
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Для формирования случайных выборок в диалоговом окне Select Cases, (см. рис. 1.15) предусмотрен параметр Random sample of cases. Выберите этот параметр и щелкните на кнопке Sample. Открывшееся диалоговое окно (рис. 1.17) содержит два способа формирования случайной выборки: с указанием доли респондентов, которых необходимо отобрать из исходной выборки (Approximately), либо с указанием конкретного количества респондентов, которое необходимо отобрать (Exactly). При этом в последнем случае необходимо также указать в поле from the first... cases количество респондентов, из которого следует осуществить выбор. Для формирования случайной выборки из общего числа опрошенных в данном поле следует указать совокупный размер выборки.
В нашем случае мы случайным образом отобрали 50 % респондентов из исходной выборки.
|
 |
1.5.2. Сортировка и группировка данных
Сортировка и группировка данных — наиболее часто применяющиеся операции с данными. Причем эти операции могут производиться как перед началом проведения статистического анализа, так и на других этапах работы.
1.5.2.1. Сортировка файла данных SPSS
При помощи функции сортировки в SPSS можно упорядочить значения переменных по одному или нескольким ключевым полям анкеты. Вызов диалогового окна сортировки осуществляется последовательностью меню Data ► Sort Cases.
|
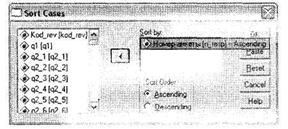 |
Как указано на рис. 1.18, левый список содержит все доступные в текущей базе данных переменные. В область Sort by помещаются переменные, по которым следует произвести сортировку. Порядок следования переменных в данной области соответствует порядку сортировки, то есть сначала сортировка происходит по первой переменной, затем — по второй и т. д. Группа переключателей Sort Order позволяет выбрать направление сортировки: по возрастанию (Ascending) или убыванию (Descending). При этом для каждой переменной можно выбрать свой тип сортировки.
В нашем случае мы отсортировали базу данных по возрастанию номера анкеты.
1.5.2.2. Группировка значений переменных
SPSS позволяет автоматически разделять значения интервальных переменных на заданное число групп. Разделение производится на основании процентилей, то есть образующиеся группы содержат примерно одинаковое количество значений. Результатом работы этой процедуры является новая порядковая переменная, которая содержит столько категорий, сколько было указано групп. Диалоговое окно группировки данных вызывается при помощи меню Transform ► Categorize Variables (рис. 1.19). В область Create Categories for переносятся переменные, значения которых необходимо сгруппировать. Поле Number of categories служит для указали числа групп.
|
 |
В нашем примере мы разделили выборку по номеру анкеты на четыре примерно равных доли — по 25 %.
1.5.3. Перекодирование переменных
Перекодирование переменных служит для трансформации значений переменных с созданием или без создания новых переменных, а также для автоматического кодирования текстовых переменных для преобразования их к числовому виду.
1.5.3.1. Перекодирование внутри одной переменной
Рекомендуется производить перекодирование значений многовариантных переменных (точнее, наборов дихотомий, как было показано в разделе 1.4.2) сразу после создания базы данных. При этом все пропущенные значения (вариант не отмечено) в таких вопросах следует перекодировать из System Missing в нули. В дальнейшем это позволит использовать данные дихотомические переменные (уже с двумя вариантами ответа: 0 и 1) при проведении статистического анализа (например, при построении перекрестных распределений). Альтернативой обработки многовариантных переменных является формирование серии полноценных одновариантных переменных путем кодирования всех возможных взаимодействий между вариантами ответа на многовариантный вопрос. Очевидно, что такая методика подходит только для вопросов с небольшим количеством вариантов ответа.
Перекодирование может осуществляться как внутри одной уже существующей переменной, так и с созданием новой переменной, содержащей перекодированные значения. В последнем случае исходная переменная будет содержать неперекодированные значения, а вновь созданная — перекодированные значения.
Рассмотрим методику перекодирования внутри одной существующей переменной (без создания новой). В качестве примера возьмем случай с многовариантным вопросом Где Вы обычно покупаете кетчуп?, у которого есть четыре варианта ответа:
1. q2_l — рынки;
2. q2_2 — магазины;
3. q2_3 — палатки;
4. q2_4 — другое.
При этом выбор респондентом данных пунктов закодирован в базе данных как 1, а отсутствие выбора — значением System Missing (отражается символом,). Произведем перекодирование отсутствующих значений System Missing в нули.
