
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Ниже мы рассмотрим перечисленные типы коэффициентов корреляции более подробно на практических примерах из маркетинговых исследований.
4.2.1. Исследование линейных корреляций по Пирсону, Спирману и Кендалу
Сначала мы рассмотрим пример применения коэффициента корреляции Пирсона. Предположим, что у нас есть ответы респондентов на следующие два вопроса. Каков Ваш среднемесячный доход в расчете на одного члена семьи? с вариантами ответа:
■ до $100;
■ от $ 100 до $ 300;
■ от $ 300 до $ 600;
■ от $ 600 до $ 1000;
■ от $ 1000 до $ 1500;
■ свыше $1500.
Как часто Вы посещаете рестораны? с вариантами ответа:
■ более 1 раза в день;
■ примерно 1 раз в день;
■ 2-3 раза в неделю;
■ примерно 1 раз в неделю;
■ 2-3 раза в месяц;
■ примерно 1 раз в месяц;
■ реже 1 раза в месяц.
В результате ввода в компьютер заполненных анкет респондентов были получены две переменные: q3 (первый вопрос) и q28 (второй вопрос). Необходимо установить, зависит ли частота посещения ресторанов от дохода респондентов, и если да, то каким образом. В связи с тем, что в ходе опроса при ответе на каждый вопрос респондентам предлагалось на выбор несколько вариантов ответа, тип шкалы у полученных переменных получился порядковым (в файле данных есть только коды ответов, но не сами числовые значения, отражающие частоту посещения ресторана или уровень дохода).
Далее мы рассмотрим не только как использовать коэффициент корреляции Пирсона, но также как использовать данный коэффициент для анализа квазипорядковых переменных. Дело в том, что некоторые переменные, хотя они и закодированы как порядковые, по сути являются интервальными (как в нашем случае). Это делается специально, чтобы, с одной стороны, увеличить долю респондентов, ответивших на вопрос, а с другой стороны, уменьшить число возможных ошибок при вводе в компьютер текстовых полей (для открытых вопросов). Интервалы также полезны при анализе, поскольку нет необходимости кодировать текстовые (или интервальные) переменные, а можно сразу увидеть группы (интервалы) значений. Практика показывает, что подобное составление анкет для маркетинговых исследований является стандартным, поэтому корреляционный анализ редко проводится на изначально интервальных переменных (текстовые поля анкеты).
Для описываемых квазипорядковых переменных следует применять именно коэффициент корреляции Пирсона. Использование коэффициентов Спирмана или Кендала в этом случае является некорректным. Более подробно эти два коэффициента представлены ниже; пока же в общих чертах о них можно сказать следующее. Коэффициенты Спирмана или Кендала показывают только степень соответствия порядка следования вариантов ответа в ранжированных списках (есть отсутствие инверсий). При этом корреляции по Спирману и Кендалу используются в основном, когда элементы ранжированных списков представлены мнемоническими, а не числовыми константами. Таким образом, данные коэффициенты не помогут нам в характеристике зависимости между частотой посещения ресторанов и доходом респондентов. Однако в нашем случае нельзя применять и коэффициент корреляции Пирсона, так как в этом случае анализировались бы коды интервалов (1 -6 — в первом вопросе и 1 -7 — во втором), а не действительные ответы респондентов на вопросы1.
Итак, сначала мы должны преобразовать имеющиеся у нас порядковые переменные к интервальному виду. Лучше всего сделать это при помощи замены кодов интервалов (1-6) на средние значения данных интервалов. Например, среднее значение для интервала 3 в переменной q3 — это $ 450 (450 = (300 + 600) / 2). Преобразовав обе переменные к данному виду, мы получим следующие интервальные переменные q3_i и q28_i (табл. 4.5)2.
