
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
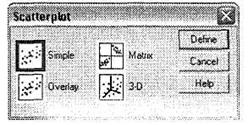 |
Диалоговое окно Linear Regression имеет встроенное средство для построения графиков — кнопку Plots. Однако это средство, к сожалению, не позволяет на одном графике построить две переменные: S, и So - Для того чтобы построить тренд, необходимо использовать меню Graphs ► Scatter. На экране появится диалоговое окно Scatterplot (рис. 4.32), которое служит для выбора типа диаграммы. Выберите вид Simple. Максимально возможное число независимых переменных, которое можно изобразить графически, — 2. Поэтому при необходимости графического построения зависимости одной переменной (зависимой) от двух независимых (например, если бы в нашем распоряжении были данные не по двум, а по трем годам), в окне Scatterplot следует выбрать 3-D. Схема построения трехмерной диаграммы рассеяния не имеет существенных отличий от описываемого способа построения двухмерной диаграммы.
|
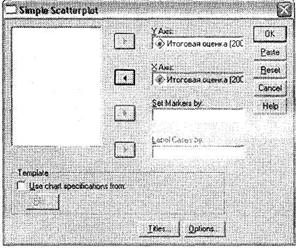
После щелчка на кнопке Define на экране появится новое диалоговое окно, представленное на рис. 4.34. Поместите в поле Y Axis зависимую переменную (Итоговая оценка 2001), а в поле X Axis — независимую (Итоговая оценка 2000). Щелкните на кнопке 0 К, что приведет к построению диаграммы рассеяния.
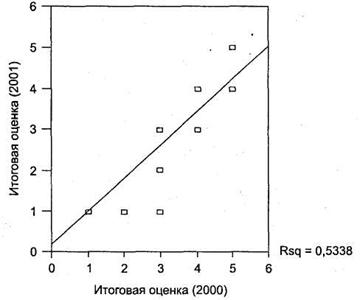
Для того чтобы построить линию тренда, дважды щелкните мышью на полученной диаграмме; откроется окно SPSS Chart Editor. В этом окне выберите пункт меню Chart ► Options; далее пункт Total в области Fit Line; щелкните на кнопке Fit Options. Откроется диалоговое окно Fit Line, выберите в нем тип аппроксимирующей линии (в нашем случае Linear regression) и пункт Display R-square in legend. После закрытия окна SPSS Chart Editor в окне SPSS Viewer появится линейный тренд, аппроксимирующий наши наблюдения по методу наименьших квадратов. Также на диаграмме будет отражаться величина R2, которая, как было сказано выше, обозначает долю совокупной вариации, описываемой данной моделью (рис. 4.35). В нашем примере она равна 53 %.
 |
С линейным регрессионным анализом связано множество интегральных показателей, рассчитываемых на основании коэффициентов регрессии (чаще всего стандартизированных). В качестве примера приведем расчет коэффициента потребительской привлекательности продукта/марки (Consumer Attractiveness), или коэффициента СА.
|
 |
|
Этот коэффициент вводится в маркетинговых исследованиях для удобства сравнения привлекательности для респондентов анализируемых продуктов/марок. В анкете должны присутствовать вопросы типа Оцените представленные параметры продукта/ марки X, в которых респондентам предлагается дать свои оценки частным параметрам продукта или марки X, скажем, по пятибалльной шкале (от 1 — очень плохо до 5 — отлично). В конце списка оцениваемых частных параметров респонденты должны поставить итоговую оценку продукту/марке X. При анализе полученных в ходе опроса ответов респондентов на основании оценок респондентов формируются:
■ матрица средневзвешенных оценок по параметрам продукта/марки;
■ список стандартизированных ![]() - коэффициентов регрессии (оценка влияния частных параметров продукта/марки X на его/ее общую оценку).
- коэффициентов регрессии (оценка влияния частных параметров продукта/марки X на его/ее общую оценку).
Далее коэффициент СА рассчитывается по следующей формуле:
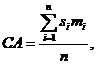
где n — число параметров, формирующих итоговую оценку продукта или марки:
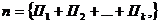
![]() - — значимость для респондентов параметра с индексом i (стандартизированный
- — значимость для респондентов параметра с индексом i (стандартизированный ![]() -коэффициент регрессии, оценивающей влияние частных параметров на общую оценку продукта/марки, подробнее см. выше);
-коэффициент регрессии, оценивающей влияние частных параметров на общую оценку продукта/марки, подробнее см. выше); ![]() — уровень средневзвешенной оценки продукта/марки по параметру с индексом i (при наличии пятибалльной шкалы):
— уровень средневзвешенной оценки продукта/марки по параметру с индексом i (при наличии пятибалльной шкалы):
![]() = 2 при высоком уровне оценки (средневзвешенный балл ≥ 4,5)
= 2 при высоком уровне оценки (средневзвешенный балл ≥ 4,5)
![]() = 1 при среднем уровне оценки (средневзвешенный балл ≥4,0 и < 4,5)
= 1 при среднем уровне оценки (средневзвешенный балл ≥4,0 и < 4,5)
![]() = -1 при низком уровне оценки (средневзвешенный балл ≥3,0 и < 4,0)
= -1 при низком уровне оценки (средневзвешенный балл ≥3,0 и < 4,0)
![]() = -2 при неудовлетворительной оценке (средневзвешенный балл < 3,0)
= -2 при неудовлетворительной оценке (средневзвешенный балл < 3,0)
Рассчитанный для каждого конкурирующего продукта/марки коэффициент СА показывает его/ее относительную позицию в структуре потребительских предпочтений. Данный интегральный показатель учитывает уровень оценок по каждому параметру, скорректированный на их значимость. При этом он может изменяться в пределах от -1 (наихудшая относительная позиция среди всех рассматриваемых продуктов/марок) до 1 (наилучшее положение); 0 означает, что данный продукт/ марка ничем особенным не выделяется в глазах респондентов.
