
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
|
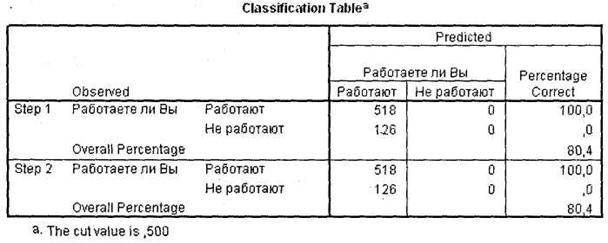
Далее следуют результаты классификации (таблица Classification Table, рис. 5.6), в которой реально наблюдаемые показатели принадлежности к той или иной из двух исследуемых групп сопоставляются с предсказанными на основе логистической регрессионной модели. В нашем случае из строки Overall Percentage мы видим, что построенная модель позволяет корректно классифицировать 80,4 % респондентов. Также можно сделать соответствующие выводы о корректности классификации для каждой из двух рассматриваемых групп.
Из следующей таблицы (рис. 5.7) можно выяснить статистическую значимость независимых переменных, включенных в анализ (в нашем случае q22 и aver), а также нестандартизированные регрессионные коэффициенты, являющиеся коэффициентами регрессионной функции. На основании этих коэффициентов (включая константу Constant) вы можете спрогнозировать принадлежность к определенной группе каждого конкретного респондента в выборке. Это делается следующим образом.
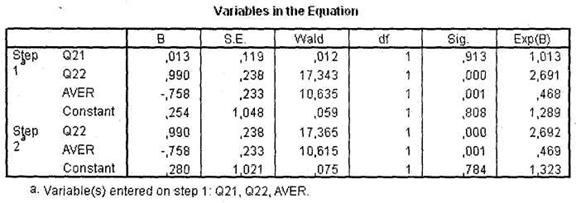 |
| |
|
Например, выпускник вуза получил средний балл 3,3 (aver = 3,3); это женщина (q22 = 2). В таком случае уравнение регрессии будет выглядеть следующим образом:
![]()
а вероятность для рассматриваемого респондента оказаться в одной из анализируемых групп классификации (это всегда группа зависимой переменной, имеющая больший код, в нашем случае 2 — Не работают) будет рассчитываться по формуле:
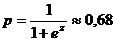
Таким образом, женщина со средним баллом 3,3 имеет достаточно высокие шансы оказаться безработной (68 %).
Теперь рассмотрим пример проведения мультиномиальной логистической регрессии. В качестве исходных данных мы будем использовать три независимые переменные из предыдущего примера, а в качестве зависимой — переменную q24 Заработная плата с пятью категориями, кодирующими интервалы зарплаты.
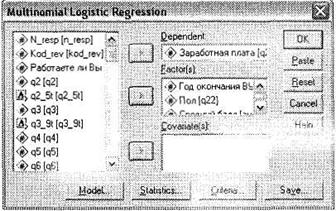
Откройте диалоговое окно Multinomial Logistic Regression при помощи меню Analyze ► Regression ► Multinomial Logistic (рис. 5.8). В поле для зависимой переменной поместите переменную q24, а в область для зависимых переменных — q21, q22 и aver.
Кнопка Model позволяет задать конкретный тип модели (полнофакторная, основные эффекты или пользовательская), однако для маркетинговых исследований мы советуем ничего не менять в окне Model.
При помощи кнопки Statistics вызывается одноименное диалоговое окно (рис. 5.9). В нем следует оставить выбранные по умолчанию три параметра: Summary statistics, Likelihood ratio test и Parameter estimates, а также выбрать еще один пункт — Cell Probabilities.
 |
|
 |
|
Кнопка Criteria не предоставляет маркетологам существенных для решения их задач функций, поэтому используется редко.
При помощи кнопки Save (рис. 5.10) можно задать новые переменные, содержащие принадлежность к определенной классификационной группе (параметр Predicted category) и вероятность попадания в данные категории (параметр Predicted probabilities membership).
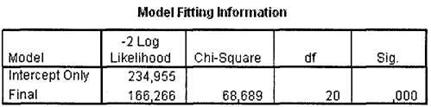
После щелчка на кнопке 0К в главном диалоговом окне Multinomial Logistic Regression в окне SPSS Viewer появятся результаты расчетов. Первая таблица, содержащая важные для нас сведения, — это Model Fitting Information, показанная на рис. 5.11. Высокая статистическая значимость построенной модели (Sig. < 0,001) свидетельствует о ее высоком качестве и пригодности для решения практических задач.
Вторая значимая таблица Pseudo R-Square предоставляет возможность оценить долю совокупной дисперсии в зависимой переменной, объясняемой выбранными для анализа независимыми переменными (по тесту Nagelkerke). В нашем случае построенная модель объясняет 15 % совокупной дисперсии (рис. 5.12).