Таблица 4.5. Схема перекодировки порядковых переменных (q3 и q28) в интервальные (q3_i и q28_i)
Порядковые переменные | Интервальные переменные |
Каков Ваш среднемесячный доход в расчете на одного члена семьи? | |
до $ 100 | $50 |
от $ 100 до $ 300 | $200 |
от $ 300 до $ 600 | $450 |
от $ 600 до $ 1000 | $ 800 |
от $ 1000 до $ 1500 | $ 1250 |
свыше $ 1500 | $ 1750 |
Как часто Вы посещаете рестораны? | |
более 1 раза в день | 60 раз в месяц |
примерно 1 раз в день | 30 раз в месяц |
2-3 раза в неделю | 10 раз в месяц |
примерно 1 раз в неделю | 4 раза в месяц |
2-3 раза в месяц | 2,5 раза в месяц |
примерно 1 раз в месяц | 1 раз в месяц |
реже 1 раза в месяц | 0,5 раза в месяц |
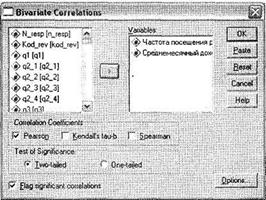 |
Теперь мы можем приступить непосредственно к корреляционному анализу (описанию зависимости между частотой посещения ресторанов и уровнем дохода). Для этого выберите пункт меню Analyze ► Correlate ► Bivariate. В открывшемся диалоговом окне (рис. 4.17) выберите в левом списке всех доступных переменных две интересующие нас (q3_i и q28_i) и перенесите их в область Variables. Остальные параметры в этом диалоговом окне, установленные по умолчанию, следует оставить неизменными: вывод коэффициентов корреляции Пирсона (параметр Pearson в области Correlation Coefficients) и статистической значимости коэффициентов (параметр Two-tailed в области Test of Significance). Кнопка Options не предлагает исследователю каких-либо существенных параметров. Чтобы запустить процедуру построения корреляционной таблицы, щелкните на кнопке ОК.
|
В окне SPSS Viewer появится таблица Correlations с результатами расчетов коэффициента корреляции Пирсона и статистической значимости данного коэффициента. Как видно из рис. 4.18, в нашем случае коэффициент корреляции Пирсона между двумя исследуемыми переменными (q3_i и q28_i) равен +0,665, а его статистическая значимость меньше 0,001. Следовательно, можно сделать вывод о том, что между среднемесячным доходом респондентов и частотой посещения ими ресторанов существует статистически значимая умеренная (средняя) линейная возрастающая зависимость. То есть частота посещения ресторанов в достаточно высокой степени (коэффициент Пирсона = 0,7) зависит от уровня доходов потребителей, причем при росте среднемесячного дохода частота посещения ресторанов линейно возрастает.
Существует возможность проводить корреляционный анализ сразу для нескольких переменных. Для этого необходимо поместить эти переменные в область Variables диалогового окна Bivariate Correlations. В таблице Correlations будут показаны коэффициенты корреляции для каждой пары исследуемых переменных.
Теперь рассмотрим процедуру проведения корреляционного анализа при помощи ранговых коэффициентов Спирмана и Кендала. В данных методах одна переменная (эталонная) представлена в виде ранжированной последовательности мнемонических категорий, а другой переменной присваиваются ранговые места. Корреляционные коэффициенты рассчитываются исходя из количества инверсий, то есть числа нарушений порядка следования рангов по сравнению с первым рядом. В большинстве случаев рекомендуется применять коэффициент корреляции Спирмана. Использование коэффициента Кендала оправдано только в том случае, когда в структуре данных имеются выбросы.
 |
|
В практике маркетинговых исследований наиболее часто коэффициенты корреляции Спирмана применяются для анализа не всей выборочной совокупности респондентов (базы данных в целом), а агрегированных ранжированных перечней, полученных в результате других преобразований1. Приведем пример. Предположим, что в результате опроса посетителей магазинов одежды были получены ответы на следующие два вопроса. Какие факторы для Вас наиболее важны при выборе одежды? с вариантами ответа:
■ Высокое качество одежды.
■ Доступные цены.
■ Широта ассортимента одежды.
■ Близость к дому или работе.
■ Высокое качество обслуживания.
■ Красивый интерьер магазина.
Оцените, пожалуйста, следующие характеристики данного магазина одежды (в котором происходит опрос) по пятибалльной шкале (от 1 — очень плохо до 5 — отлично) с вариантами ответа:
■ Высокое качество одежды.
■ Доступные цены.
■ Широта ассортимента одежды.
■ Близость к дому или работе.
■ Высокое качество обслуживания.
■ Красивый интерьер магазина.
■ Ваша общая оценка работы данного магазина.
Над результатами второго вопроса был проведен множественный линейный регрессионный анализ. Анализировалось влияние оценок частных параметров всех исследованных магазинов одежды на их общую оценку. В разделе 4.3 подробно рассматривается процедура линейного регрессионного анализа, позволяющая, в частности, построить ранжированный перечень частных параметров по силе их влияния на общую оценку.
Таким образом, были получены два ранжированных списка с одинаковыми категориями: две схемы выбора магазина одежды. Затем оба списка были введены в SPSS под кодами, представленными выше: от 1 (наиболее важный фактор) до 6 (наименее важный фактор) (рис. 4.19). На рис. 4.20 представлены данные списки в мнемонической форме. Первый список представлен в переменной sc_l; второй — в sc_2.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
