остатках). Теоретическая ковариация ![]() должна равняться нулю, поскольку
должна равняться нулю, поскольку ![]() Теоретические средние для
Теоретические средние для ![]() и
и ![]() равны нулю в силу третьего условия теоремы. При невыполнении этого условия оценки, полученные по методу наименьших квадратов, будут также неэффективны.
равны нулю в силу третьего условия теоремы. При невыполнении этого условия оценки, полученные по методу наименьших квадратов, будут также неэффективны.
Выводы из теоремы:
· Эффективность оценки означает, что она обладает наименьшей дисперсией.
· Оценка линейна по наблюдениям ![]()
· Несмещённость оценки означает, что её математическое ожидание равно истинному значению.
19. Система нормальных уравнений и явный вид её решения при оценивании методом наименьших квадратов (МНК) линейной модели парной регрессии.
Рассмотрим механизм применения МНК на примере модели линейной парной регрессии.
![]()
В результате оценивания данной эконометрической модели определяются оценки неизвестных коэффициентов. Метод наименьших квадратов позволяет получить такие оценки параметров a0 и a1, при которых сумма квадратов остатков минимальна:
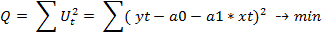
Для нахождения параметров функции и определения минимума функции двух переменных вычисляются частные производные этой функции по каждому из оцениваемых параметров и приравниваются к нулю.
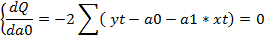
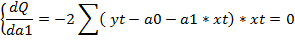
Если разделить обе части каждого уравнения системы на (-2), раскрыть скобки и привести подобные члены, то получим систему нормальных уравнений для определения оценок параметров модели:
![]()
![]()
- Это система нормальных уравнений для определения оценок параметров модели.
Убедимся, что решение системы соответствует минимуму функции, для этого вторые производные должны быть равны нулю.
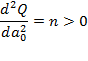
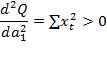
Что и требовалось доказать.
Далее, если решить систему нормальных уравнений, то мы получим искомые оценки неизвестных коэффициентов модели регрессии a0 и a1:
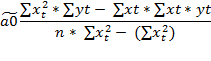
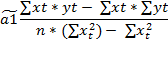
Вывод: указанные выше выражения позволяют по известным значениям наблюдений переменных x и у вычислить оценки параметров модели парно регрессии.
20. Ковариационная матрица оценок коэффициентов линейной модели.
КОВАРИАЦИОННАЯ МАТРИЦА
- матрица, образованная из попарных смешанных вторых моментов (ковариаций) неск. случайных величин(см. Моменты случайной величины). Ковариация между компонентами ![]() и
и ![]() случайного вектора
случайного вектора ![]() определяется как
определяется как
![]()
где М - математическое ожидание, а ![]() . Очевидно, что
. Очевидно, что ![]() есть дисперсия х;.Ковариация величин xi, xj, нормированная на дисперсии
есть дисперсия х;.Ковариация величин xi, xj, нормированная на дисперсии ![]() , наз. корреляции коэффициентом:
, наз. корреляции коэффициентом:

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
