
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
|
 |
 |
|
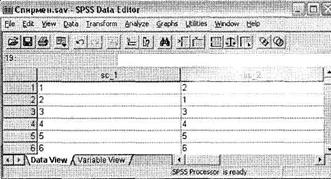
Как вы видите на рис. 4.20, две схемы выбора, составленные на основании прямого метода (вопрос 1) и на основании регрессионного анализа (вопрос 2), соответствуют друг другу не полностью, различаясь в порядке следования первой и второй категорий. Проанализируем эти схемы выбора магазинов одежды на предмет соответствия при помощи коэффициента корреляции Спирмана.
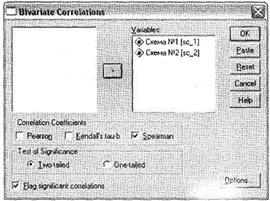 |
Для этого снова откройте диалоговое окно Bi variate Correlations, выбрав пункт меню Analyze ► Correlate ► Bivariate. Перенесите две интересующие нас переменные — Схема №1 (составленная по вопросу 1) и Схема №2 (составленная по вопросу 2) — из левого списка всех доступных переменных в область Variables (рис. 4.21). Отмените вывод корреляции Пирсона и вместо него выберите параметр Spearman (корреляция Спирмана). После этого начните расчет при помощи щелчка на кнопке ОК.
|
 |
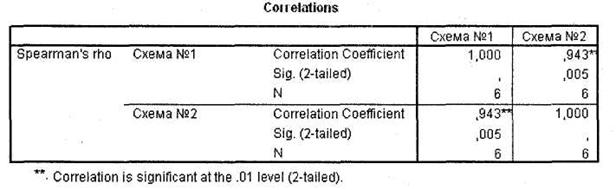
В окне SPSS Viewer появится таблица Correlations с результатами расчета коэффициента ранговой корреляции (Спирмана) по двум анализируемым переменным. Как следует из рис. 4.22, две рассматриваемые схемы выбора различаются несущественно. Данный вывод можно сделать из сильной корреляции между переменными sc_l и sc_2 (коэффициент корреляции Спирмана = 0,9), характеризующейся весьма высокой статистической значимостью (0,005).
|
В заключение напомним, что ранговый коэффициент корреляции Спирмана (в отличие от Кендала) может применяться и в качестве аналога корреляции Пирсона при исследовании зависимостей между переменными, не приводимыми к интервальному виду и потому не являющимися ранжированными списками. В качестве примера можно привести гипотетический случай, рассмотренный выше, когда анализируется влияние пола респондентов (дихотомическая шкала) на уровень образования (порядковая по сути, но номинальная по виду шкала).
4.2.2. Частные корреляции. Выявление ложных корреляций
На практике иногда возникают ситуации, когда в результате корреляционного анализа обнаруживаются логически необъяснимые, противоречащие объективному опыту исследователя корреляции между двумя переменными (например, оказывается, что между уровнем дохода респондентов и количеством детей в семье существует статистически значимая зависимость). В этом случае говорят о так называемой ложной корреляции, исследовать которую помогают частные коэффициенты корреляции.
Рассмотрим процедуру исследования частных корреляций на следующем примере из маркетингового исследования поведения посетителей залов игровых автоматов. В результате обработки анкет респондентов были, в частности, получены три интервальные переменные:
■ q47 — возраст;
■ q49 — количество членов семьи;
■ q50 — среднемесячный доход на 1 члена семьи.
Над данными переменными был проведен корреляционный анализ (Пирсона), который выявил логически необъяснимую, но статистически значимую зависимость между переменными: Доход и Количество членов семьи (рис. 4.23).
|
 |
Как видно из таблицы, обе рассматриваемые переменные коррелируют с третьей переменной Возраст. В такой ситуации корреляция между уровнем дохода респондентов и численностью их семей может объясняться влиянием третьей переменной: возраста респондентов. То есть связанными (коррелирующими), на самом деле, являются пары возраст/уровень дохода и возраст/количество членов семьи. Проверим данную гипотезу при помощи частных коэффициентов корреляции.
