

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Пример. Определить доверительный интервал для коэффициента корреляции r=0.80 при объеме выборки N=55. .
Приняв 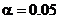 , находим (прил., табл.6), что r=0.80 соответствует величина z=1.099. При имеющемся числе данных:
, находим (прил., табл.6), что r=0.80 соответствует величина z=1.099. При имеющемся числе данных: 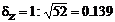 ,
, ![]() ;
; ![]() . По полученным значениям z1 и z2 находим граничные значения коэффициента корреляции.
. По полученным значениям z1 и z2 находим граничные значения коэффициента корреляции.
Величину можно использовать для проверки существенности различия двух выборочных коэффициентов корреляции. Ошибка разности
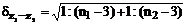 , (5.8)
, (5.8)
где n1 и n2 - объемы выборок, для которых вычислены значения r1 и r2. Если величина ![]() больше
больше ![]() , то с вероятностью
, то с вероятностью ![]() можно утверждать, что различие между r1 и r2 значимое.
можно утверждать, что различие между r1 и r2 значимое.
Пример. В результате статистической обработки данных по содержаниям меди и никеля в двух типах руд (сливных и вкрапленных) получены коэффициенты корреляции 0,75 и 0,60). Количество проб сливных руд 28, вкрапленных 53. Существенно ли различаются руды по тесноте связи между элементами медь - никель?
Для r1=0,75 (прил. 2, табл. 13), z1=0.973;
для r2=0,60, z2=0,693.
Основная ошибка: ![]() ;
; 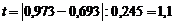 .
.
Табличное значение ![]() . Поскольку рассчитанное значение tэмп<t0,05, то можно считать, что по тесноте связи между содержаниями меди и никеля изучаемые руды не различаются (нет основания говорить о различии на основе имеющихся данных).
. Поскольку рассчитанное значение tэмп<t0,05, то можно считать, что по тесноте связи между содержаниями меди и никеля изучаемые руды не различаются (нет основания говорить о различии на основе имеющихся данных).
5.5 Статистики связи для порядковых и качественных признаков
В геологической практике встречается немало задач, в которых необходимо оценить тесноту зависимости между признаками, измеренных в порядковой или сравнительной качественной шкале измерений. Например, содержания элементов в пробах, проанализированных полуколичественным спектральным анализом, соотношение минералов в описании шлифа, интенсивность вторичных изменений пород в описании обнажений. Такие задачи могут решаться с помощью коэффициента корреляции рангов (r), либо коэффициента сопряженности (К).
5.5.1. Коэффициент корреляции рангов
Если пронумеровать объекты, упорядоченные по какому-то признаку, то такая совокупность будет называться ранжированной.
Пример. В результате осмотра шести образцов пород получены следующие значения содержаний минерала А: мало, нет, очень мало, очень много, много. Расположив их в порядке возрастания и пронумеровав, получим ранжированную совокупность:
содержания: нет; очень мало; мало; много; очень много.
ранг:
Если среди значений есть несколько одинаковых, то их располагают друг за другом, присваивают ранг, соответствующий положению каждого из них, находят среднеарифметическое значение рангов для группы одинаковых значений и затем присваивают этот вычисленный, так называемый, «исправленный» ранг каждому из этой группы одинаковых значений.
Например, для следующей совокупности данных:
значение: нет; нет; нет; очень мало; мало; мало; много; много; очень много
ранг: 10
будем иметь следующие исправленные ранги:
значение: нет очень мало мало много очень много
ранг: 2 4 6,5 8,5 10
Теснота связи для качественных признаков определяется коэффициентом корреляции рангов по следующей формуле:
![]()
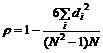 (5.9)
(5.9)
где d - разность между рангом признака X и рангом
соответствующего ему значения признака Y;
N - объем совокупности (число пар значений Xi, Yi).
Коэффициент корреляции рангов является показателем линейной связи и, также как и линейный коэффициент корреляции изменяется от -1 до +1. При значениях r близких к 0 линейная связь между признаками отсутствует, а при значениях r близких к ±1 - связь между признаками тесная, приближается к функциональной. Положительные значения r характеризуют прямую зависимость между парой признаков, отрицательные ¾ обратную.
