
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Таким образом, вы видите, что графики в дисперсионном анализе являются весьма ценным ресурсом для построения заключений и выводов. Еще одним направлением интерпретации является кластеризация респондентов на основании их средних показателей (например, кратности покупок). Так, в нашем примере на основании кратности покупок можно разделить всех респондентов на следующие целевые сегменты:
1. мужчины младше 18 лет характеризуются наименьшей кратностью покупок сырков;
2. мужчины старше 36 лет и женщины старше 19 лет характеризуются средней кратностью покупок сырков;
3. мужчины от 19 до 35 лет и женщины младше 18 лет характеризуются наивысшей кратностью покупок сырков.
В целом общая схема интерпретации графиков в дисперсионном анализе состоит из двух этапов. Сначала следует определить категории респондентов, отличающиеся и не отличающиеся друг от друга. При этом интерпретация графиков всегда происходит только по двум переменным (представленным по горизонтальной оси и в виде отдельных линий). Для установления различия следует смотреть на форму данных линий. Если две (или более) линии близки к параллели, следовательно, различия между данными категориями минимальны (незначимы). В противном случае, если линии пересекаются, следует признать различие между ними существенным (значимым).
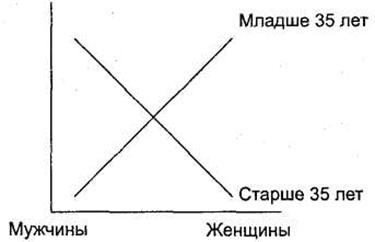 |
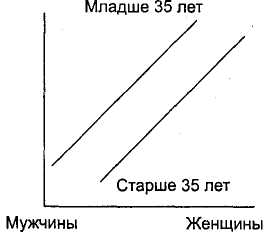
Наиболее простым для интерпретации случаем является ситуация, в которой по горизонтальной оси располагается дихотомическая переменная (например, переменная Пол). Если линии на отрезке между двумя категориями данной переменной не пересекаются — различий нет; если пересекаются — различия есть. На рис. 3.22 представлен пример максимальных различий (линии пересекаются под прямым углом); на рис. 3.23 — минимальных (линии параллельны).
|
|
 |
Можно сформулировать следующие рекомендации по построению графиков в дисперсионном анализе.
1. Для горизонтальной оси лучше выбирать дихотомические вопросы.
2. Если дихотомических переменных нет, следует выбрать переменную с наименьшим четным количеством категорий и перекодировать данные категории в дихотомию. Для горизонтальной оси следует выбирать именно данную (уже дихотомическую) переменную. Данный способ работает далеко не всегда, ведь часто различия между взаимодействиями факторов находятся именно в тех категориях, которые будут перекодированы (сокращены).
При исследовании трехуровневых взаимодействий (ql x q2 x q3) переменную с наименьшим числом категорий (лучше дихотомическую) следует поместить в поле Separate Plots в диалоговом окне Univariate (например, ql), а для остальных двух исследуемых переменных (например, q2 и q3) — следовать вышеописанным правилам. Это будет означать, что в результате будут построены отдельные графики по каждой категории переменной ql, где будут показаны двухуровневые взаимодействия переменных q2 и q3.
В заключение настоящего раздела необходимо особо отметить, что графики взаимодействий могут эффективно применяться только при числе взаимодействий 2 (ql х q2) или 3 (ql x q2 x q3). При взаимодействиях первого уровня (ql) мы говорим уже не о взаимодействиях как таковых, а о главных эффектах (Main effects), то есть о влиянии на зависимую переменную только каждого фактора в отдельности. В таком случае различия между конкретными группами независимой переменной определяются исходя из результатов апостериорных тестов. При числе взаимодействий более трех сохраняется возможность разбиения данного взаимодействия на несколько взаимодействий второго или третьего уровней и построения затем серии графиков. Однако в этом случае интерпретация данных графиков является практически неразрешимой задачей.
3.2.2. Одномерный дисперсионный анализ с повторными
измерениями
Одномерный дисперсионный анализ с повторными измерениями (ANOVARM) является расширением одномерного дисперсионного анализа (ANOVA). Цель его заключается в анализе различий между ответами одних и тех же респондентов на одни и те же вопросы в несколько приемов, то есть в течение ряда дискретных временных промежутков.
В качестве примера можно привести панельные исследования, когда одни и те же респонденты (потребители какого-либо продукта) отвечают на одни и те же вопросы через определенные интервалы времени (скажем, каждый квартал). Одной из основных целей дисперсионного анализа в рассматриваемом случае будет оценка влияния на ответы респондентов временного фактора. Таким образом, в частности, можно установить уровень лояльности к продуктам различных марок: если с течением времени средние оценки продукта марки X существенно не меняются/ возрастают/убывают, следовательно, и отношение респондентов к данной марке сохраняется на прежнем уровне/улучшается/ухудшается. Иными словами, дисперсионный анализ с повторными измерениями может применяться для оценки значимости тенденций.
