
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Кластерный анализ является аналогом факторного анализа в том-смысле, что он так же, как и факторный анализ, позволяет выделить факторы (кластеры), объединяющие статистически схожие переменные. Однако в данном случае переменные классифицируются не на основании степени тесноты корреляционной связи, а на основании более сложных статистических процедур (наиболее часто используется метод исследования расстояний между переменными в кластерах). Ниже мы продемонстрируем действие обеих анализируемых статистических методик на одном массиве данных (см. выше).
Несмотря на имеющуюся возможность классифицировать переменные кластерный анализ чаще всего применяется для кластеризации групп респондентов (то есть уровней или категорий переменных)1. Данная возможность позволяет, например,
провести пробное (при неизвестных целевых группах) сегментирование целевых покупателей какого-либо продукта. Сформированные в результате кластерного анализа целевые группы респондентов обладают схожим поведением (то есть взаимозависимостями) своих характеристик. В качестве примера успешной кластеризации можно привести разбиение респондентов на две группы:
■ женщины в возрасте старше 45 лет;
■ все мужчины и женщины младше 45 лет.
При использовании рассматриваемой статистической методики для кластеризации респондентов можно совмещать кластерный и факторный анализ, причем в данном случае факторный анализ будет предшествовать кластерному. Часто это делается для того, чтобы сократить количество переменных, участвующих в кластерном анализе (при большом числе этих переменных). Так, можно сначала выделить среди большого числа переменных макропараметры, а затем сегментировать респондентов уже на основании данных факторов.
Теперь у вас сложилось общее представление о методах факторного и кластерного анализа, и мы можем приступить к описанию их практического применения. Воспользуемся условием задачи про анализ текущей конкурентной позиции авиакомпании X. Эта задача поможет нам также сравнить действие данных статистических методик на одной и той же выборке. Для описания кластерного анализа, применяемого для кластеризации респондентов, мы будем использовать другой пример из практики маркетинговых исследований. Так как для классификации переменных факторный анализ все же применяется чаще, чем кластерный (это сложилось исторически и, кроме того, оправдано меньшими усилиями, затрачиваемыми на проведение факторного анализа), в разделе 5.2.2 основное внимание будет уделено описанию действия кластерного анализа для классификации респондентов (выделения целевых групп потребителей). Сравнение действия двух статистических методов при классификации переменных мы предложим уже в заключении раздела 5.2.2.
В качестве примеров практического применения кластерного анализа в маркетинговых исследованиях можно указать все те же случаи, что и при факторном анализе (если кластерный анализ используется для классификации переменных). В случае применения кластерного анализа для классификации конкретных групп респондентов он предоставляет исследователю гораздо более гибкие возможности и в большем числе областей маркетинговых исследований по сравнению с факторным анализом. Это преимущество кластерного анализа обусловлено тем, что он анализирует не переменные в целом, а конкретные категории респондентов (например, различные половозрастные, доходные и другие группы покупателей). Таким образом, можно сделать важный вывод относительно факторного и кластерного анализов. Целью факторного анализа является сокращение числа переменных, участвующих в анализе (выделение релевантных макрокатегорий переменных), а целью кластерного — классификация респондентов на целевые группы на основании их существенных характеристик.
Из всего сказанного становится понятно, почему оба типа статистического анализа иногда используются в паре: факторный анализ определяет состав макропеременных (например, для сегментирования потребителей), а кластерный на основании выделенных существенных характеристик респондентов производит формирование целевых сегментов. Применение факторного и кластерного анализов в паре оправдано в основном в тех случаях, когда изначально респонденты оцениваются по большому числу параметров и проведение кластерного анализа непосредственно над данным (большим) набором переменных представляется затруднительным или даже практически невозможным. Отметим, что для проведения факторного и кластерного анализов в паре следует сначала провести факторный анализ, сохранив полученные факторные рейтинги, а затем проводить кластерный анализ на основании полученных групп переменных. Более подробно парное использование факторного и кластерного анализов будет показано в разделе 5.2.2.
В табл. 5.3 представлены основные характеристики переменных, участвующих в факторном и кластерном анализах.
Таблица 5.3. Основные характеристики переменных, участвующих в факторном и кластерном анализах
Факторный анализ | |||
Зависимые переменные | Независимые переменные | ||
Количество | Тип | Количество | Тип |
Нет | - | Любое | Любой |
Кластерный анализ | |||
Зависимые переменные | Независимые переменные | ||
Количество | Тип | Количество | Тип |
Нет | - | Любое | Любой |
5.2.1. Факторный анализ
Итак, из условия представленной выше задачи следует, что у нас есть массив данных, состоящий из 24 независимых переменных (утверждений), в различных аспектах описывающих текущее состояние авиакомпании X на международном рынке авиаперевозок. Основной задачей проводимого факторного анализа является группировка схожих по смыслу утверждений в макрокатегории с целью сократить число переменных и оптимизировать структуру данных.
