

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Особое место занимала процедура объяснения детям правил эксперимента. Рассматривание картинок и ответы на вопросы подавались как игра, где ребенок должен отвечать на вопросы определенным образом. Для некоторых детей 4 лет иногда было проблематично различить понятия «вчера» и «сегодня», так как к этому моменту эти понятия не были достаточно сформированы, либо дети не освоили из вербальное выражение. Интересны также случаи, когда дети воспринимали подаваемые глаголы буквально (как это часто бывает) и, к примеру, отказывались говорить про себя утвердительно. На вопрос экспериментатора «А ты что делаешь?» ребенок мог ответить негативно: «Я не хохотаю» и проч.
Во время проведения теста осуществлялась запись на диктофон. Обработка результатов производилась при помощи таблиц Excel. Результаты по каждому тесту хранятся двух таблицах, каждая из которых содержит расшифровку записи тестирования. Всего в анализе было использовано 120 таблиц по информантам, а также вспомогательные таблицы для подсчета результатов.
2.3. Качественный анализ результатов в сочетании с дисперсионным анализом.
2.3.1. Анализ общих результатов.
Для выявления значимости в процентах общего числа правильных распознаваний основ была проведена статистическая обработка данных методом дисперсионного анализа (ANOVA)[5], выполненная с помощью статистической программы SPSS. Данные были обработаны многофакторным анализом методом ANOVA, с возрастной группой и возрастом в качестве независимых факторов, варьирующих между информантами (between subjects factors) и вариантом в качестве независимого фактора с повторными измерениями (within subjects factors). В качестве переменной выступал общий процент правильных распознаваний основ в каждом тесте.
Ставились следующие задачи:
1. Выявить разницу в образовании правильных форм в зависимости от теста.
2. Выявить возможную зависимость результатов от пола, возраста или от пола и возраста в корреляции.
В первой части дисперсионного анализа зависимой переменной выступали средние значения правильного распознавания модели в обеих возрастных группах по двум тестам. Так как каждый из испытуемых выполнял два варианта теста, то анализ был проведен методом ANOVA с повторными измерениями (Repeated Measures Design ANOVA).
При описании были выявлены довольно высокие значения отклонений от среднего, достигающие Std. Deviation=15,8221. Это говорит о высокой разнице между максимальными и минимальными значениями внутри групп.
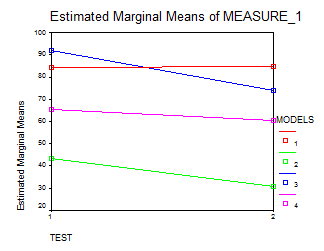
1. В результате, оказалось, что статистически значимый эффект оказывает вариант теста (Wilks’ Lambda = .519, p ≤ 0005). Это значит, что дети по-разному справлялись с тестом 2, где стимулы предъявлялись в форме инфинитива, и с тестом 1, где стимулы предъявлялись в форме прошедшего времени. Тест от прошедшего времени оказался сложнее, независимо от возраста и пола ребенка. Cоотношение факторов тест*возраст, тест*пол, а также тест*возраст*пол не является статистически значимым (test*age – Wilks' Lambda = 0,891, p = ,011, test*gender – Wilks’ Lambda = 0,945, p = ,076)
2. Количество правильно распознанных моделей в целом зависит от возраста (F(1,56)=35,2, р≤.0005). Дети 6 лет справились с заданием лучше (76,29% правильных ответов в тесте 1 и 70,6% в тесте 2 соответственно), чем 4-летние (66,14% правильных ответов в тесте 1, и 54,17% правильных ответов в тесте 2 соответственно). Эта разница является статистически значимой и прослеживается в обоих вариантах теста.
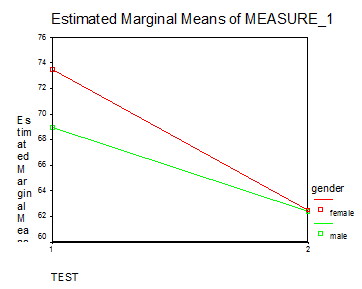
3. Результаты тестов не зависели от пола ребенка (F(1,56)=1,06, р=.307). Этот факт противоречит утверждениям Ульмана о разнице в образовании форм у испытуемых разного пола.
Рисунок 5. График средних значений правильных распознаваний в зависимости от варианта теста и возраста.