Итогом расчета коэффициента СА является рейтинг конкурентов по данному показателю. На основании рейтинга можно сделать важные выводы относительно лидерства и аутсайдерства конкретных продуктов/марок на потребительском рынке.
Мы завершаем рассмотрение ассоциативного анализа. Данная группа статистических методов применяется в отечественных компаниях в настоящее время достаточно широко (особенно это касается перекрестных распределений). Вместе с тем хотелось бы подчеркнуть, что только лишь перекрестными распределениями ассоциативные методы не ограничиваются. Для проведения действительно глубокого анализа следует расширить спектр применяемых методик за счет методов, описанных в настоящей главе.
Глава 5. Классификационный анализ
Цель классификационного анализа — классификация респондентов и/или переменных по определенным целевым группам. Наиболее распространенными примерами использования классификационного анализа в маркетинговых исследованиях являются:
■ сегментирование респондентов по заранее известным (логистическая регрессия и дискриминантный анализ) или не известным (факторный и кластерный анализ) целевым группам;
■ классификация переменных по макрокатегориям, то есть сокращение их числа до нескольких значимых групп (факторный и кластерный анализ).
Далее в разделе мы рассмотрим эти статистические методики в указанном порядке, а также приведем примеры задач из практики маркетинговых исследований, решаемых с помощью классификационного анализа.
5.1. Логистическая регрессия и дискриминантный анализ
Логистическая регрессия и дискриминантный анализ применяются в том случае, когда необходимо классифицировать (сегментировать) респондентов по целевым группам, которые, в свою очередь, представлены уровнями (вариантами ответа) одной одновариантной переменной.
Примером задачи, решаемой при помощи этих статистических методов, может служить задача классифицировать респондентов по двум группам — покупающие горчицу и не покупающие горчицу — на основании их социально-демографических характеристик (пол, возраст, доход, количество членов семьи и т. п.). Как вы видите, в процедурах логистической регрессии и дискриминантного анализа присутствуют переменные — критерии сегментирования и одна переменная, кодирующая целевые группы, на которые следует разделить респондентов на основании критериев сегментирования.
Необходимо отметить, что спектр возможностей применения логистической регрессии уже, чем для дискриминантного анализа, поэтому использование дискриминантного анализа в качестве универсального метода предпочтительнее. Боле того, рекомендуется всегда начинать классификационное исследование именно с дискриминантного анализа, а не с логистической регрессии, — и применять последнюю в случае неуверенности в результатах дискриминантного анализа. Это связано, в частности, с тем, что при применении методов логистической регрессии еле дует четко представлять, какой тип имеют зависимая и независимые переменные и, исходя из этого, выбирать одну из трех возможных процедур логистической регрессии: бинарную, мультиномиальную или порядковую. При дискриминантном анализе мы всегда имеем дело только с одной статистической процедурой, в которой принимают участие одна категориальная зависимая переменная и несколько независимых переменных с любым типом шкалы. Таким образом, дискриминантный анализ является более универсальной методикой (что особенно важно для исследователей, имеющих незначительный опыт в статистическом анализе данных).
В разделах 5.1.1 и 5.1.2 мы на конкретных примерах покажем, как молено использовать процедуры логистической регрессии и дискриминантного анализа в маркетинговых исследованиях. При этом мы увидим, что, несмотря на преимущества универсального дискриминантного анализа, логистическая регрессия в некоторых случаях дает наивысшую четкость классификации.
5.1.1. Бинарная и мультиномиальная логистические регрессии
В настоящем разделе мы рассмотрим два основных типа логистической регрессии — бинарную и мультиномиальную, а также дадим общий обзор порядковой логистической регрессии. Цель статистического анализа при применении методов логистической регрессии — определить вероятность того, что тот или иной респондент (на основании определенных характеристик) попадет в ту или иную целевую группу. На практике описываемые методы, согласно значениям одной или нескольких независимых переменных (факторов), позволяют классифицировать респондентов по двум (бинарная) или более (мультиномиальная) группам, которые выражаются уровнями (вариантами ответа) какой-либо одной переменной.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