В маркетинговых исследованиях этот тип статистического анализа находит весьма разнообразные применения. Он может применяться не только в процессе анализа баз данных по маркетинговым исследованиям, но и в процессе сбора анкет — для контроля работы интервьюеров. Например, если опрос производится каждый
день в течение недели в одних и тех же местах, можно анализировать средние значения основных переменных, во-первых, по дням недели, а во-вторых, по каждому интервьюеру. Если будут выявлены существенные различия в анкетах интервьюеров, то высока вероятность фальсификации (тем интервьюером, анкеты которого наиболее сильно отличаются от остальных).
Необходимо сделать важное отступление. Дело в том, что некоторые источники иногда относят анализ с повторными измерениями к одномерному, а иногда — к многомерному дисперсионному анализу. В справочной системе SPSS не указана явно принадлежность ANOVARM к одной или другой группе статистических методов. По сути расчетов ANOVARM близок к многомерному дисперсионному анализу, поскольку в качестве зависимой переменной выступают сразу несколько переменных, кодирующих ряд временных периодов. Но так как основная задача данного пособия — объяснение практических приемов работы с SPSS для эффективного применения этого программного продукта в маркетинговых исследованиях, мы отдаем предпочтение семантическому толкованию статистических терминов. Зависимые переменные в ANOVARM по смыслу (с точки зрения исследователя) представляют собой фактически одну и ту же переменную, только измеренную многократно. В этой трактовке следует скорее говорить о специфической форме одномерного дисперсионного анализа, в котором зависимая переменная представлена набором подпеременных (точно так же, как при кодировании многовариантных вопросов; см. раздел 1.4.2). Таким образом, мы придерживаемся точки зрения тех авторов, которые считают ANOVARM видом одномерного дисперсионного анализа (ANOVA).
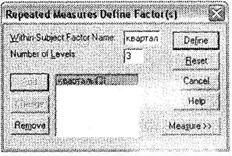
Итак, в качестве иллюстрации использования одномерного дисперсионного анализа с повторяющимися измерениями рассмотрим следующий пример. Проводится исследование мнений респондентов относительно одежды марки X. Одним из вопросов анкеты является следующий: Поставьте оценку одежды марки X по пятибалльной шкале (от 1 — очень плохо до 5 — отлично). Респонденты разделяются на группы по полу и возрасту. Исследование проводится с частотой раз в квартал в течение года. В результате в итоговой базе данных получены три переменные: ql8, ql9 и q20, отражающие уровень оценки респондентами одежды марки X в первом, втором и третьем кварталах, а также две переменные, указывающие пол (q80) и возраст (q74) опрошенных. Требуется установить, как меняется общая картина восприятия респондентами одежды марки X в течение одного года. Поставленная задача легко решается методом одномерного дисперсионного анализа с повторяющимися измерениями. Откройте диалоговое окно Repeated Measures Define Factor(s) при помощи меню Analyze ► General Linear Model ► Repeated Measures (рис. 3.24). Это диалоговое окно предназначено для формирования временных факторов, то есть определения составных переменных, описывающих эти факторы. У нас есть три временных интервала (квартала), поэтому в поле Within-Subject Factor Name напишите название этой составной переменной: кварталы, а в поле Number of Levels — число временных периодов, когда производились измерения (3 квартала). После этого щелкните на кнопке Add, чтобы добавить новую составную переменную в список. Таким способом можно задать сразу несколько составных временных переменных, однако в маркетинговых ис
 |
следованиях в большинстве случаев ограничиваются только одной.
|
Кнопка Measure служит для задания дополнительных измерений временных переменных, но в маркетинговых исследованиях эта функция обычно не используется.
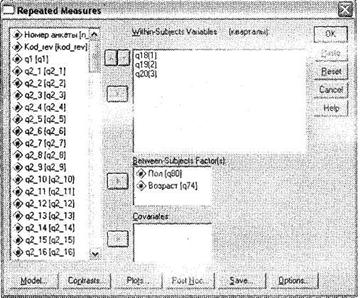 |
Щелкните на кнопке Define, и откроется новое диалоговое окно Repeated Measures (рис. 3.25), похожее (как по внешнему виду, так и по своим функциям) на окно Univariate. В этом окне в левом списке всех доступных переменных выберите те, в которых закодированы оценки респондентов в каждый из временных промежутков (в нашем случае — ql8, ql9, q20), и последовательно (то есть в порядке возрастания периодов) перенесите их в область Within-Subjects Variables (кварталы).

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
