
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Таблица 2.1. Интерпретация уровней значимости
Уровень статистической значимости, р | Статистическая интерпретация | Обозначение в SPSS |
р < 0,001 | Максимально значимая | *** |
0,001 ≤ р ≤ 0,01 | Очень значимая | ** |
0,01 < р ≤0,05 | Значимая | * |
0,05 < р ≤ 0,10 | Слабо значимая | |
р > 0,10 | Незначимая |
В некоторых случаях (например, t-тесты) статистическая значимость в SPSS может быть одно - (1-tailed Sig.) или двухсторонней (2-tailed Sig.). Двухсторонняя значимость показывает, отличается ли значительно среднее значение первой исследуемой переменной от среднего значения второй — без указания направления этого различия, положительного или отрицательного. Односторонняя значимость показывает только направление, в котором второе исследуемое среднее отличается от первого. Второй тип значимости (односторонняя) при анализе данных маркетинговых исследований используется редко, и именно двухсторонняя значимость выводится SPSS по умолчанию. Таким образом, на практике нет необходимости обращать внимание на тип значимости, выводимой SPSS: она всегда будет показывать статистическую значимость исследуемого события1.
Целью описательного анализа является систематизация имеющихся данных. В рамках данной задачи происходит построение линейных распределений, а также характеристика переменных в различных статистических аспектах: расчет среднего, медианы, моды и т. п. Линейные (общие) распределения позволяют подсчитать количество респондентов, указавших тот или иной вариант ответа на рассматриваемый вопрос.
Построение линейных распределений обычно является первым шагом в статистическом анализе данных. При помощи линейных распределений становится возможным систематизировать ответы респондентов. В табл. 2.2 представлены основные характеристики переменных, участвующих в анализе.
Таблица 2.2. Основные характеристики переменных, участвующих в линейных распределениях
Линейные распределения | |||
Зависимые переменные | Независимые переменные | ||
Количество | Тип | Количество | Тип |
- | - | Одна | Любой |
2.1. Линейные распределения для одновариантных вопросов
Одновариантные вопросы являются основным ресурсом анализа при помощи SPSS. Практически все функции, реализованные в данном программном пакете, предназначены для работы только с одновариантными переменными. Анализ многовариантных переменных производится методом выделения каждого варианта ответа в отдельную одновариантную переменную и последующей работы уже с набором одновариантных переменных. Существуют табличные и графические способы построения линейных распределений по одновариантным вопросам. Ниже представлен способ, наиболее распространенный в маркетинговых исследованиях. Рассмотрим линейное распределение респондентов по возрастному признаку. Для этого предположим, что у нас есть файл данных, содержащий одновариантную переменную q4 (Возраст), имеющую порядковую шкалу, с четырьмя возможными вариантами ответа:
1. от 16 до 18 лет;
2. от 19 до 35 лет;
3. от 36 до 60 лет;
4. старше 60 лет.
Вызов диалогового окна для построения линейных распределений (также называемых частотами) осуществляется при помощи меню Analyze ► Descriptive Statistics ► Frequencies (рис. 2.1). В открывшемся окне в левом списке содержатся все доступные переменные, по которым можно построить линейные распределения. При помощи мыши перетащите нужные одновариантные переменные в правый список (в нашем случае — q4). При этом для анализа можно указать сразу несколько переменных.
|
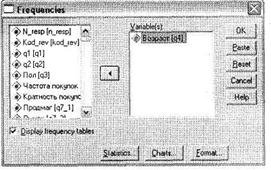 |
В диалоговом окне Statistics, вызываемом при помощи одноименной кнопки, можно указать, какие описательные статистики, кроме относительных и абсолютных значений, необходимо рассчитать (рис. 2.2). Например, рассчитаем моду (наиболее часто встречающееся значение), выбрав соответствующий параметр. Кроме этой статистики, SPSS позволяет рассчитать другие полезные величины:
■ среднее арифметическое для интервальных переменных (Mean);
■ минимальное и максимальное значения (Minimum и Maximum), — а также разбить значения переменной на квартили или другие процентили (область PercentiLe Values) и т. д.