Вызов диалогового окна перекодировки внутри одной переменной осуществляется при помощи меню Transform ► Recode ► Into Same Variables. Открывшееся диалоговое окно, как и большинство других окон SPSS, в левой области содержит список всех доступных переменных, а в правой (имеющей метку Variables) — место для помещения перекодируемых переменных. Необходимо особо подчеркнуть, что за один цикл использования диалогового окна Recode into Same Variables можно перекодировать сколько угодно переменных, но только одними и теми же кодами. Иными словами, нельзя в одной переменной нули заменить на единицы, а в другой — шестерки на строки Шесть. Для этого придется сначала перекодировать первую переменную (нули на единицы), а затем вновь вернуться в диалоговое окно Recode into Same Variables, щелкнуть на кнопке Reset и затем ввести данные для перекодировки другой переменной.
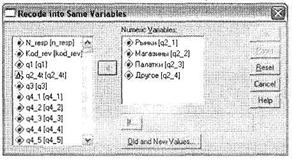 |
В нашем случае мы собираемся перекодировать четыре переменные, имеющие одинаковые унарные шкалы, состоящие всего из одного значения 1. Поэтому в описываемом диалоговом окне можно ввести их одновременно в область Variables (рис. 1.20).
|
При щелчке на кнопке If вызывается диалоговое окно, по внешнему виду и по функциям аналогичное окну Select Cases: If, представленному на рис. 1.16. Из этого окна молено производить перекодирование переменных, помещенных в область Variables, не для всех респондентов, а только для конкретных групп (например, только для мужчин).
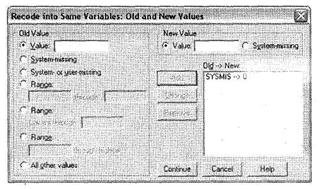
В нашем случае мы не будем ставить никаких условий. Щелкните на кнопке Old and New Values, которая открывает диалоговое окно, позволяющее задать перекодируемые значения (рис. 1.21). Это окно разделено на две части. В левой можно указать, какие конкретно значения подлежат перекодировке, а в правой — в какие значения они будут перекодированы. Чтобы указать конкретное значение для перекодировки, введите исходное значение в левое поле Value, а конечное значение — в правое поле Value.
Для специальных значений System Missing есть специальный одноименный параметр. В нашем примере в левой области диалогового окна выберите пункт System Missing, а в правой — в поле Value введите 0. Далее щелкните на кнопке Add, чтобы добавить указанное сочетание в список перекодировки. (Необходимо особо отметить, что значения, не указанные в списке перекодировки, оставляются неизменны.)
 |
|
После того как были указаны все необходимые варианты перекодирования (в нашем случае — только один), следует закрыть окно щелчком на кнопке Continue и запустить процедуру перекодирования кнопкой ОК. В исходной базе данных SPSS все значения System Missing в переменных q2_l - q2_4 будут перекодированы в нули, единицы при этом сохранятся.
1.5.3.2. Перекодирование с образованием новых переменных
Рассмотрим теперь другой случай перекодирования переменных, в результате которого исходная переменная остается неизменной, а перекодированные значения отражаются в новой переменной. Данная процедура осуществляется при помощи меню Transform ► Recode ► Into Different Variables. Диалоговое окно Recode into Different Variables (рис. 1.22) аналогично окну Recode into Same Variables (рис. 1.20), только добавлена дополнительная область Output Variable, предназначенная для указания имени (Name) и метки (Label) вновь создаваемой переменной, которая будет содержать перекодированные значения.
В качестве примера мы взяли переменную ql6, содержащую ответы на вопрос относительно частоты покупок респондентами плавленого сыра. При этом опрошенные должны были выбрать один из восьми вариантов:
1. каждый день;
2. 3-4 раза в неделю;
3. 1-2 раза в неделю;
4. 1-2 раза в месяц;
5. реже 1 раза в месяц;
6. 1 раз в полгола:
7. 1 раз в год;
8. затрудняюсь ответить.
После перекодирования мы должны получить переменную ql6_rec, в которой интервалы 1,2 и 3 будут объединены в группу с кодом 1 (Частые покупатели); интервалы 4, 5, 6 и 7 — в группу с кодом 2 (Редкие покупатели); а интервал 8 — в значения System Missing.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
