
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Главные компоненты ![]() представляют собой ортогональные линейные преобразования (т. е. некоррелированные случайные переменные) векторной случайной величины
представляют собой ортогональные линейные преобразования (т. е. некоррелированные случайные переменные) векторной случайной величины ![]() такие, что первая из них имеет наибольшую дисперсию, дисперсия убывает с ростом номера переменной, так что
такие, что первая из них имеет наибольшую дисперсию, дисперсия убывает с ростом номера переменной, так что ![]() я компонента имеет минимальную дисперсию. Сказанное можно записать в виде
я компонента имеет минимальную дисперсию. Сказанное можно записать в виде
![]() (3)
(3)
При некоторых предположениях относительно шкал можно показать, что дисперсии главных компонент являются собственными числами матрицы ![]() а коэффициенты при компонентах
а коэффициенты при компонентах ![]() в линейных преобразованиях являются компонентами соответствующих собственных векторов. В формуле (3)
в линейных преобразованиях являются компонентами соответствующих собственных векторов. В формуле (3) ![]() матрица собственных векторов ковариационной матрицы
матрица собственных векторов ковариационной матрицы ![]()
Анализ главных компонент направлен на сокращение числа переменных для анализа с использованием небольшого числа первых главных компонент и исключением линейных комбинаций (главных компонент) с минимальной дисперсией. В формуле (3) число компонент ![]() вектора
вектора ![]() меньше числа компонент вектора
меньше числа компонент вектора ![]() , т. е.
, т. е. ![]()
12.1. Главные компоненты совокупности
Пусть ![]() - первая главная компонента случайного вектора
- первая главная компонента случайного вектора ![]()
![]()
Ясно, что ![]() ,т. к.
,т. к. ![]() по условию решаемой задачи. Здесь
по условию решаемой задачи. Здесь ![]() -знак математического ожидания.
-знак математического ожидания.
![]() . (*)
. (*)
Вектор коэффициентов ![]() выбран таким образом, чтобы дисперсия
выбран таким образом, чтобы дисперсия ![]() имела максимальное значение при условии, что
имела максимальное значение при условии, что
![]() (1)
(1)
Таким образом мы приходим к проблеме максимизации при наличии ограничений, которая может быть решена с применением множителей Лагранжа. Тогда задача сводиться к нахождению вектора ![]() максимизирующего
максимизирующего
![]()
где ![]() множитель Лагранжа. Взяв производную по
множитель Лагранжа. Взяв производную по ![]() и приравняв ее к 0. получим уравнение
и приравняв ее к 0. получим уравнение
![]() (2)
(2)
где ![]() единичная матрица. Поскольку нас интересует только решение, когда
единичная матрица. Поскольку нас интересует только решение, когда ![]() должно удовлетворяться условие на определитель, а именно
должно удовлетворяться условие на определитель, а именно 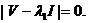
Следовательно, ![]() собственное число матрицы
собственное число матрицы ![]() а
а ![]() соответствующий собственный вектор.
соответствующий собственный вектор.
Выражение (2) может быть представлено в виде
![]() (3)
(3)
Умножая (3) слева на ![]() получаем
получаем
![]() (учитывая (1) (4)
(учитывая (1) (4)
Но левая часть равенства (4) есть ![]() (формула (*)). Поскольку решалась задача максимизации
(формула (*)). Поскольку решалась задача максимизации ![]() , следовательно,
, следовательно, ![]() есть максимальное собственное число матрицы
есть максимальное собственное число матрицы ![]()
Чтобы найти вторую главную компоненту 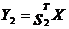 потребуем выполнения двух условий – условия нормировки:
потребуем выполнения двух условий – условия нормировки:
![]() (5)
(5)
и условия ортогональности:
![]() (6)
(6)
Вектор ![]() определяется теперь так, чтобы
определяется теперь так, чтобы ![]() была максимальна при выполнении двух указанных условий. Эта задача требует использования двух множителей Лагранжа
была максимальна при выполнении двух указанных условий. Эта задача требует использования двух множителей Лагранжа ![]() и
и ![]() Мы должны максимизировать выражение
Мы должны максимизировать выражение
![]()
![]() (7)
(7)
Взяв производную от (7) по ![]() и
и ![]() и приравняв их к 0, находим в соответствии с условием ортогональности (6), что
и приравняв их к 0, находим в соответствии с условием ортогональности (6), что ![]() А в силу условия нормировки (5) получаем, что
А в силу условия нормировки (5) получаем, что ![]() есть второе по величине собственное число матрицы
есть второе по величине собственное число матрицы ![]()
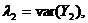 а
а ![]() соответствующий собственный вектор.
соответствующий собственный вектор.
Процесс повторяется до тех пор, пока все собственные числа и собственные векторы не окажутся дисперсиями и коэффициентами линейных комбинаций главных компонент. Чтобы доказать этот результат для ![]() й главной компоненты, мы должны максимизировать
й главной компоненты, мы должны максимизировать ![]() с учетом
с учетом ![]() условий, включающих условие нормировки
условий, включающих условие нормировки 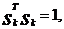 и
и ![]() условий ортогональности:
условий ортогональности: ![]()
![]()
К сожалению, свойства главных компонент зависят от шкал измерений исходных переменных, т. е. они не являются масштабно-инвариантными. Например, переход при измерении некоторого рамера от сантиметров к метрам или при измерении времени от часов к секундам приведет, вообще говоря, к другим собственным числам и векторам. По той причине, возможно, наиболее оптимальной будет работа со стандартизованными переменными
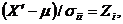
которые имеют нулевые средние значения и единичные дисперсии. В этом случае ковариационная матрица для ![]() будет корреляционной матрицей для
будет корреляционной матрицей для ![]() и будем ее обозначать как
и будем ее обозначать как ![]() В этом случае главные компоненты могут быть получены как собственные векторы матрицы
В этом случае главные компоненты могут быть получены как собственные векторы матрицы ![]() а их дисперсии – как соответствующие им ее собстенные числа.
а их дисперсии – как соответствующие им ее собстенные числа.
Поскольку по свойству собстенных чисел
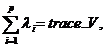
сумма собственныхх чисел может рассматриваться как полная дисперсия совокупности, а о первых ![]() главных компонентах с
главных компонентах с ![]() наибольшими дисперсиями можно сказать, что они учитывают долю полной дисперсии, определяющуюся как
наибольшими дисперсиями можно сказать, что они учитывают долю полной дисперсии, определяющуюся как ![]()

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
