

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
![]() 0 0,16+1 0,432+2 0,288+3 0,0,064=1,2
0 0,16+1 0,432+2 0,288+3 0,0,064=1,2
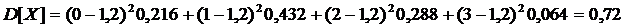
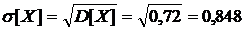
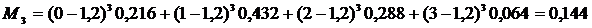
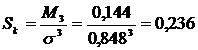
УПРАЖНЕНИЯ.
№ 1. Производится один опыт, в результате которого может появиться или не появиться событие А, вероятность которого равна Р. Рассматривается случайная величина X - число появления события А. Определить ее характеристики: математическое ожидание, дисперсию, среднее квадратичное отклонение (с. к.о.).
№ 2. Медсестра обслуживает 4 больных. Вероятность того, что в течение часа не потребует внимания медсестры первый больной равна 0,9, второй-0,8, третий - 0,75, четвертый - 0,7. Определить математическое ожидание, диспепсию и с. к.о. числа больных, которые не потребуют внимания медсестры в течение часа.
№ 3. В город N в течение недели прилетает по 1 самолету из трех различных городов и доставляют лекарственные препараты. Вероятность доставки необходимого лекарственного препарата каждым из указанных рейсов равна 0,35. Случайная величина X - число привозов необходимого препарата в течение недели. Определить характеристики величины X - математическое ожидание, дисперсию, с. к.о. и асимметрию.
ЗАНЯТИЕ № 4. ЗАКОНЫ РАСПРЕДЕЛЕНИЯ СЛУЧАЙНЫХ ВЕЛИЧИН.
§ 4.1. ОСНОВНЫЕ ЗАДАЧИ МАТЕМАТИЧЕСКОЙ СТАТИСТИКИ.
Математические законы теории вероятностей не являются беспредметными абстракциями, лишенными физического содержания. Они представляют собой математическое выражение реальных закономерностей фактически существующих в массовых случайных явлениях природы.
Каждое исследование случайных явлений, выполняемое методами теории вероятностей, прямо или косвенно опирается на экспериментальные данные. Оперируя такими понятиями как события и их вероятности, случайные величины, их законы распределения и числовые характеристики, теория вероятностей дает возможность теоретическим путем определить вероятность одних событий через вероятности других. Такие косвенные методы позволяют значительно экономить время и средства, затрачиваемые на эксперимент, но отнюдь не исключают самого эксперимента. Каждое исследование в области случайных явлений, как бы отвлеченно оно ни было, своими корнями уходит в эксперимент.
Целью каждой науки является, в конечном счете, познание некоторых общих закономерностей, позволяющих предвидеть течение явлений и выбирать рациональные пути поведения в типичных ситуациях. Об этом хорошо выразился , сказав, что у науки есть лишь две главные конечные цели - предвидение и польза.
Первые работы по математической статистике начались в 18 веке, они были связаны со статистикой народонаселения и с вопросами страхования. В конце 18 века началась серьезная работа по теории ошибок измерений, приведшая в начале 19 века к созданию далеко продвинувших ее основ. Биологические исследования послужили в 19 веке толчком для постановки многочисленных вопросов, приведших в начале 20-го столетия к выделению математической статистики в особую науку, в становлении которой активное участие принимали видные зарубежные ученые (Б. Паскаль, Ферма, Х. Гюйгенс, Я. Бернулли, К. Гаусс и др.) и наши соотечественники (, , и др.) Сейчас математическая статистика уже не та, что была 50-60 лет назад, и ее прогресс не прекращается.
