

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
3. Оценка дисперсии регрессии является смещенной оценкой истинного значения дисперсии, во многих случаях занижая его.
В силу вышесказанного выводы по t - и F-статистикам, определяющим значимость коэффициентов регрессии и коэффициента детерминации, возможно, будут неверными. Вследствие этого ухудшаются прогнозные качества модели.
Для обнаружения автокорреляции необходимо наблюдения упорядочить по значению фактора х (как в предыдущем примере) и составить ряды с текущими и предыдущими остатками. Коэффициент корреляции reiej между ei и ej, где ei – остатки текущих наблюдений, ej – остатки предыдущих наблюдений (например, j=i–1) определяется по обычной формуле линейного коэффициента корреляции
Автокорреляция остатков может быть вызвана несколькими причинами, имеющими различную природу. Во-первых, иногда она связана с исходными данными и вызвана наличием ошибок измерения в значениях результативного признака. Во-вторых, причину следует искать в формулировке модели, которая может не включать существенный фактор, влияние которого отражается в остатках, вследствие чего они оказываются автокоррелированными. Очень часто этим фактором является фактор времени, поэтому проблема автокорреляции остатков весьма актуальна при исследовании динамических рядов, что мы рассмотрим в соответствующем разделе.
24. Линейные регрессионные модели с автокоррелированным остатком. Оценивание модели обобщённым методом наименьших квадратов.
При нарушении гомоскедастичности и наличии автокорреляции ошибок рекомендуется традиционный метод наименьших квадратов (метод OLD – Ordinary Least Squares) заменять обобщенным методомGLS(Generalized Least Squares). Он применяется к преобразованным данным и позволяет получать оценки, которые обладают не только свойством несмещенности, но и имеют меньшие выборочные дисперсии.
Суть метода заключается в том, что подбираются коэффициенты Кi, такие, что σ2ei =σ2 ·Кi,
где σ2ei – дисперсия ошибки при конкретном i–ом значении фактора;
σ2 – постоянная дисперсия ошибки при соблюдении предпосылки о гомоскедастичности остатков;
Кi – коэффициент пропорциональности, меняющийся с изменением величины фактора.
Уравнение парной регрессии при этом принимает вид
уi/ ![]() = a0/
= a0/ ![]() + a1хi/
+ a1хi/ ![]() +ei.
+ei.
По отношению к обычной регрессии уравнение с новыми, преобразованными переменными представляют собой взвешенную регрессию, в которой переменные у и х взяты с весами 1/ ![]() . Аналогичный подход применяют и для множественной регрессии, уравнение с преобразованными переменными принимает вид
. Аналогичный подход применяют и для множественной регрессии, уравнение с преобразованными переменными принимает вид
у/ ![]() =a0/
=a0/ ![]() +a1х1/
+a1х1/ ![]() +a2х2/
+a2х2/ ![]() +…+amхm/
+…+amхm/ ![]() +e. (5.1)
+e. (5.1)
Параметры такой модели зависят от концепции, принятой для коэффициента пропорциональности К. В эконометрических исследованиях довольно часто выдвигается гипотеза, что остатки ei пропорциональны значениям фактора. Пусть, например, у – издержки производства, х1 – объем продукции, х2 – основные производственные фонды, х3 – численность работников, тогда уравнение у =a0 +a1х1 +a2х2 + a3х3 +e является моделью издержек производства с объемными факторами. Предполагая, что σ2ei пропорциональна квадрату численности работников (т. е. ![]() = х3), получим в качестве результативного признака затраты на одного работника (у/х3), а в качестве факторов производительность труда (х1/х3) и фондовооруженность труда (х2/х3). Соответственно трансформированная модель примет вид
= х3), получим в качестве результативного признака затраты на одного работника (у/х3), а в качестве факторов производительность труда (х1/х3) и фондовооруженность труда (х2/х3). Соответственно трансформированная модель примет вид
у/ х3 =a3 +a1х1/ х3 +a2х2/ х3 +e,
где вычисленные параметры a3, a1, a2 численно не совпадают с аналогичными параметрами предыдущей модели. Кроме того, коэффициенты регрессии меняют экономическое содержание: из показателей силы связи, характеризующих среднее изменение издержек производства с изменением абсолютного значения соответствующего фактора на единицу, они фиксируют теперь среднее изменение затрат на работника в зависимости от изменения производительности труда на единицу; и в зависимости от изменения фондовооруженности труда на единицу.
