

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Проведение регрессионного анализа можно разделить на три этапа: выбор формы зависимости (типа уравнения); вычисление коэффициентов выбранного уравнения; оценка достоверности полученного уравнения. В данной разделе мы построим самую простую модель парной линейной регрессии — уравнение, связывающее одну зависимую переменную (Y) и одну независимую (X). Уравнением регрессии Y и Х называется уравнение вида у=f(х), устанавливающее зависимости между значениями независимой переменной Х и условными средними зависимой переменной Y. По виду различают линейные и нелинейные уравнения связи. Решению вопроса о форме связи и выборе типа уравнения должен предшествовать тщательный анализ показателей тесноты и характера связи, графика эмпирических зависимостей и физической сущности изучаемого явления.
6.2 Линейная регрессия.
Если коэффициент корреляции значим и близок к корреляционному отношению, а график эмпирической зависимости – к прямой линии, то зависимость между X и Y линейная и выражается уравнением
y=ax+b (6.1)
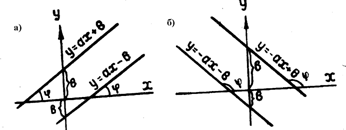 |
Из аналитической геометрии известно, что коэффициент при независимой переменной X есть тангенс угла наклона прямой к положительному направлению оси X, то есть a=tgφ. Коэффициент этот характеризует скорость изменения зависимой переменной Y при изменении переменной Х. Положение прямой при различных значениях коэффициентов показано ниже.
Рис. 6.1 Графики линейной зависимости.
Коэффициент b – начальная ордината, определяет значение Y при Х=0. Графически этот отрезок, отсекаемый прямой по осиY.
Известно, что среднее — это значение, относительно которого дисперсия и, следовательно, сумма квадратов отклонений, является наименьшей. Если рассуждать по аналогии со средним, то один из способов построения линии регрессии состоит в минимизации суммы квадратов отклонений от прямой. Мы можем построить единственную прямую, отклонения которой от исходных данных можно свести до минимума. Сущность метода наименьших квадратов состоит в том, что наилучшим считается то положение линии регрессии, при котором сумма квадратов отклонений эмпирических точек по ординатам от теоретических (расчетных) минимальна. Если значения этой линейной функции в данных точках вычесть из соответствующих наблюдаемых значений, то полученное в результате множество чисел будет иметь среднее значение, равное нулю, и меньшую дисперсию, чем набор отклонений от любой другой прямой, построенной по данным точкам. Этот метод и является одним из простых способов вычисления коэффициентов уравнения регрессии, и не только линейной.
Для простой линейной регрессии значения а и b определяются из системы двух нормальных уравнений (6.2):
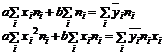 (6.2)
(6.2)
где суммирование ведется по всем исходным значениям независимой (xi) и зависимой переменной (yi). Предполагается, что для каждой точки линии регрессии существует нормальное распределение частот возможных значений зависимой переменной. Если эти ограничения выполнены, то метод наименьших квадратов дает оценки максимального правдоподобия для коэффициентов регрессии, а построенная нами линия регрессии будет ближе к истинной прямой регрессии, чем любая другая прямая. Можно определить три характеристики, которые описывают изменение зависимой переменной. Первая из них — это общая сумма квадратов (SST) зависимой переменной Y (6.3):
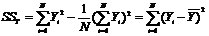 (6.3)
(6.3)
Вторая характеристика изменчивости зависимой переменной—это сумма квадратов отклонений оцененных значений (![]() ) от среднего значения (
) от среднего значения (![]() ). Она характеризует меру изменчивости линии регрессии относительно среднего значения (6.4):
). Она характеризует меру изменчивости линии регрессии относительно среднего значения (6.4):
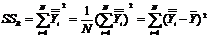 (6.4)
(6.4)
Как следует из правой части этого равенства, оценки имеют то же среднее значение, что и исходные данные. Если оцененные по регрессии значения совпадают по всем наблюдениям, то суммы SSR и SST будут одинаковыми. Наоборот, если сумма квадратов SSR будет меньше, то разность SSD=SST—SSR, называемая остаточной суммой квадратов, будет отличаться от нуля. Величину SSD можно вычислить также по формуле (6.5):
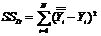 (6.5)
(6.5)
Она является мерой отклонения линии регрессии, построенной по методу наименьших квадратов, от результатов наблюдений. Качество приближения прямой характеризуется отношением:
![]() (6.6)
(6.6)
Если для имеющихся данных прямая линии регрессии хорошо отражает зависимость, то это отношение будет близко к 1. Квадратный корень из этой величины равен множественному коэффициенту корреляции. Нередко R2 выражают в процентах.
Пример. Рассчитать параметры для составления системы нормальных уравнений по данным первой и второй колонок таблицы:
xi | ni | xi ni | xi2 ni |
|
|
|
0,1 | 1 | ,01 | 0,01 | 1,1 | 1,1 | 0,11 |
0,2 | 2 | 0,4 | 0,08 | 1,7 | 3,4 | 0,68 |
0,3 | 3 | 0,9 | 0,27 | 2,4 | 7,2 | 2,16 |
0,4 | 3 | 1,2 | 0,48 | 2,6 | 7,8 | 3,12 |
0,5 | 3 | 1,5 | 0,75 | 4,1 | 12,3 | 6,15 |
0,6 | 2 | 1,2 | 0,72 | 4,6 | 9,2 | 5,52 |
0,7 | 1 | 0,7 | 0,49 | 5,5 | 5,5 | 3,85 |
Σ | 15 | 6,0 | 2,80 | 46,5 | 21,59 |
Согласно формуле (6.2) по полученным данным имеем систему уравнений:
6a + 15b = 46,5
2,8a + 6b = 7,70
Разделим каждое из уравнений на коэффициент при а:
а + 2,5b = 7,75
a + 2,14b = 7,7
Вычитая из первого уравнения второе, получим: 0,36b=0,05, откуда b=0,14. Подставляя значение b в первое уравнение получим а=7,75 – 2,5*0,14=7,40.
Таким образом, уравнение регрессии Y по X имеет вид: y=7,4х+0,14. По этому уравнению можно для каждого значения xi определить регрессионное (вероятное) значение ŷi и сравнить его с исходным значением зависимой переменной (групповой средней ![]() ):
):
xi | 0,1 | 0,2 | 0,3 | 0,4 | 0,5 | 0,6 | 0,7 |
| 1,1 | 1,7 | 2,4 | 2,6 | 4,1 | 4,6 | 5,5 |
| 0,9 | 1,6 | 2,4 | 3,1 | 3,8 | 4,6 | 5,3 |
Как видно, теоретические значения ŷi близки эмпирическим. Аналогично решаются системы линейных уравнений с любым числом неизвестных, но объем вычислительной работы при этом возрастает. Если систему (6.2) решить в общем виде и найденные значения подставить в уравнение прямой (6.1), то оно приведется к виду:

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