Хотелось бы обратить особое внимание на следующий момент, о котором писал А. Бредфорд Хилл в предисловии к своей книге "Основы медицинской статистики" (М. Медгиз.-1958.-с.9): "Статистика представляет собой один из немногих примеров, в которых употребление математических методов или злоупотребление ими может вызвать сильную эмоциональную реакцию в нематематических умах. Это объясняется тем, что статистики при разрешении исследуемых ими проблем пользуются непонятными врачам приемами исследования. Досадно, если изучая проблему методами, освоение которых потребовало много труда, мы узнаем, что наши заключения ставит под сомнение или даже отвергает кто-либо, кто не может самостоятельно воспроизвести наши наблюдения. Для того, чтобы признать, что вина лежит в нас самих требуется больше хладнокровия, чем у нас есть". Из изложенного выше следует, что к математической статистике необходимо подходить серьезно и с соответствующей подготовкой, поскольку она разрабатывает методы, позволяющие по результатам испытаний делать определенные выводы. Таким образом, разработка методов регистрации, описания и анализ экспериментальных данных, полученных в результате наблюдения массовых случайных явлений, составляет предмет специальной науки, называемой математической статистикой.
Все задачи математической статистики касаются вопросов обработки наблюдений над массовыми случайными явлениями, но в зависимости от характера решаемого практического вопроса. Типичными практическими задачами математической статистики являются:
1.Определение закона распределения случайной величины (или системы
случайных величин) по статистическим данным.
2.Проверка правдоподобия гипотез.
3.Нахождение неизвестных параметров распределения.
§ 4.2. ГЕНЕРАЛЬНАЯ СОВОКУПНОСТЬ И ВЫБОРКА.
В теории вероятностей и математической статистке при рассмотрении вопроса о статистических аналогиях для характеристики случайных величин часто используется вместо понятия "статистическое среднее" термин "выборочное среднее", а статистическая дисперсия именуется выборочной дисперсией и т. д. Происхождение этих терминов следующее. В статистке, особенно в медицинской и биологической, часто приходится исследовать распределение того или иного признака для весьма большой совокупности индивидуумов, образующих статистический коллектив. Таким признаком может быть, например, содержание эритроцитов в крови, систолическое и диастолическое давление крови, вес или размер какого-либо органа и т. д. Данный признак является случайной величиной, значение которой от индивидуума к индивидууму меняется. Однако, для того, чтобы составить представление о распределении этой случайной величины или о ее основных характеристиках, нет необходимости обследовать каждый индивидуум данной обширной совокупности (множества), а можно обследовать некоторую выборку (подмножество) достаточно большого объема для того, чтобы в ней были выделены существенные признаки (черты) изучаемого распределения. Та обширная совокупность элементов, из которой производится выборка, в математической статистике носит название генеральной совокупности. При этом предполагается, что число элементов (индивидуумов) N в генеральной совокупности весьма велико, а число элементов п в выборке ограничено. При достаточно большом N оказывается, что свойства выборочных (статистических) распределений и характеристик практически не зависит от N. Отсюда, естественно, вытекает математическая идеализация, состоящая в том, что генеральная совокупность, из которой сделана выборка, имеет бесконечный объем. При этом отличают точные характеристики (закон распределения), математическое ожидание, дисперсию, стандартное отклонение, относящиеся к генеральной совокупности от аналогичных им "выборочных" характеристик. Выборочные характеристики отличаются от соответствующих характеристик генеральной совокупности за счет ограниченного объема выборки п. При неограниченном увеличении п естественно, все выборочные характеристики приближаются (сходятся по вероятности) к соответствующим характеристикам генеральной совокупности.
Из изложенного ясно, что выборка с определенной степенью точности характеризует генеральную совокупность.
§ 4.3. РЯДЫ РАСПРЕДЕЛЕНИЯ.
Предположим, что изучается некоторая случайная величина X, закон распределения которой в точности неизвестен, и требуется определить этот закон из опыта или проверить экспериментально гипотезу о том, что величина X подчиняется тому или иному закону. С этой целью над случайной величиной X производится ряд независимых опытов. В каждом из этих опытов случайная величина X принимает определенное значение. Совокупность наблюдаемых значений величины и представляет собой первичный статистический материал, подлежащий обработке, осмыслению и научному анализу. Такая совокупность называется простой статистической совокупностью или простым статистическим рядом. Обычно простой статистический ряд оформляется в виде таблицы, в первом столбце которой стоит номер опыта, и во втором - наблюдаемое значение случайное величины X (таблица 1). Простой статистический ряд представляет собой первичную форму записи статистического материала и может быть обработана различными способами.
