
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
 |
|
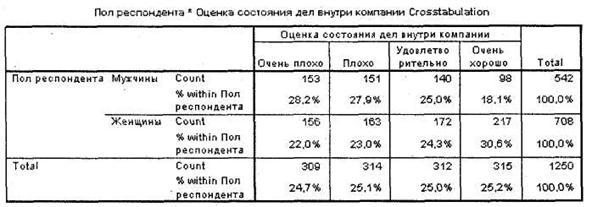
5.2.2. Иерархический кластерный анализ
В статистике существует два основных типа кластерного анализа (оба представлены в SPSS): иерархический и осуществляемый методом k-средних. В первом случае автоматизированная статистическая процедура самостоятельно определяет оптимальное число кластеров и ряд других параметров, необходимых для кластерного
анализа. Второй тип анализа имеет существенные ограничения по практической применимости — для него необходимо самостоятельно определять и точное количество выделяемых кластеров, и начальные значения центров каждого кластера (центроиды), и некоторые другие статистики. При анализе методом k-средних данные проблемы решаются предварительным проведением иерархического кластерного анализа и затем на основании его результатов расчетом кластерной модели по методу k-средних, что в большинстве случаев не только не упрощает, а наоборот, усложняет работу исследователя (в особенности неподготовленного).
В целом можно сказать, что в связи с тем, что иерархический кластерный анализ весьма требователен к аппаратным ресурсам компьютера, кластерный анализ по методу k-средних введен в SPSS для обработки очень больших массивов данных, состоящих из многих тысяч наблюдений (респондентов), в условиях недостаточной мощности компьютерного оборудования1. Размеры выборок, используемых в маркетинговых исследованиях, в большинстве случаев не превышают четыре тысячи респондентов. Практика маркетинговых исследований показывает, что именно первый тип кластерного анализа — иерархический — рекомендуется для использования во всех случаях как наиболее релевантный, универсальный и точный. Вместе с тем необходимо подчеркнуть, что при проведении кластерного анализа важным является отбор релевантных переменных. Данное замечание очень существенно, так как включение в анализ нескольких или даже одной нерелевантной переменной способно привести к неудаче всей статистической процедуры.
Описание методики проведения кластерного анализа мы проведем на следующем примере из практики маркетинговых исследований.
Исходные данные:
В ходе исследования было опрошено 745 авиапассажиров, летавших одной из 22 российских и зарубежных авиакомпаний. Авиапассажиров просили оценить по пятибалльной шкале — от 1 (очень плохо) до 5 (отлично) — семь параметров работы наземного персонала авиакомпаний в процессе регистрации пассажиров на рейс: вежливость, профессионализм, оперативность, готовность помочь, регулирование очереди, внешний вид, работа персонала в целом.
Требуется:
Сегментировать исследуемые авиакомпании по уровню воспринимаемого авиапассажирами качества работы наземного персонала.
Итак, у нас есть файл данных, который состоит из семи интервальных переменных, обозначающих оценки качества работы наземного персонала различных авиакомпаний (ql3-ql9), представленные в единой пятибалльной шкале. Файл данных содержит одновариантную переменную q4, указывающую выбранные респондентами авиакомпании (всего 22 наименования). Проведем кластерный анализ и определим, на какие целевые группы можно разделить данные авиакомпании.
Иерархический кластерный анализ проводится в два этапа. Результат первого этапа — число кластеров (целевых сегментов), на которые следует разделить исследуемую выборку респондентов. Процедура кластерного анализа как таковая не
может самостоятельно определить оптимальное число кластеров. Она может только подсказать искомое число. Поскольку задача определения оптимального числа сегментов является ключевой, она обычно решается на отдельном этапе анализа. На втором этапе производится собственно кластеризация наблюдений по тому числу кластеров, которое было определено в ходе первого этапа анализа. Теперь рассмотрим эти шаги кластерного анализа по порядку.
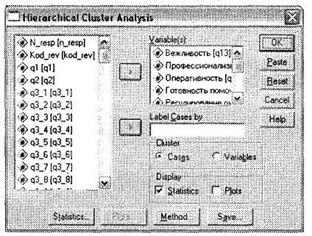 |
Процедура кластерного анализа запускается при помощи меню Analyze ► Classify ► Hierarchical Cluster. В открывшемся диалоговом окне из левого списка всех имеющихся в файле данных переменных выберите переменные, являющиеся критериями сегментирования. В нашем случае их семь, и обозначают они оценки параметров работы наземного персонала ql3-ql9 (рис. 5.44). В принципе указания совокупности критериев сегментирования будет вполне достаточно для выполнения первого этапа кластерного анализа.