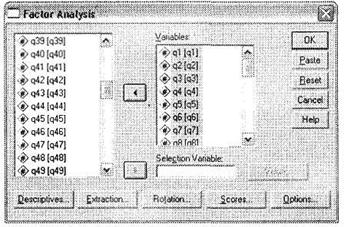
При помощи меню Analyze ►Data Reduction ► Factor вызовите окно Factor Analysis. Перенесите из левого списка в правый переменные для анализа (ql-q24), как показано на рис. 5.32. Поле Selection Variable позволяет выбрать переменную, в разрезе которой будет проводиться анализ (например, класс полета). В нашем случае оставьте это поле Пустым.
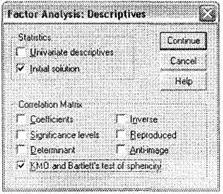
Щелкните на кнопке Descriptives и в открывшемся диалоговом окне (рис. 5.33) выберите пункт КМО and Barlett's test of sphericity. Это позволит определить, насколько имеющиеся данные пригодны для факторного анализа. Окно Descriptives позволяет вывести и другие необходимые описательные статистики. Однако в большинстве примеров из маркетинговых исследований эти возможности, как правило, не используются.
 |
 |
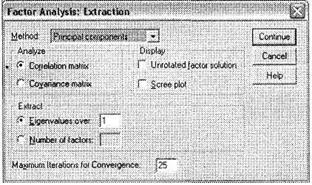
Закройте окно Descriptives, щелкнув на кнопке Continue. Далее откройте окно Extraction (рис. 5.34), щелкнув на соответствующей кнопке в главном диалоговом окне Factor Analysis. Это окно предназначено для выбора метода формирования факторной модели; выполните в нем следующие действия.
 |
|
Во-первых, в поле Method выберите метод извлечения (формирования) факторов. Общая рекомендация по выбору метода состоит в следующем. Необходимо выбирать тот метод извлечения факторов, который позволяет однозначно классифицировать как можно больше переменных. Таким образом, основные соображения здесь — число классифицированных факторов и однозначность классификации (то есть каждая переменная должна принадлежать только одному фактору). Как вы увидите ниже, установленный по умолчанию в SPSS метод Principal components в нашем случае позволяет однозначно классифицировать 22 переменные из 24 имеющихся (92 %), что является весьма хорошим показателем. На основании имеющегося опыта автор может утверждать, что хорошим результатом факторного анализа является доля однозначно классифицированных переменных не менее 90 %. Выберите метод Principal components. Данный метод является наиболее подходящим для решения большинства задач маркетинговых исследований при помощи факторного анализа.
Во-вторых, укажите количество образуемых факторов (группа Extract). По умолчанию установлен метод определения количества извлекаемых факторов на основании значений характеристических чисел (Eigenvalues over). He вдаваясь в статистические тонкости, отметим, что характеристические числа используются SPSS для определения количественного и качественного состава извлекаемых факторов. При предустановленном значении данного показателя, равном 1, количество образуемых факторов будет равно количеству переменных, значение характеристических чисел для которых больше или равно 1.
Также существует возможность вручную указать программе, сколько факторов необходимо извлекать (Number of factors). Эта возможность предусмотрена в SPSS для того, чтобы при слишком большом количестве переменных с характеристическим числом больше 1 вручную сократить число факторов. Большое число факторов трудно интерпретировать, поэтому если методом характеристических чисел не удается извлечь приемлемое для интерпретации число факторов (чем меньше, тем лучше), следует самостоятельно указать программе число факторов. Эта задача решается аналитиком в каждом конкретном случае индивидуально. В качестве одного из вариантов решения можно рекомендовать увеличить число eigenvalue с предустановленного значения 1, скажем, до 1,5 или более. Это поможет, если получено большое число факторов с характеристическим числом, приблизительно равным 1, и несколько (2-3 и более) факторов — с характеристическим числом более 1,5 или другого значения. Также при ручном определении количества факторов аналитик может принять релевантное решение, основываясь на своем опыте или на каких-либо иных предположениях. И наконец, необходимо отметить, что при ручном указании числа извлекаемых факторов иногда количество однозначно классифицированных переменных оказывается меньше, чем при методе экстракции по величине характеристических чисел. Однако данный негативный момент нивелируется возросшей наглядностью результатов факторного анализа — ведь это позволяет освободиться от факторов, в которых нет переменных со значимым коэффициентом корреляции (в нашем случае 0,5).

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