Пример. В таблице приведены содержания свинца и цинка в десяти пробах руды по данным полуколичественного спектрального анализа. Определить тесноту связи между содержаниями изучаемых элементов.
Содержания элементов | Ранг | Исправленный ранг | Разность рангов | ||||
Pb | Zn | RPb | RZn | RPb | RZn | d | d2 |
- | сл | 1 | 3 | 1,5 | 4 | 2,5 | 6,25 |
0,001 | <0,001 | 9 | 6 | 9,5 | 7 | 2,5 | 6,25 |
сл | сл | 3 | 4 | 4 | 4 | 0 | 0 |
<0,001 | <0,001 | 6 | 7 | 7 | 7 | 0 | 0 |
- | - | 2 | 1 | 1,5 | 1,5 | 0 | 0 |
сл | - | 4 | 2 | 4 | 1,5 | 2,5 | 6,25 |
<0,001 | <0,001 | 7 | 8 | 7 | 7 | 0 | 0 |
0,001 | 0,001 | 10 | 9 | 9,5 | 9,5 | 0 | 0 |
сл | сл | 5 | 5 | 4 | 4 | 0 | 0 |
<0,001 | 0,001 | 8 | 10 | 7 | 9,5 | 2,5 | 6,25 |
Сумма | 25,0 |
Примечание: значение «-» означает, что содержание элемента не обнаружено, а значение «сл» означает, что содержание элемента на пределе чувствительности анализа.
Ранжируя исходные данные (колонки 1,2), определяем ранг (колонки 3,4), рассчитываем исправленный ранг (колонки 5,6), разности и квадраты разностей исправленных рангов (колонки 7,8).
По результатам последней колонки рассчитываем сумму квадратов и подставляем ее в расчетную формулу рангового коэффициента корреляции:
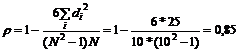
Оценка значимости коэффициента ранговой корреляции проводится аналогично оценке парного коэффициента корреляции при числе степеней свободы f=N-1. Для данного примера, приняв уровень значимости a=0,05, рассчитываем вначале ошибку рангового коэффициента корреляции:
![]()
а затем эмпирическое значение t-критерия:
![]()
Табличное значение t-критерия равно 2,26. Поскольку рассчитанное значение t-критерия больше табличного, то связь между содержаниями свинца и цинка в рудах значимая, линейная, тесная. Естественно, что при реальной обработке данных число проб должно быть больше 20 значений.
6 РЕГРЕССИОННЫЙ АНАЛИЗ
6.1 Основные понятия и задачи.
Изучение тесноты связи переменных выполняется с помощью корреляционного анализа. Коэффициент корреляции и корреляционное отношение позволяют установить характер и тесноту связи между случайными переменными. Однако если перед исследователем стоит задача не только зафиксировать наличие взаимосвязи, но и использовать этот факт для предсказания одной переменной на основании значений другой, необходимо использовать регрессионный анализ. Не менее важно для исследователя математическое описание выявленной зависимости, дающее возможность численно оценивать одни параметры через другие. Например, содержание дорого определяемых платиноидов можно определить по содержаниям меди, никеля, кобальта, серы. Перед проведением регрессионного анализа необходимо обязательно изучить взаимосвязи между интересующими нас переменными с помощью корреляционного анализа и диаграмм рассеивания. Корреляционный анализ определит переменные, связанные значимыми связями, а диаграмма рассеивания поможет определить характер зависимости и наличие аномальных наблюдений ("выбросов"). Дело в том, что регрессионный анализ (как и корреляционный) очень чувствителен к наличию выбросов, которые могут исказить модель взаимосвязи переменных настолько сильно, что она станет просто бесполезной. Если некоторые пробы вызывают сомнение, то их можно заменить несмещенной и эффективной оценкой выборочного среднего, являющегося наилучшим предсказанием для дополнительных проб, которые могут быть извлечены из той же совокупности. Однако ясно, что среднее значение не может адекватно представлять все данные.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