|
По умолчанию кроме таблицы с результатами формирования кластеров, на основании которой мы определим их оптимальное число, SPSS выводит также специальную перевернутую гистограмму icicle, помогающую, по замыслу создателей программы, определить оптимальное количество кластеров; вывод диаграмм осуществляется кнопкой Plots (рис. 5.45). Однако если оставить данный параметр установленным, мы потратим много времени на обработку даже сравнительно небольшого файла данных. Кроме icicle в окне Plots можно выбрать более быструю линейчатую диаграмму Dendogram. Она представляет собой горизонтальные столбики, отражающие процесс формирования кластеров. Теоретически при небольшом (до 50-100) количестве респондентов данная диаграмма действительно помогает выбрать оптимальное решение относительно требуемого числа кластеров. Однако практически во всех примерах из маркетинговых исследований размер выборки превышает это значение. Дендограмма становится совершенно бесполезной, так как даже при относительно небольшом числе наблюдений представляет собой очень длинную последовательность номеров строк исходного файла данных, соединенных между собой горизонтальными и вертикальными линиями. Большинство учебников по SPSS содержат примеры кластерного анализа именно на таких искусственных, малых выборках. В настоящем пособии мы показываем, как наиболее эффективно работать с SPSS в практических условиях и на примере реальных маркетинговых исследований.
 |
|
Как мы установили, для практических целей ни Icicle, ни Dendogram не пригодны. Поэтому в главном диалоговом окне Hierarchical Cluster Analysis рекомендуется не выводить диаграммы, отменив выбранный по умолчанию параметр Plots в области Display, как показано на рис. 5.44. Теперь все готово для выполнения первого этапа кластерного анализа. Запустите процедуру, щелкнув на кнопке ОК.
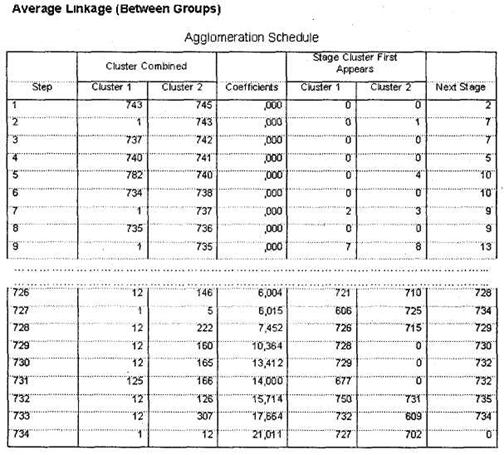
Через некоторое время в окне SPSS Viewer появятся результаты. Как было сказано выше, единственным значимым для нас итогом первого этапа анализа будет таблица Average Linkage (Between Groups), представленная на рис. 5.46. На основании этой таблицы мы должны определить оптимальное число кластеров. Необходимо заметить, что единого универсального метода определения оптимального числа кластеров не существует. В каждом конкретном случае исследователь должен сам определить это число.
Исходя из имеющегося опыта, автор предлагает следующую схему данного процесса. Прежде всего, попробуем применить наиболее распространенный стандартный метод для определения числа кластеров. По таблице Average Linkage (Between Groups) следует определить, на каком шаге процесса формирования кластеров (колонка Stage) происходит первый сравнительно большой скачок коэффициента агломерации (колонка Coefficients). Данный скачок означает, что до него в кластеры объединялись наблюдения, находящиеся на достаточно малых расстояниях друг от друга (в нашем случае респонденты со схожим уровнем оценок по анализируемым параметрам), а начиная с этого этапа происходит объединение более далеких наблюдений.
В нашем случае коэффициенты плавно возрастают от 0 до 7,452, то есть разница между коэффициентами на шагах с первого по 728 была мала (например, между 728 и 727 шагами — 0,534). Начиная с 729 шага происходит первый существенный скачок коэффициента: с 7,452 до 10,364 (на 2,912). Шаг, на котором происходит первый скачок коэффициента, — 729. Теперь, чтобы определить оптимальное ко-
личество кластеров, необходимо вычесть полученное значение из общего числа наблюдений (размера выборки). Общий размер выборки в нашем случае составляет 745 человек; следовательно, оптимальное количество кластеров составляет 745-729 = 16.
 |
|
Мы получили достаточно большое число кластеров, которое в дальнейшем будет сложно интерпретировать. Поэтому теперь следует исследовать полученные кластеры и определить, какие из них являются значимыми, а какие нужно попытаться сократить. Данная задача решается на втором этапе кластерного анализа.
Откройте главное диалоговое окно процедуры кластерного анализа (меню Analyze ► Classify ► Hierarchical Cluster). В поле для анализируемых переменных у нас уже есть семь параметров. Щелкните на кнопке Save. Открывшееся диалоговое окно (рис. 5.47) позволяет создать в исходном файле данных новую переменную, распределяющую респондентов на целевые группы. Выберите параметр Single Solution и укажите в соответствующем поле необходимое количество кластеров — 16 (определено на первом этапе кластерного анализа). Щелкнув на кнопке Continue, вернитесь в главное диалоговое окно, в котором щелкните на кнопке ОК, чтобы запустить процедуру кластерного анализа.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