Таблица 4.1
№ п/п | 1 | 2 | … | N |
хi | x1 | x2 | … | xn |
Случайная величина будет полностью описана с вероятностной точки зрения, если мы в точности укажем, какой вероятностью обладает каждое из событий. Этим мы установим так называемый закон распределения случайной величины. Всякое соотношение, устанавливающее связь между возможными значениями случайной величины и соответствующими им вероятностями, называют законом распределения случайной величины. Простейшей формой задания этого закона является таблица, в которой перечислены возможные значения случайной величины и соответствующие им вероятности (таблица 2):
Таблица 4.2
xi | x1 | x2 | … | xn |
Pi | P1 | P2 | … | Pn |
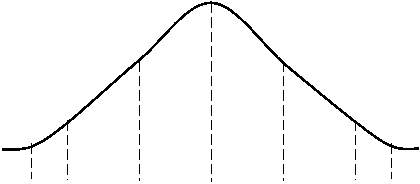
![]() Такую таблицу называют рядом распределения случайной величины X. Чтобы придать ряду распределения более наглядный вид, часто используют графическое изображение. При этом по оси абсцисс откладывают возможные значения случайной величины, а по оси ординат - вероятность этих значений. Полученные точки соединяют отрезками прямых.
Такую таблицу называют рядом распределения случайной величины X. Чтобы придать ряду распределения более наглядный вид, часто используют графическое изображение. При этом по оси абсцисс откладывают возможные значения случайной величины, а по оси ординат - вероятность этих значений. Полученные точки соединяют отрезками прямых.
![]() pi
pi
 |
 p1 p2 p3 p4 p5 p6 p7
p1 p2 p3 p4 p5 p6 p7
![]() xi x2 x3 x4 x5 x6 x7 xi
xi x2 x3 x4 x5 x6 x7 xi
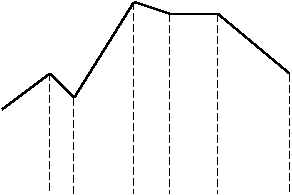
Рис. 4.1. Многоугольник распределения.
Такая фигура называется многоугольником распределения или полигоном (рис.4.1). Многоугольник распределения, также как и ряд распределения, полностью характеризует случайную величину, и является одной из форм закона распределения. При большом числе наблюдений (порядка сотен) простой статистический ряд перестает быть удобной формой записи статистического материала и становится громоздким и мало наглядным. Для придания ему большей компактности и наглядности статистический материал подвергается дополнительной обработке и строится статистический ряд.
Предположим, что результаты наблюдений над непрерывной случайной величиной X, оформлены в виде простого статистического ряда. Разделим весь диапазон полученных значений случайной величины Х на интервалы или разряды, число которых определяется выражением:
![]() (4.1)
(4.1)
де п - число полных испытаний (или измерений).
Ширина или шаг ![]() , каждого интервала определяется соотношением:
, каждого интервала определяется соотношением:
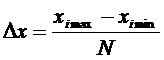 (4.2)
(4.2)
где ![]() и
и ![]() - границы всего диапазона случайной величины Х.
- границы всего диапазона случайной величины Х.
