
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Если перед нами стоит задача сегментировать респондентов по их оценке различных аспектов текущей конкурентной позиции авиакомпании X, можно провести иерархический кластерный анализ по выделенным пяти критериям (переменные nfacl_l-nfac5_l). В нашем случае переменные оценивались по разным шкалам. Например, оценка 1 для утверждения Я бы не хотел, чтобы авиакомпания менялась и такая же оценка утверждению Изменения в авиакомпании будут позитивным моментом диаметрально противоположны по смыслу. В первом случае 1 балл (совершенно не согласен) означает, что респондент приветствует изменения в авиакомпании; во втором случае оценка в 1 балл свидетельствует о том, что респондент отвергает изменения в авиакомпании. При интерпретации кластеров у нас неизбежно возникнут трудности, так как такие противоположные по смыслу переменные могут
попасть в один и тот же фактор. Таким образом, для целей сегментирования рекомендуется сначала привести в соответствие шкалы исследуемых переменных, а затем пересчитать факторную модель. И уже далее проводить кластерный анализ над полученными в результате факторного анализа переменными-факторами. Мы не будем снова подробно описывать процедуры факторного и кластерного анализа (это было сделано выше в соответствующих разделах). Отметим лишь, что при такой методике в результате у нас получилось три целевые группы авиапассажиров, различающихся по уровню оценок выделенным факторам (то есть группам переменных): низшая, средняя и высшая.
Весьма полезным применением кластерного анализа является разделение на группы частотных таблиц. Предположим, у нас есть линейное распределение ответов на вопрос Какие марки антивирусов установлены в Вашей организации?. Для формирования выводов по данному распределению необходимо разделить марки антивирусов на несколько групп (обычно 2-3). Чтобы разделить все марки на три группы (наиболее популярные марки, средняя популярность и непопулярные марки), лучше всего воспользоваться кластерным анализом, хотя, как правило, исследователи разделяют элементы частотных таблиц на глаз, основываясь на субъективных соображениях. В противоположность такому подходу кластерный анализ позволяет научно обосновать выполненную группировку. Для этого следует ввести значения каждого параметра в SPSS (эти значения целесообразно выражать в процентах) и затем выполнить кластерный анализ для этих данных. Сохранив кластерное решение для необходимого количества групп (в нашем случае 3) в виде новой переменной, мы получим статистически обоснованную группировку.
Заключительную часть этого раздела мы посвятим описанию применения кластерного анализа для классификации переменных и сравнения его результатов с результатами факторного анализа, проведенного в разделе 5.2.1. Для этого мы вновь воспользуемся условием задачи про оценку текущей позиции авиакомпании X на рынке авиаперевозок. Методика проведения кластерного анализа практически полностью повторяет описанную выше (когда сегментировались респонденты).
Итак, в исходном файле данных у нас есть 24 переменные, описывающие отношение респондентов к различным аспектам текущей конкурентной позиции авиакомпании X. Откройте главное диалоговое окно Hierarchical Cluster Analysis и поместите 24 переменные (ql-q24) в поле Variable(s), рис. 5.55. В области Cluster укажите, что вы классифицируете переменные (отметьте параметр Variables). Вы увидите, что кнопка Save стала недоступна — в отличие от факторного, в кластерном анализе нельзя сохранить факторные рейтинги для всех респондентов. Откажитесь от вывода диаграмм, дезактивизировав параметр Plots. На первом этапе вам не нужны другие параметры, поэтому просто щелкните на кнопке О К, чтобы запустить процедуру кластерного анализа.
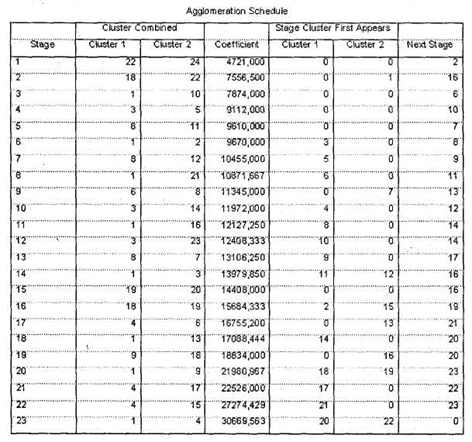
В окне SPSS Viewer появилась таблица Agglomeration Schedule, по которой мы определили оптимальное число кластеров описанным выше методом (рис. 5.56). Первый скачок коэффициента агломерации наблюдается на 20 шаге (с 18834,000 до 21980,967). Исходя из общего числа анализируемых переменных, равного 24, можно вычислить оптимальное число кластеров: 24 - 20 = 4.