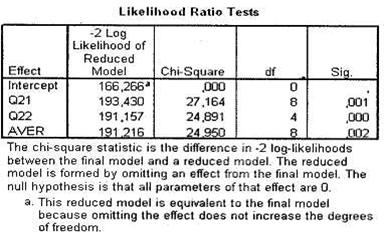
Таблица Likelihood Ratio Tests (рис. 5.13) позволяет сделать выводы относительно статистической значимости каждой из зависимых переменных, входящих в построенную модель. В нашем случае все три исследуемые переменные оказывают весьма значимое влияние на зависимую переменную (Sig. < 0,05).
 |
|
 |
|
 |
|
 |
 |
|
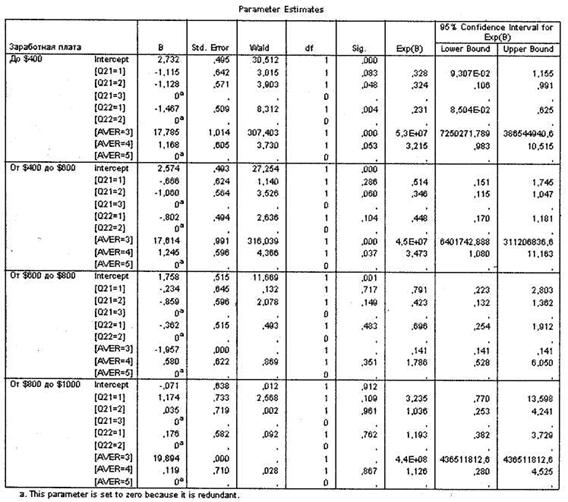
Следующая таблица, Parameter Estimates (рис. 5.14), отражает нестандартизированные регрессионные коэффициенты, на основании которых происходит построение регрессионного уравнения. Также для каждого сочетания анализируемых переменных рассчитана статистическая значимость их влияния на зависимую переменную. В дальнейшем рассчитать вероятность попадания того или иного респондента в одну из исследуемых групп зависимой переменной можно по вышеприведенной формуле (показана при обсуждении бинарной логистической регрессии).
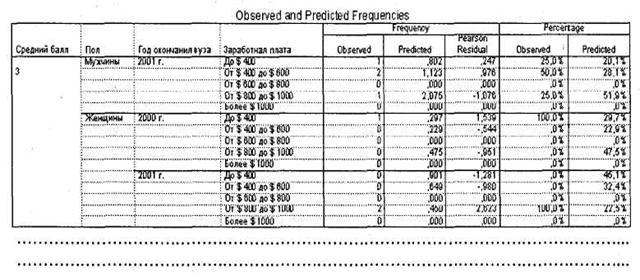
Однако в маркетинговых исследованиях чаще всего возникает необходимость классифицировать по группам не отдельных респондентов, а целые целевые группы. Для этого служит таблица Observed and Predicted Frequencies, представленная на рис. 5.15. В столбце Percentage ► Predicted показаны вероятности попадания каждой исследуемой целевой группы респондентов в ту или иную категорию зависимой переменной. Так, например, мы видим, что 20 % мужчин, окончивших ВУЗ в 2001 г. и получивших средний балл 3,0, зарабатывают до $ 400 в месяц.
|
5.1.2. Дискриминантный анализ
Дискриминантный анализ является более универсальной статистической процедурой по сравнению с рассмотренными выше методами логистической регрессии. Основным результатом проведения дискриминантного анализа являются (также как для логистической регрессии) рассчитанные вероятности попадания каждого респондента в ту или иную группу, а также переменная, кодирующая принадлежность их к данным группам. Наряду с этой информацией по результатам дискриминантного анализа можно составить уравнение дискриминантной функции.
В табл. 5.2 приведены основные характеристики переменных, участвующих в дис-криминантном анализе.
Таблица 5.2. Основные характеристики переменных, участвующих в анализе
Дискриминантный анализ | |||
Зависимые переменные | Независимые переменные | ||
Количество | Тип | Количество | Тип |
Одна | Номинальная Порядковая | Любое | Любой |
При выборе зависимой переменной для дискриминантного анализа следует помнить, что увеличение числа категорий в ней практически всегда влечет уменьшение качества статистической модели, то есть ее точности и надежности. Поэтому рекомендуется использовать в качестве зависимых переменные с малым количеством категорий (или преобразовывать существующие переменные к данному виду).
Для описания процесса проведения дискриминантного анализа применим следующие исходные данные. Проводится маркетинговое исследование потенциального спроса на услуги нового развлекательного комплекса. Респонденты в ходе опроса отвечают на вопрос Будете ли Вы посещать новый комплекс? (q26) с вариантами ответа Да и Нет. В качестве независимых переменных, характеризующих респондентов, выделены:

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
