
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
|
 |
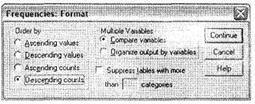
Для иллюстрации нашего примера выберем сортировку по численности возрастных групп по убыванию Descending counts и закроем диалоговое окно Format, щелкнув на кнопке Continue.
 |
|
После щелчка на кнопке ОК в главном диалоговом окне Frequencies откроется окно SPSS Viewer, в котором будут представлены частотные таблицы, а также другая информация, указанная нами на подготовительном этапе.
В таблице Statistics (рис. 2.5) отражаются общие параметры линейного распределения. Здесь представлены:
■ количество респондентов, ответивших на вопрос Возраст (строка Valid), — 1002 человека;
■ количество анкет, в которых на данный вопрос не было получено ответа (строка Missing), — 1 человек;
■ мода (строка Mode), то есть наиболее многочисленная возрастная группа респондентов (в нашем случае вариант 3: лица от 36 до 60 лет).
Следующая таблица, озаглавленная меткой анализируемой переменной (Возраст), отражает количество респондентов, которые указали тот или иной вариант ответа (столбец 2, Frequency), отсортированный по убыванию (рис. 2.6). Также в этой таблице представлен процент лиц, указавших данные варианты ответа от общего числа респондентов (столбец 3, Percent) и от числа ответивших на анализируемый вопрос Возраст (столбец 4, Valid Percent). Последний столбец 5 (Cumulative Percent)
отражает кумулятивные проценты (то есть вклад каждого варианта ответа в общую сумму). Так же как и в таблице Statistics, здесь указано общее количество ответивших (строка Valid Total) и не ответивших (строка Missing System) на данный вопрос, а также общее количество респондентов (строка Total, в нашем случае 1003).
|
N | Valid | 1002 |
Missing | 1 | |
Mode | 3 |
|
|
Frequency | Percent | Valid Percent | Cumulative Percent | ||||
Valid | 36-60 лет | 408 | 40,7 | 40,7 | 40,7 | ||
19-35 лет | 321 | 32,0 | 32,0 | 72,8 | |||
Старше 60 лет | 207 | 20,6 | 20,7 | 93,4 | |||
16-18 лет | 66 | 6,6 | 6,6 | 100,0 | |||
Total | 1002 | 99,9 | 100,0 | ||||
Missing | System | 1 | ,1 | ||||
Total |
| 1003 | 100,0 |
На подготовительном этапе анализа мы указали на необходимость построения сектограммы по рассматриваемой переменной. Она представлена в результатах линейных распределений после таблицы Возраст (рис. 2.7). Несмотря на то, что мы прямо указали SPSS вывести на диаграмме проценты каждой возрастной группы, программа проигнорировала это указание: в построенной сектограмме указаны только названия категорий.
 |
|
К сожалению, графическая подсистема SPSS весьма слаба и не выдерживает сравнения со средствами Microsoft Office. Поэтому рекомендуем пользоваться ею, только когда это действительно оправдано (например, в дисперсионном анализе). Во всех остальных случаях предпочтительнее копировать выводимые таблицы в Microsoft Excel и уже там строить по полученным данным диаграммы.
В рассматриваемом случае, чтобы исправить ситуацию и вывести проценты, дважды щелкните мышью по диаграмме Возраст в окне SPSS Viewer. Откроется специальное окно SPSS Chart Editor, предназначенное для редактирования простых диаграмм (simple charts)1. В нем выберите меню Chart ► Options. Откроется диалоговое окно Pie Options, в котором следует указать параметр Percents в области Labels (рис. 2.8). Далее щелкните на кнопке ОК и закройте окно SPSS Chart Editor. В окне SPSS Viewer к построенной диаграмме будут добавлены проценты каждой возрастной группы.
|
 |
Существует еще один способ построения диаграмм по линейным распределениям. Он применяется в случае, если вы уже построили частотную таблицу, но не указали на подготовительном этапе на необходимость вывести диаграмму. В такой ситуации следует дважды щелкнуть мышью на данной таблице в окне SPSS Viewer, a затем выделить тот ее столбец, по которому необходимо построить диаграмму. Например, выделите столбец Valid Percent (значения во всех четырех строках, обозначающих варианты ответа на вопрос Возраст). Затем щелкните правой кнопкой мыши и в открывшемся контекстном меню выберите пункт Create Graph ► Pie для построения сектограммы по долям каждой возрастной группы. В результате после частотной таблицы будет выведена соответствующая круговая диаграмма.
В разделе 1.2 было показано, как рассчитывается статистическая ошибка для величин, выраженных в процентах. Теперь, после того как мы изучили линейные распределения и основные описательные статистики, можно рассмотреть формулу для расчета статистической ошибки значений, выраженных в абсолютных величинах (например, средние значения). Напомним, что статистическая ошибка для данной категории величин рассчитывается для каждой из них в отдельности.
В качестве примера рассмотрим линейное распределение оценок на вопрос Оцените, пожалуйста, качество сухих строительных смесей марки X по пятибалльной шкале: от 1 (очень плохо) до 5 (отлично). При этом в диалоговом окне Statistics (см. рис. 2.2) необходимо выбрать параметры: Mean (среднее арифметическое) и Variance (дисперсия). После окончания расчетов в окне SPSS Viewer будет выведена следующая таблица (рис. 2.9).
|
N | Valid | 6762 |
Missing | 1406 | |
Mean | 3,89 | |
Variance | ,634 |
|
Формула для расчета статистической ошибки величин, выраженных в абсолютных показателях, имеет следующий вид:
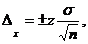
где z — статистическая константа для выбранного доверительного уровня (см. табл. 1.1); ![]() — дисперсия (строка Variance в таблице Statistics на рис. 2.9); n — размер выборки для данного вопроса (строка Valid в таблице Statistics на рис. 2.9).
— дисперсия (строка Variance в таблице Statistics на рис. 2.9); n — размер выборки для данного вопроса (строка Valid в таблице Statistics на рис. 2.9).
Таким образом, для нашего случая и стандартного для маркетинговых исследований доверительного уровня в 95 % статистическая ошибка выборки будет равна:
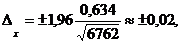
то есть средняя оценка качества ССС варьируется в пределах от 3,87 балла (3,89 --0,02) до 3,91 (3,89+ 0,02).
2.2. Линейные распределения
для многовариантных вопросов
Как было сказано выше (см. раздел 1.4.2), в SPSS все многовариантные вопросы рассматриваются как совокупность одновариантных переменных, обозначающий варианты ответа. Иными словами, многовариантный вопрос, содержащий три варианта ответа, в SPSS представляется как три дихотомические переменные, принимающие два значения-флага: отмечено/не отмечено.
Наиболее распространены два формата представления многовариантных переменных. В первом случае переменные, представляющие варианты ответа многовариантной переменной, принимают значение 1 (выбрано) или 0 (не выбрано); во втором случае — 1 (выбрано) или System Missing (не выбрано).
Как показывает опыт, первый способ предпочтительнее. Второй способ используется в специфических случаях (например, если необходимо использовать SPSS в качестве клиента автоматизации построения распределений при помощи программ на Sax Basic). Чтобы указать SPSS, какие переменные являются вариантами ответа для многовариантной переменной, наиболее часто используется описываемый далее способ, при котором после формирования многовариантной переменной ее можно использовать для построения линейных и перекрестных распределений.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