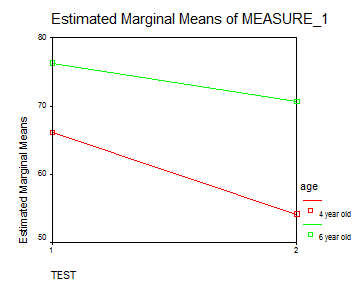
Рисунок 6. График средних значений распознавания в зависимости от варианта теста и пола.
2.3.2. Анализ результатов по распознаванию основ разных классов глаголов
В данном разделе будет проанализирован общий процент правильных распознаваний по каждому классу. Это позволит установить причины успешного распознавания тех или иных классов, выявить различия распознавания между классами, зависимость результатов от пола и возраста.
Основа глагола считается распознанной, если при ответе употребляется модель, соответствующая классу глагола-стимула. Поэтому максимальный процент при таком подсчете составляет 100% от всех ответов на стимулы данного класса. Если форма содержит ошибки в спряжении, ударении или чередовании, это не учитывается при оценке правильности выбора модели. Правильные формы будут рассмотрены ниже.
Односистемный подход Байби предсказывает, что классы должны распределиться в зависимости от частоты класса. Самый частотный класс должен распознаваться лучше всего. Двусистемный подход предполагает, что лучше всего будут образовываться «правильные» классы, но поскольку все эти классы являются правильным, так как их формы регулярно образуются, в рамках двусистемного подхода сложно утверждать что-либо о том, как должны распределиться русские глаголы.
Дисперсионный анализ был направлен на то, чтобы сравнить результаты по количеству правильных распознаваний моделей в зависимости от варианта теста, возраста и пола ребенка. Анализ выявил, что существует статистически значимое различие в ответах испытуемых в зависимости от модели (Wilks’ Lambda = 0,081, p < .0005). Произведенные апостериорно попарные сравнения показали, что эта разница является значимой между всеми моделями, кроме отношения ай-моель\и-модель, которое не является статистически значимым (p=,463), что говорит о том, что на стимулы ай-класса и и-класса дети давали ответы одинаково хорошо, и и-класс по правильности распознаваний вплотную приближается к дефолтному ай-классу.
Распознавание каждого класса также зависит от взаимодействия факторов возраст*модель (Wilks’ Lambda = 0,676, p < ,0005) и модель*тест (Wilks’ Lambda = 0,415, p < .0005). Это значит, что распознавание различных моделей зависит от возрастной группы и теста, как уже было показано в предыдущем дисперсионном анализе. Взаимодействие модели и пола оказалось незначимым (Wilks’ Lambda = 0,922, p= .219).
Рисунок 7. Графики средних значений.
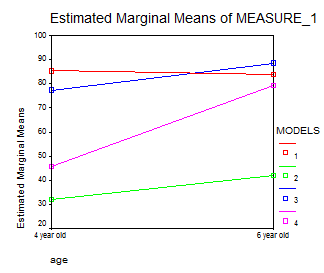
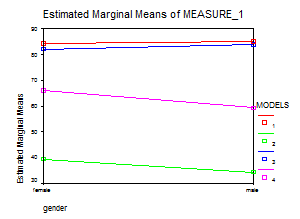
В диаграмме 1 представлены результаты по общему распознаванию классов. В тесте 1, где глаголы-стимулы предъявлялись в прошедшем времени[6], дети 4 и 6 лет лучше всего распознали ай-класс (84,75% и 84,83% правильно распознанных основ соответственно). Этот результат вполне совпадает с предыдущими исследованиями, показавшими, что ай-класс в силу частоты класса и простоты образования распознается лучше других классов. Кроме того, он формируется приблизительно к 4 годам, так как в этом возрасте уже распознается так же хорошо, как и в 6 лет. Другие классы, как более сложные, осваиваются несколько позже, и на практике получается, что у ребенка 4 лет не так велик выбор моделей, которые он может использовать. Поэтому вероятность частого использования ай-модели выше, чем частота использования других моделей.
На втором месте в тесте 1 стоит и-класс, который распознается особенно хорошо детьми 6 лет (ай-класс правильно распознан в 84,83% случаев, а и-класс – в 82,83%). Дети 4 лет распознали ай-класс заметно лучше и-класса (ай-класс в тесте 1 распознан в 85,43% случаев, и-класс - 65,09% соответственно).