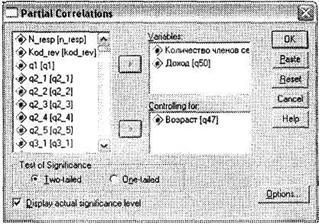 |
Откройте диалоговое окно Partial Correlations (меню Analyze ► Correlate ► Partial). В левом списке всех доступных переменных выберите переменные, между которыми обнаружена странная корреляция (q50 Доход и q49 Количество членов семьи), и поместите их в область Variables. Переменную, с которой коррелируют обе исследуемые переменные (q47 Возраст), поместите в область Controlling for (рис. 4.24). В этом диалоговом окне больше ничего не изменяйте — просто запустите программу на исполнение, щелкнув на кнопке ОК.
|
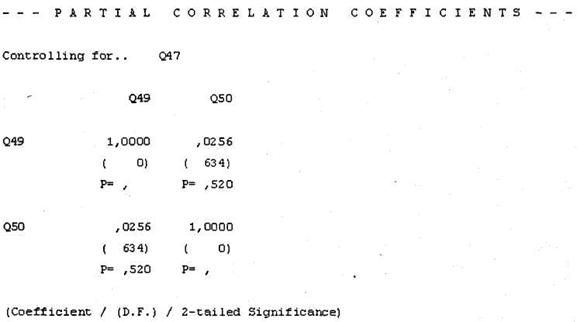
В окне SPSS Viewer появятся результаты расчетов частных коэффициентов корреляции (рис. 4.25). В данной таблице первая строка каждой ячейки содержит коэффициент корреляции Пирсона, а третья — статистическую значимость данного коэффициента. Из таблицы вы видите, что между количеством членов семьи (q49) и уровнем дохода (q50) больше не наблюдается статистически значимой корреляции (Р = 0,520), а коэффициент Пирсона сильно уменьшился (0,0256). Следовательно, корреляция, представленная на рис. 4.23, объясняется влиянием третьей переменной Возраст и, таким образом, является ложной.
 |
|
4.3. Линейный регрессионный анализ и статистическое
прогнозирование
Линейная регрессия является наиболее часто используемым видом регрессионного анализа. Ниже перечислены три основные задачи, решаемые в маркетинговых исследованиях при помощи линейного регрессионного анализа.
1. Определение того, какие частные параметры продукта оказывают влияние на общее впечатление потребителей от данного продукта. Установление направления и силы данного влияния. Расчет, каким будет значение результирующего параметра при тех или иных значениях частных параметров. Например, требуется установить, как влияет возраст респондента и его среднемесячный доход на частоту покупок глазированных сырков.
2. Выявление того, какие частные характеристики продукта влияют на общее впечатление потребителей от данного продукта (построение схемы выбора продукта потребителями). Установление соотношения между различными частными параметрами по силе и направлению влияния на общее впечатление. Например, имеются оценки респондентами двух характеристик мебели производителя X — цены и качества, — а также общая оценка мебели данного производителя. Требуется установить, какой из двух параметров является наиболее значимым для покупателей при выборе производителя мебели и в каком конкретном соотношении находится значимость для покупателей данных двух факторов (параметр Цена в х раз более значим для покупателей при выборе мебели, чем параметр Качество).
3. Графическое прогнозирование поведения одной переменной в зависимости от изменения другой (используется только для двух переменных). Как правило, целью проведения регрессионного анализа в данном случае является не столько расчет уравнения, сколько построение тренда (то есть аппроксимирующей кривой, графически показывающей зависимость между переменными). По полученному уравнению можно предсказать, каким будет значение одной переменной при изменении (увеличении или уменьшении) другой. Например, требуется установить характер зависимости между долей респондентов, осведомленных о различных марках глазированных сырков, и долей респондентов, покупающих данные марки. Также требуется рассчитать, насколько возрастет доля покупателей сырков марки х при увеличении потребительской осведомленности на 10 % (в результате проведения рекламной кампании).
В зависимости от типа решаемой задачи выбирается вид линейного регрессионного анализа. В большинстве случаев (1 и 2) применяется множественная линейная регрессия, в которой исследуется влияние нескольких независимых переменных на одну зависимую. В случае 3 применима только простая линейная регрессия, в которой участвуют только одна независимая и одна зависимая переменные. Это связано с тем, что основным результатом анализа в случае 3 является линия тренда, которая может быть логически интерпретирована только в двухмерном пространстве. В общем случае результатом проведения регрессионного анализа является построение уравнения регрессии вида: у = а + Ь, х, + Ь2х2 + ... + Ь„хп, позволяющего рассчитать значение зависимой переменной при различных значениях независимых переменных.
В табл. 4.6 представлены основные характеристики переменных, участвующих в анализе.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