Если же предположить, что в первоначальной модели дисперсия остатков пропорциональна квадрату объема продукции, получаем уравнение регрессии
у/ х1 =a1 +a2х2/ х1 +a3х3/ х1 +e,
где у/ х1 – затраты на единицу продукции, х2/ х1 – фондоемкость продукции, х3/х1 – трудоемкость продукции.
Переход к относительным величинам существенно снижает вариацию фактора и соответственно уменьшает дисперсию ошибки.
Метод Главных Компонент (Principal Components Analysis, PCA) – один из основных способов уменьшить размерность данных, потеряв наименьшее количество информации. ирсоном в 1901 г. Он применяется для:
1) наглядного представления данных;
2) обеспечения лаконизма моделей, упрощения счета и интерпретации;
3) сжатия объемов хранимой информации.
Метод обеспечивает максимальную информативность и минимальное искажение геометрической структуры исходных данных. Вычисление главных компонент сводится к вычислению собственных векторов и собственных значений ковариационной матрицы исходных данных. Иногда метод главных компонент называют преобразованием Кархунена-Лоэва или преобразованием Хотеллинга. Другие способы уменьшения размерности данных – это метод независимых компонент, многомерное шкалирование, а также многочисленные нелинейные обобщения: метод главных кривых и многообразий, поиск наилучшей проекции, нейросетевые методы «узкого горла», самоорганизующиеся карты Кохонена и др.
Задача анализа главных компонент, имеет, как минимум, четыре базовых версии:
- аппроксимировать данные линейными многообразиями меньшей размерности;
- найти подпространства меньшей размерности, в ортогональной проекции на которые разброс данных (т. е. среднеквадратичное уклонение от среднего значения) максимален;
- найти подпространства меньшей размерности, в ортогональной проекции на которые среднеквадратичное расстояние между точками максимально;
- для данной многомерной случайной величины построить такое ортогональное преобразование координат, что в результате корреляции между отдельными координатами обратятся в ноль. Подробнее о методе главных компонент см. [9,10].
25. Показатели качества регрессии: коэффициент детерминации как мерило качества спецификации эконометрической модели.
Смысл коэффициента детерминации обсудим, не теряя общности, на примере линейной модели парной регрессии (8.1'). Пусть имеется оцененная МНК линейная модель парной регрессии. Пусть имеется оцененная МНК линейная модель парной регрессии,
у= ά0 + ά1 Х+ U .
(S ά0) (S ά1) (бu)
Предполагается, что МНК-оценки ее параметров получены по обучающей выборке в ситуации, когда все предпосылки теоремы Гаусса — Маркова адекватны.
В уравнении обозначим символом
y = aQ + aix (12.2)
оценку функции регрессии в модели. Подчеркнем, что регрессор х полностью объясняет левую часть равенства — случайную переменную у. Следовательно, с учетом (12.2) и уравнений наблюдений (8.4) справедливы равенства:
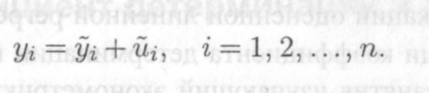 12.3
12.3
Здесь п — количество уравнений наблюдений (8.4), по которым и найдена МНК-оценка (12.1). Далее первое слагаемое в формуле (12.3) полностью объясняется в рамках данной модели регрессором х; напротив, второе слагаемое никак не объясняется этим регрессором. Поэтому ясно, что объясняющая способность х тем выше", чем большую долю в переменной у составляет первое слагаемое. Как измерить эту долю? Ведьу — переменная величина! Осуществить такую процедуру можно, если привлечь понятие дисперсии.
Согласно свойству (6.61) операции оценивания дисперсии по выборочным данным справедливо равенство
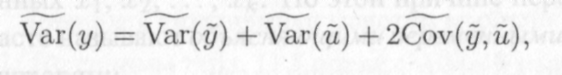 (12.4) где
(12.4) где
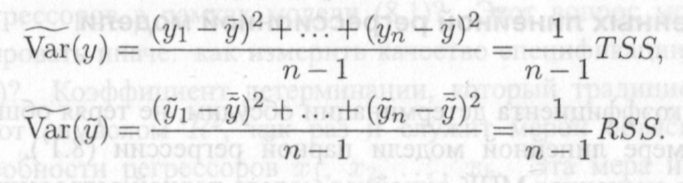 12.5
12.5

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