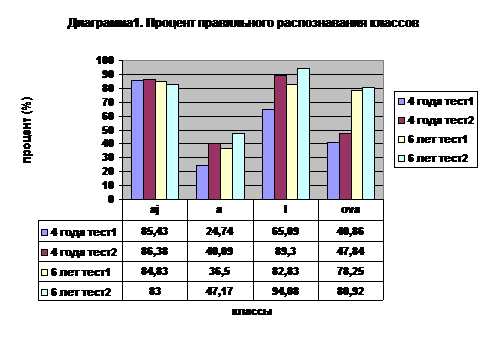
Интересно, что в тесте с инфинитивом частота правильного распознавания и-класса выше, чем частота правильного распознавания ай-класса. То есть в тесте 2 ай-класс стоит на втором месте по степени распознаваемости после и-класса. Если информанты 4 лет в тесте 2 распознали ай-класс и и-класс приблизительно одинаково хорошо (86,38% и 89,3% соответственно), то у информантов 6 лет степень распознавания ай-класса и и-класса отличается (83% и 94,08% соответственно), и-класс распознан заметно лучше. Средняя частота распознавания и-класса в тесте 2 выше, чем ай-класса. Это может быть вызвано тем, что и-класс имеет высокую частоту класса и заметный гласный –и - (который, однако, может вызвать ошибки при употреблении стимулов и-класса в ий-модели).
При этом необходимо помнить, что при подсчете распознанных основ не учитываются ошибки в чередовании и ошибки в спряжении. А подобные изменения могут радикально поменять облик слова, даже если модель сохранена. Процент же ошибок в спряжении, особенно в и-классе, весьма велик: около трети всех правильно распознанных основ у информантов 4 лет (в тесте 1 - 23,79% неправильных ответов, а в тесте 2 – 34,31%) и приблизительно одна пятая всех правильно распознанных основ у информантов 6 лет (подробнее ошибки в спряжении будут обсуждаться ниже)[7].
На третьем месте по степени распознаваемости в обоих тестах у детей 4 и 6 лет стоит ова-класс. Несмотря на то, что ова-класс имеет менее сложную парадигму спряжения, чем и-класс, и у него есть выполняющий роль маркера суффикс –ова-, общая частота правильного распознавания ова-класса ниже, чем и-класса. Это может быть связано с тем, что величина и-класса почти в 3 раза больше, чем величина ова-класса (в и-классе 7174 глаголов, а в ова-классе – 2815). Кроме того, в прошедшем времени и в инфинитиве ова-класс имеет гласный –а - в качестве конечного гласного основы, что делает его почти неотличимым от ай-класса, который, как известно, к 4 годам распознается весьма хорошо и активно используется для ответов на стимулы других классов.
Частота распознавания ова-класса не сильно различается в зависимости от варианта теста, но ощутимо разнится в зависимости от возраста. Если информанты 4 лет распознали 40,86% основ в тесте1 и 47,84% основ в тесте 2, то информанты 6 лет распознали 78,25% и 80,92% соответственно, то есть информанты 4 лет распознали почти в 2 раза меньше основ ова-класса, чем информанты 6 лет. Этот факт может свидетельствовать о том, что ова-класс в 4 года еще почти не сформирован. Кроме того, поскольку ай-класс и ова-класс, как уже было указано, очень похожи, сформировавшийся в более раннем возрасте ай-класс часто используется для образования реакций на стимулы ова-класса. Характерно, что у детей 4 лет в ответах на стимулы ова-класса сравнимое с ова-моделью место по числу употреблений занимает ай-модель: для ответа на стимулы ова-класса эта модель использована в 44,6% случаев в тесте 1 и 40,92% в тесте 2. Столь частое употребление ай-модели при ответах на стимулы ова-класса объясняется не только тем, что ова-класс находится только в процессе формирования в 4 года, но и тем, что ова-класс внешне похож на ай-класс, он тоже имеет основу на - а - и по аналогии соотносится с усвоенным ай-классом. Таким образом, на стадии освоения ова-класса и плохого его распознавания, ребенок использует следующую стратегию: берет основу на - ова - от прошедшего времени или от инфинитива и прибавляет - j-, а потом личные окончания. Это так называемая j-стратегия.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 12 13 |