Однако большинство представленных в этом диалоговом окне статистик подходит только для переменных, имеющих интервальный тип шкалы. Закрыв диалоговое окно Statistics посредством щелчка на кнопке Continue, вы вновь попадете в ос-, новное окно Frequencies.
|
 |
Необходимо сказать несколько слов относительно основных описательных статистик, показанных на рис. 2.2. Пожалуй, наиболее популярными характеристиками, используемыми для описания переменных, являются показатели группы Central Tendency (центральная тенденция): среднее арифметическое (Mean); медиана, или половина значений отрезка (Median); мода, или наиболее часто встречающееся значение (Mode); а также сумма (Sum). Имейте в виду, что данные показатели применяются неодинаково к переменным с различным типом шкалы (табл. 2.3).
Таблица 2.3. Наиболее релевантные показатели центральной тенденции для переменных с различным типом шкалы
Тип шкалы | Наиболее релевантная характеристика | Другие релевантные характеристики |
Интервальная | Среднее арифметическое | Средневзвешенное, мода |
Порядковая | Средневзвешенное | Мода |
Номинальная | Мода | - |
Из представленной таблицы видно, что наиболее релевантной описательной статистикой, характеризующей переменные с интервальной шкалой, является среднее арифметическое (Mean). Для переменных с порядковой шкалой данный показатель неприменим, так как он рассчитывается исходя из значений переменной (кодов вариантов ответа), а не самих значений интервалов.
Например, если рассчитать простое среднее по переменной Возраст (в которой возрастные группы закодированы цифрами от 1 до 4), получится 250,5 (см. рис. 2.6). Данное значение не несет в себе практически значимой нагрузки. Если же мы вместо этого рассчитаем средневзвешенное значение данной переменной по нижеприведенной формуле, мы получим реальный средний возраст респондентов: 43 года (43 - (408 × 48 + 321 × 27 + 207 ×68 + 66 × 17) / (408 + 321 + 207 + 66)).
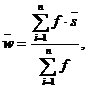
где ![]() — средневзвешенное значение; n — количество интервалов (вариантов ответа) в порядковой переменной;
— средневзвешенное значение; n — количество интервалов (вариантов ответа) в порядковой переменной; ![]() — частота появления i-го варианта ответа;
— частота появления i-го варианта ответа; ![]() — среднее арифметическое значение i-ro интервала.
— среднее арифметическое значение i-ro интервала.
Средняя тенденция переменных с номинальной шкалой не может быть оценена никак, кроме моды, — то есть для таких переменных можно определить только наиболее многочисленную группу. Например, по переменной Пол можно сказать, что в данном случае мужчины составляют три четверти всей выборочной совокупности респондентов.
В табл. 2.2 также видно, что интервальные переменные — наиболее гибкие относительно применения показателей центральной тенденции. Для них можно рассчитать все три рассматриваемые статистики: среднее арифметическое, средневзвешенное и моду. Порядковые переменные находятся на втором месте: с ними могут использоваться только средневзвешенное и мода. И наконец, номинальные переменные являются наименее гибкими: к ним может эффективно применяться только мода.
Теперь мы вновь возвращаемся к диалоговому окну Frequencies. Кнопка Charts вызывает одноименное диалоговое окно, которое позволяет помимо таблиц вывести диаграммы по выбранным переменным (рис. 2.3). По умолчанию SPSS не выводит диаграмм. Давайте построим круговую диаграмму (сектограмму), выбрав параметр Pie charts и указав в области Chart Values на необходимость отобразить на диаграмме не абсолютные (установлено по умолчанию), а относительные значения (Percentages). Выполнив это, закройте диалоговое окно Charts.
С помощью кнопки Format в главном диалоговом окне линейных распределений Frequencies можно указать, каким способом следует сортировать результаты в частотных таблицах (рис. 2.4). Это можно сделать, выбрав соответствующий параметр в области Order by. При этом возможной альтернативой будет сортировка кодов вариантов ответа (в нашем случае — кодировок возрастных групп):
■ по возрастанию: от 1 (16-18 лет) до 4 (старше 60 лет);
■ по убыванию: от 4 до 1;
■ по количеству респондентов, выбравших каждый из рассматриваемых вариантов ответа (в нашем случае — по численности четырех рассматриваемых возрастных групп).

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