|
 |
|
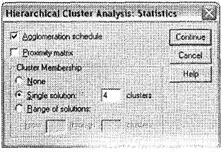
При классификации переменных практически и статистически значимым является кластер, состоящий всего из одной переменной. Поэтому, поскольку мы получили приемлемое число кластеров математическим методом, проведение дальнейших проверок не требуется. Вместо этого снова откройте главное диалоговое окно кластерного анализа (все данные, использованные на предыдущем этапе, сохранились) и щелкните на кнопке Statistics, чтобы организовать вывод классификационной таблицы. Вы увидите одноименное диалоговое окно, где необходимо указать число кластеров, на которое необходимо разделить 24 переменные (рис. 5.57). Для этого выберите параметр Single solution и в соответствующем поле укажите требуемое число кластеров: 4. Теперь закройте диалоговое окно Statistics щелчком на кнопке Continue и из главного окна кластерного анализа запустите
 |
процедуру на выполнение.
|
В результате в окне SPSS Viewer появится таблица Cluster Membership, распределяющая анализируемые переменные на четыре кластера (рис. 5.58).
|
 |
По данной таблице можно отнести каждую рассматриваемую переменную в определенный кластер следующим образом.
Кластер 1
ql. Авиакомпания X обладает репутацией компании, превосходно обслуживающей пассажиров.
q2. Авиакомпания X может конкурировать с лучшими авиакомпаниями мира.
q3. Я верю, что у авиакомпании X есть перспективное будущее в мировой авиации.
q5. Я горжусь тем, что работаю в авиакомпании X.
q9. Нам предстоит долгий путь, прежде чем мы сможем претендовать на то, чтобы называться авиакомпанией мирового класса.
qlO. Авиакомпания X действительно заботится о пассажирах.
ql3. Мне нравится, как в настоящее время авиакомпания X представлена визуально широкой общественности (в плане цветовой гаммы и фирменного стиля).
ql4. Авиакомпания X — лицо России.
ql6. Обслуживание авиакомпании X является последовательным и узнаваемым во всем
мире.
ql8. Авиакомпании X необходимо меняться для того, чтобы использовать в полной мере имеющийся потенциал.
ql9. Я думаю, что авиакомпании X необходимо представить себя в визуальном плане более современно.
q20. Изменения в авиакомпании X будут позитивным моментом. q21. Авиакомпания X — эффективная авиакомпания.
q22. Я бы хотел, чтобы имидж авиакомпании X улучшился с точки зрения иностранных пассажиров.
q23. Авиакомпания X — лучше, чем многие о ней думают.
q24. Важно, чтобы люди во всем мире знали, что мы — российская авиакомпания.
Кластер 2
q4. Я знаю, какой будет стратегия развития авиакомпании X в будущем.
q6. В авиакомпании X хорошее взаимодействие между подразделениями.
q7. Каждый сотрудник авиакомпании прикладывает все усилия для того, чтобы обеспечить ее успех.
q8. Сейчас авиакомпания X быстро улучшается.
qll. Среди сотрудников авиакомпании имеет место высокая степень удовлетворенности работой.
ql2. Я верю, что менеджеры высшего звена прикладывают все усилия для достижения успеха авиакомпании.
Кластер 3
ql5. Мы выглядим «вчерашним днем» по сравнению с другими авиакомпаниями.
Кластер 4
ql7. Я бы не хотел, чтобы авиакомпания X менялась.
Сравнив результаты факторного (раздел 5.2.1) и кластерного анализов, вы увидите, что они существенно различаются. Кластерный анализ не только предоставляет существенно меньшие возможности для кластеризации переменных (например, отсутствие возможности сохранять групповые рейтинги) по сравнению с факторным анализом, но и выдает гораздо менее наглядные результаты. В нашем случае, если кластеры 2, 3 и 4 еще поддаются логической интерпретации1, то кластер 1 содержит совершенно разные по смыслу утверждения. В данной ситуации можно либо попытаться описать кластер 1 как есть, либо перестроить статистическую модель с другим числом кластеров. В последнем случае для поиска оптимального числа кластеров, поддающихся логическому описанию, можно воспользоваться параметром Range of solutions в диалоговом окне Statistics (см. рис. 5.57), указав в соответствующих полях минимальное и максимальное число кластеров (в нашем случае 4 и 6 соответственно). В такой ситуации SPSS перестроит таблицу Cluster Membership для каждого числа кластеров. Задача аналитика в данном случае — попытаться подобрать такую классификационную модель, при которой все кластеры будут интерпретироваться однозначно. С целью демонстрации возможностей процедуры кластерного анализа для кластеризации переменных мы не будем перестраивать кластерную модель, а ограничимся лишь сказанным выше.
Необходимо отметить, что, несмотря на кажущуюся простоту проведения кластерного анализа по сравнению с факторным, практически во всех случаях из маркетинговых исследований факторный анализ оказывается быстрее и эффективнее кластерного. Поэтому для классификации (сокращения) переменных мы настоятельно рекомендуем использовать именно факторный анализ и оставить применение кластерного анализа для классификации респондентов.
Классификационный анализ является, пожалуй, одним из наиболее сложных, с точки зрения неподготовленного пользователя, статистических инструментов. С этим связана его весьма малая распространенность в маркетинговых компаниях. Вместе с тем именно данная группа статистических методов является и одной из наиболее полезных для практиков в области маркетинговых исследований.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