Допустим что ![]() =
=![]() , тогда
, тогда
![]()
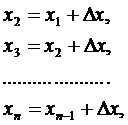 (4.3)
(4.3)
Следовательно, границы каждого интервала (разряда) находятся как
![]() (4.4)
(4.4)
Среднее значение случайной величины в каждом интервале (разряде) будет определяться выражением:
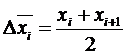 (4.5)
(4.5)
Подсчитаем количество значений ![]() , приходящихся на каждый
, приходящихся на каждый ![]() разряд. Это число разделим на общее число наблюдений (измерений) и найдем статистическую вероятность, соответствующую данному разряду:
разряд. Это число разделим на общее число наблюдений (измерений) и найдем статистическую вероятность, соответствующую данному разряду:
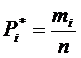 (4.6)
(4.6)
Сумма статистической вероятности всех разрядов, очевидно, должна быть равна единице. Построим таблицу, в которой приведены разряды в порядке их расположения вдоль оси абсцисс и соответствующие им частоты. Эта таблица называется статистическим рядом.
Таблица 4.3
|
|
| … |
|
|
|
| … |
|
![]()
![]()
 |
![]()

![]()
![]() x
x
Рис. 4.2. Гистограмма случайной величины х.
Поскольку случайные величины в нем расположены по возрастающей линии, то такой ряд часто называют статистическим ранжированным рядом. Для большей наглядности статистический ряд часто оформляется в виде так называемой гистограммы (Рис. 4.2). Гистограмма строится следующим образом. По оси абсцисс откладываются разряды, и на каждом основании строится прямоугольник, площадь которого равна частоте данного разряда. Для построения гистограммы нужно частоту (статистическую вероятность) каждого разряда разделить на его длину и полученное число взять в качестве высоты прямоугольника. В случае равных по длине разрядов высота прямоугольников пропорциональна соответствующим частотам. Из способа построения гистограммы следует, что полная ее площадь равна единице.
§ 4.4. ЗАКОН НОРМАЛЬНОГО РАСПРЕДЕЛЕНИЯ
(ЗАКОН ГАУССА)
Закон нормального распределения, часто называемый законом Гаусса, имеет весьма важное значение в теории вероятностей и в математической статистике и занимает среди других законов распределения особое положение. Главная особенность закона Гаусса состоит в том, что этот закон распределения наиболее часто встречается на практике; и в том, что он является предельным законом, к которому приближаются другие законы распределения при весьма часто встречающихся типичных условиях. Нормальный закон распределения характеризуется плотностью вероятности вида:
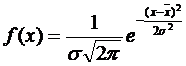 (4.7)
(4.7)
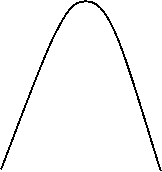
Кривая распределения по закону Гаусса имеет симметричный холмообразный вид (Рис 4.3). Максимальная ордината 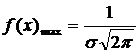 соответствует точке х =
соответствует точке х = ![]() .
.
f(x)
 |


![]()
 |
![]()
![]()

![]() x
x
Рис. 4.3 Плотность распределения по закону Гаусса
По мере удаления от указанной точки плотность распределения при ![]() асимптотически приближается к оси абсцисс.
асимптотически приближается к оси абсцисс.
Выясним смысл числовых характеристик ![]() и
и ![]() , входящих в уравнение (4.7). Докажем, что в указанном уравнении величина
, входящих в уравнение (4.7). Докажем, что в указанном уравнении величина ![]() есть математическое ожидание, а величина а - среднее квадратичное отклонение случайной величины X.
есть математическое ожидание, а величина а - среднее квадратичное отклонение случайной величины X.
