
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Прежде чем продолжить описание процесса кластерного анализа, необходимо привести краткое описание других параметров. Среди них есть как полезные возможности, так и фактически лишние (с точки зрения практических маркетинговых исследований). Так, например, главное диалоговое окно Hierarchial Cluster Analysis содержит поле Label Cases by, в которое при желании можно поместить текстовую переменную, идентифицирующую респондентов. В нашем случае для этих целей может служить переменная q4, кодирующая выбранные респондентами авиакомпании. На практике сложно придумать рациональное объяснение использованию поля Label Cases by, поэтому можно спокойно всегда оставлять его пустым.
 |
|
Нечасто при проведении кластерного анализа используется диалоговое окно Statistics, вызываемое одноименной кнопкой в главном диалоговом окне. Оно позволяет организовать вывод в окне SPSS Viewer таблицы Cluster Membership, в которой каждому респонденту в исходном файле данных сопоставляется номер кластера. Данная таблица при достаточно большом количестве респондентов (практически во всех примерах маркетинговых исследований) становится совершенно бесполезной, так как представляет собой длинную последовательность пар значений «номер респондента/номер кластера», в таком виде не поддающуюся интерпретации. Технически цель кластерного анализа всегда состоит в образовании в файле данных дополнительной переменной, отражающей разделение респондентов на целевые группы (при помощи щелчка на кнопке Save в главном диалоговом окне кластерного анализа). Эта переменная в совокупности с номерами респондентов и есть таблица Cluster Membership. Единственный практически полезный параметр в окне Statistics — вывод таблицы Average Linkage (Between Groups), однако он уже установлен по умолчанию. Таким образом, использование кнопки Statistics и вывод отдельной таблицы Cluster Membership в окне SPSS Viewer является нецелесообразным.
Про кнопку Plots уже было сказано выше: ее следует дезактивизировать, отменив параметр Plots в главном диалоговом окне кластерного анализа.
Кроме этих редко используемых возможностей процедуры кластерного анализа, SPSS предлагает и весьма полезные параметры. Среди них прежде всего кнопка Save, позволяющая создать в исходном файле данных новую переменную, распределяющую респондентов по кластерам. Также в главном диалоговом окне существует область для выбора объекта кластеризации: респондентов или переменных. Об этой возможности говорилось выше в разделе 5.4. В первом случае кластерный анализ используется в основном для сегментирования респондентов по некоторым критериям; во втором цель проведения кластерного анализа аналогична факторному анализу: классификация (сокращение числа) переменных.
Как видно из рис. 5.44, единственной не рассмотренной возможностью кластерного анализа является кнопка выбора метода проведения статистической процедуры Method. Эксперименты с данным Параметром позволяют добиться большей точности при определении оптимального числа кластеров. Общий вид этого диалогового окна с параметрами, установленными по умолчанию, представлен на рис. 5.48.
|
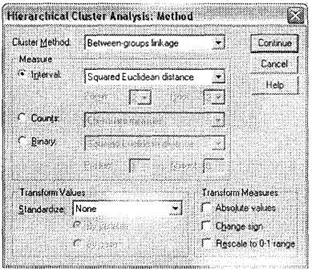 |
Первое, что устанавливается в данном окне, — это метод формирования кластеров (то есть объединения наблюдений). Среди всех возможных вариантов статистических методик, предлагаемых SPSS, следует выбирать либо установленный по умолчанию метод Between-groups linkage, либо процедуру Ward (Ward's method). Первый метод используется чаще ввиду его универсальности и относительной простоты статистической процедуры, на которой он основан. При использовании этого метода расстояние между кластерами вычисляется как среднее значение расстояний между всеми возможными парами наблюдений, причем в каждой итерации принимает участие одно наблюдение из одного кластера, а второе — из другого. Информация, необходимая для расчетов расстояния между наблюдениями, находится на основании всех теоретически возможных пар наблюдений. Метод Ward более сложен для понимания и используется реже. Он состоит из множества этапов и основан на усреднении значений всех переменных для каждого наблюдения и последующем суммировании квадратов расстояний от вычисленных средних до каждого наблюдения. Для решения практических задач маркетинговых исследований мы рекомендуем всегда использовать метод Between-groups linkage, установленный по умолчанию.
После выбора статистической процедуры кластеризации следует выбрать метод для вычисления расстояний между наблюдениями (область Measure в диалоговом окне Method). Существуют различные методы определения расстояний для трех типов переменных, участвующих в кластерном анализе (критериев сегментирования). Эти переменные могут иметь интервальную (Interval), номинальную (Counts) или дихотомическую (Binary) шкалу. Дихотомическая шкала (Binary) подразумевает только переменные, отражающие наступление/ненаступление какого-либо события (купил/не купил, да/нет и т. д.). Другие типы дихотомических переменных (например, мужчина/женщина) следует рассматривать и анализировать как номинальные (Counts).