Используя выражение (4.7) можно записать:
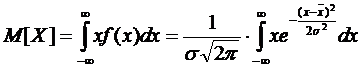 (4.8)
(4.8)
Введем новую переменную
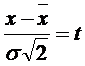 (4.9)
(4.9)
получим:
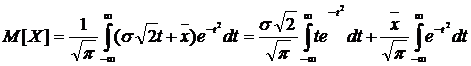 (4.10)
(4.10)
Нетрудно убедиться, что первый интеграл в уравнении (10) равен нулю, а второй представляет собой интеграл Эйлера-Пуассона:
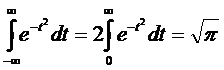 (4.11)
(4.11)
Следовательно, М[Х] = ![]() , т. е. величина
, т. е. величина ![]() представляет собой математическое ожидание случайной величины X. Величина дисперсии случайной величины X определяется выражением:
представляет собой математическое ожидание случайной величины X. Величина дисперсии случайной величины X определяется выражением:
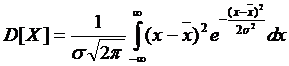 (4.12)
(4.12)
Введем новую переменную (4.9), получим:
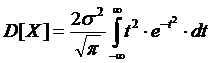 (4.13)
(4.13)
Интегрируя по частям, придем к результату:
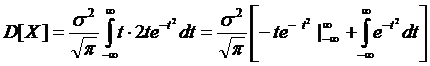 (4.14)
(4.14)
Первое слагаемое в уравнении (4.14), находящееся в квадратных скобках, равно нулю, т. к. ![]() при t
при t 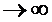 убывает быстрее, чем возрастает любая степень t. Второе слагаемое, как это следует из выражения (4.11), равно
убывает быстрее, чем возрастает любая степень t. Второе слагаемое, как это следует из выражения (4.11), равно ![]() , таким образом, из уравнения (4.14) следует, что
, таким образом, из уравнения (4.14) следует, что
D[X] = ![]() (4.15)
(4.15)
Следовательно, параметр ![]() в формуле (4.7) является средним квадратичным отклонением случайной величины X.
в формуле (4.7) является средним квадратичным отклонением случайной величины X.
Параметр ![]() характеризует форму кривой распределения. Так как площадь кривой распределения всегда должна оставаться равной единице, то при увеличении
характеризует форму кривой распределения. Так как площадь кривой распределения всегда должна оставаться равной единице, то при увеличении ![]() кривая распределения становится более плоской, растягиваясь вдоль оси абсцисс (рис. 4.3)
кривая распределения становится более плоской, растягиваясь вдоль оси абсцисс (рис. 4.3)
Из выражения (4.7) видно, что центром симметрии распределения является центр рассеивания ![]() . Это ясно из того, что при изменении знака разности (х -
. Это ясно из того, что при изменении знака разности (х -![]() ) на обратный выражение (4.7) не меняется. Если изменять центр рассеивания
) на обратный выражение (4.7) не меняется. Если изменять центр рассеивания ![]() , то кривая распределения будет смещаться вдоль оси абсцисс, не изменяя своей формы. Центр рассеивания характеризует положение распределения на оси абсцисс. Размерность центра рассеивания и параметра
, то кривая распределения будет смещаться вдоль оси абсцисс, не изменяя своей формы. Центр рассеивания характеризует положение распределения на оси абсцисс. Размерность центра рассеивания и параметра ![]() совпадает с размерностью случайной величины X.
совпадает с размерностью случайной величины X.
Для нормального закона в качестве характеристики рассеивания иногда вместо среднего квадратичного отклонения используется мера точности. Мерой точности называется величина, обратно пропорциональная ![]() :
:
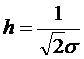 (4.16)
(4.16)
Используя меру точности h, закон нормального распределения можно записать в виде:
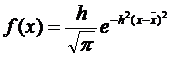 (4.17)
(4.17)
Размерность меры точность обратна размерности случайной величины.
Используя уравнение (4.7), интегральную функцию распределения случайной величины Х можно представить в виде:
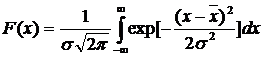 (4.18)
(4.18)
Интеграл (4.18) не может быть выражен через элементарные функции.