Наиболее часто используемым методом определения расстояний для интервальных переменных является квадрат евклидова расстояния (Squared Euclidean Distance), устанавливаемый по умолчанию. Именно этот метод зарекомендовал себя в маркетинговых исследованиях как наиболее точный и универсальный. Однако для дихотомических переменных, где наблюдения представлены только двумя значениями (например, 0 и 1), данный метод не подходит. Дело в том, что он учитывает только взаимодействия между наблюдениями типа: X = 1,Y = 0 и X = 0, Y=l (где X и Y — переменные) и не учитывает другие типы взаимодействий. Наиболее комплексной мерой расстояния, учитывающей все важные типы взаимодействий между двумя дихотомическими переменными, является метод Лямбда (Lambda). Мы рекомендуем применять именно данный метод ввиду его универсальности. Однако существуют и другие методы, например Shape, Hamann или Anderbergs's D.
При указании метода определения расстояний для дихотомических переменных в соответствующем поле необходимо указать конкретные значения, которые могут принимать исследуемые дихотомические переменные: в поле Present — кодировку ответа Да, а в поле Absent — Нет. Названия полей присутствует и отсутствует ассоциированы с тем, что в группе методов Binary предполагается использовать только дихотомические переменные, отражающие наступление/ненаступление какого-либо события. Для двух типов переменных Interval и Binary существует несколько методов определения расстояния. Для переменных с номинальным типом шкалы SPSS предлагает всего два метода: ![]() (Chi-square measure) и
(Chi-square measure) и ![]() (Phi-square measure). Мы рекомендуем использовать первый метод как наиболее распространенный.
(Phi-square measure). Мы рекомендуем использовать первый метод как наиболее распространенный.
В диалоговом окне Method есть область Transform Values, в которой находится поле Standardize. Данное поле применяется в том случае, когда в кластерном анализе принимают участие переменные с различным типом шкалы (например, интервальные и номинальные). Для того чтобы использовать эти переменные в кластерном анализе, следует провести стандартизацию, приводящую их к единому типу шкалы — интервальному. Самым распространенным методом стандартизации переменных является 2-стандартизация (Zscores): все переменные приводятся к единому диапазону значений от -3 до +3 и после преобразования являются интервальными.
Так как все оптимальные методы (кластеризации и определения расстояний) установлены по умолчанию, целесообразно использовать диалоговое окно Method только для указания типа анализируемых переменных, а также для указания необходимости произвести 2-стандартизацию переменных.
Итак, мы описали все основные возможности, предоставляемые SPSS для проведения кластерного анализа. Вернемся к описанию кластерного анализа, проводимого с целью сегментирования авиакомпаний. Напомним, что мы остановились на шестнадцатикластерном решении и создали в исходном файле данных новую переменную clul6_l, распределяющую все анализируемые авиакомпании по кластерам.
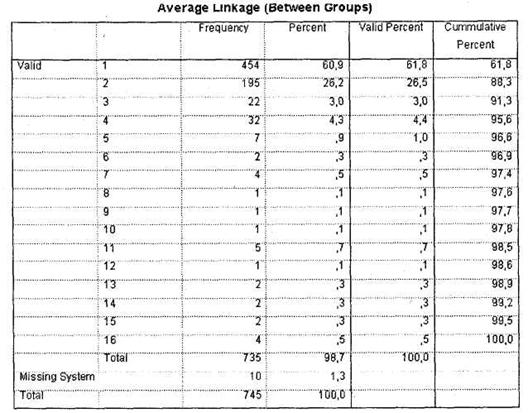
Чтобы установить, насколько верно мы определили оптимальное число кластеров, построим линейное распределение переменной clul6_l (меню Analyze ► Descriptive Statistics ► Frequencies). Как видно на рис. 5.49, в кластерах с номерами 5-16 число респондентов составляет от 1 до 7. Наряду с вышеописанным универсальным методом определения оптимального количества кластеров (на основании разности между общим числом респондентов и первым скачком коэффициента агломерации) существует также дополнительная рекомендация: размер кластеров должен быть статистически значимым и практически приемлемым. При нашем размере выборки такое критическое значение можно установить хотя бы на уровне 10. Мы видим, что под данное условие попадают лишь кластеры с номерами 1-4. Поэтому
теперь необходимо пересчитать процедуру кластерного анализа с выводом четы-рехкластерного решения (будет создана новая переменная du4_l).
|
 |
Построив линейное распределение по вновь созданной переменной du4_l, мы увидим, что только в двух кластерах (1 и 2) число респондентов является практически значимым. Нам необходимо снова перестроить кластерную модель — теперь для двухкластерного решения. После этого построим распределение по переменной du2_l (рис. 5.50). Как вы видите из таблицы, двухкластерное решение имеет статистически и практически значимое число респондентов в каждом из двух сформированных кластеров: в кластере 1 — 695 респондентов; в кластере 2 — 40. Итак, мы определили оптимальное число кластеров для нашей задачи и провели собственно сегментирование респондентов по семи избранным критериям. Теперь можно считать основную цель нашей задачи достигнутой и приступать к завершающему этапу кластерного анализа — интерпретации полученных целевых групп (сегментов).

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