Используя интегральную функцию Лапласа
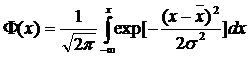 (4.19)
(4.19)
выражение (4.18) можно привести к виду:
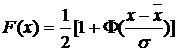 (4.20)
(4.20)
Интегральная функция Лапласа нечетная: ![]()
Вероятность, что полученная в измерениях величина х попадает в интервал (a,b) на основании формул (4.18-4.20) равна
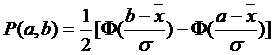 (4.21)
(4.21)
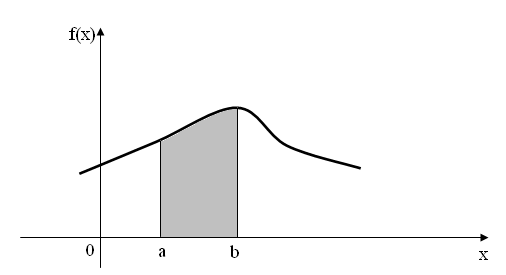
Рис. 4.4
Геометрически выражение (4.21) отражает тот факт, что вероятность того, что непрерывная случайная величина принимает значения, принадлежащие интервалу (а, b), равна площади криволинейной трапеции ограниченной осью Ох, кривой распределения f(x) и прямыми х=а, х=b. (Рис.4.4). Согласно (4.21), доверительная вероятность того, что случайная величина Х попадает в интервал (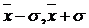 ), будет равна:
), будет равна:
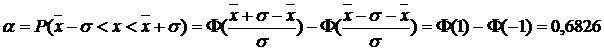 или
или 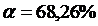 . Функция
. Функция  , а в данном случае
, а в данном случае ![]() определяется по таблице |11|.
определяется по таблице |11|.
![]() f(x)
f(x)
 |

![]() -3
-3![]()
![]()
![]()
![]()
![]()
![]()
![]() x
x
Рис. 4.5 «Правила 3 ![]() ».
».
Аналогичный расчет показывает, что вероятность нахождения случайной величины в интервале (![]() ) равна 0,9544 или
) равна 0,9544 или ![]() =95,44%, соответственно в интервале
=95,44%, соответственно в интервале ![]() вероятность равна 0,9972 или
вероятность равна 0,9972 или ![]() =99,72%. Анализ показывает, что случайная величина, распределенная по нормальному закону, практически не отклоняется от центра распределения более чем З
=99,72%. Анализ показывает, что случайная величина, распределенная по нормальному закону, практически не отклоняется от центра распределения более чем З![]() , поскольку вероятность нахождения ее в интервале значений (
, поскольку вероятность нахождения ее в интервале значений (![]() ± 3
± 3![]() ) равно 0,9972=1, т. е. нахождение случайной величины в указанном интервале есть практически достоверное событие. Таким образом, если случайная величина распределена по нормальному закону, то отклонение этой величины от среднего значения по абсолютной величине не превосходит утроенного среднего квадратичного отклонения. Это утверждение известно в статистике как "правило З
) равно 0,9972=1, т. е. нахождение случайной величины в указанном интервале есть практически достоверное событие. Таким образом, если случайная величина распределена по нормальному закону, то отклонение этой величины от среднего значения по абсолютной величине не превосходит утроенного среднего квадратичного отклонения. Это утверждение известно в статистике как "правило З![]() " (Рис.4.5)
" (Рис.4.5)
Для определения функции Лапласа предлагает следующее
приближенное уравнение:
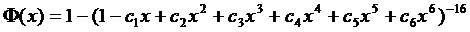 (4.22)
(4.22)
где
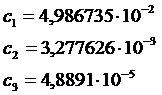
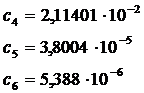
Используя ЭВМ в режиме непосредственного исполнения, можно быстро вычислить значение функции ![]()
§ 4.5 РАСПРЕДЕЛЕНИЕ СТЬЮДЕНТА.
f(x)
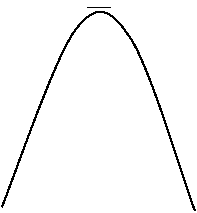 |
![]() PГ
PГ
 |
PC(n=10)
 |

![]() PC(n=2)
PC(n=2)

![]()
![]()
![]()
![]()
![]()

![]()
![]() 3 4 t
3 4 t

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
