
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
|
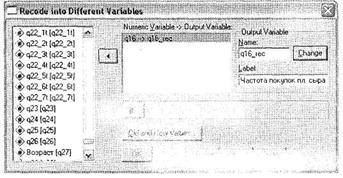 |
Введите в соответствующие поля название и метку новой переменной. Обратите внимание, что в описываемом диалоговом окне также есть кнопка условного отбора данных If. Откройте диалоговое окно Old and New Values, щелкнув на одноименной кнопке (рис. 1.23).
|
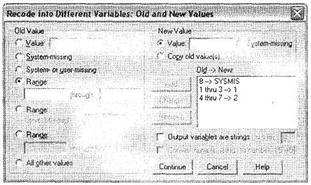 |
Это окно напоминает окно, представленное на рис. 1.21, но в нем также содержатся некоторые дополнительные полезные инструменты. По умолчанию значения исходной переменной, не указанные в списке перекодировки, не попадают в новую переменную. Изменить данное условие по умолчанию можно при помощи параметра Сору old value(s). Также появилась возможность конвертации числовых значений в строковые (параметр Output variables are strings). При этом изменится тип всей новой переменной; следовательно, все исходные значения должны быть перекодированы как
строковые. Существует и обратная возможность — конвертации строковых значений, похожих на цифры, в числовой вид (например, «5» в 5). Данная возможность реализуется при помощи параметра Convert numeric strings to numbers.
В нашем случае мы при помощи параметра Range перекодировали значения исходной переменной — от 1 до 3 — в 1, от 4 до 7 — в 2, а значение 8 — в System Missing. После щелчков в соответствующих диалоговых окнах на кнопах Continue и ОК будет создана новая переменная ql6_rec, содержащая перекодированные по указанной схеме значения переменной ql6.
1.5.3.3. Автоматическое перекодирование
Данная процедура предназначена для автоматического кодирования полей анкеты числовыми значениями типа индекс. В маркетинговых исследованиях эта процедура применяется в основном для текстовых полей в тех случаях, когда в анкете есть либо открытые вопросы (являющиеся текстовыми переменными в базе данных), либо варианты ответа Другое с дополнительным полем для указания респондентом конкретного варианта.
При выполнении процедуры одинаковые ответы из текстовых полей группируются, и им присваиваются соответствующие коды ответа (например, начиная с 1). Для того чтобы автоматическое перекодирование имело практический смысл, необходимо жестко формализовать ответы респондентов в текстовых полях. Если при заполнении анкет допускалась свободная формулировка респондентами своих ответов, следует перед вводом анкет в компьютер (или на этапе ввода) переформулировать их в соответствии с требованиями формализации. Меньшее количество различных вариантов ответа на открытый вопрос является предпочтительным, так как в дальнейшем при построении распределений большое число категорий трудно читается на графиках и в таблицах. Еще одно существенное требование к ответам респондентов на открытые вопросы — это достаточное количество респондентов в каждой группе ответов. Варианты ответов, указанные малым числом опрошенных, обычно относятся к варианту Другое.
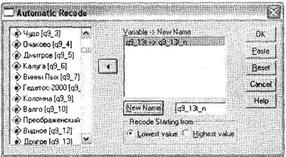
Диалоговое окно Automatic Recode (рис. 1.24) вызывается при помощи меню Transform ► Automatic Recode. В нашем примере мы задавали респондентам вопрос Какие марки глазированных сырков Вы знаете?. После списка основных конкурентов на данном рынке в анкете был вариант ответа Другое (переменная q9_13t), в который записывались компании-производители, не вошедшие в данный перечень. Закодируем эти марки числовыми значениями (вместо текстовых полей). Для этого следует перенести из левого списка всех доступных переменных интересующую нас текстовую переменную q9_13t в область Variable ► New Name и в соответствующем поле указать новое имя вновь создаваемой числовой переменной q9_13t_n. Затем, чтобы подтвердить преобразование, необходимо щелкнуть на кнопке New Name. В группе переключателей Recode Starting from есть два параметра, позволяющие присвоить номера вариантам ответа либо по алфавиту, начиная с самого малого значения (Lowest value), либо начиная с конца упорядоченного списка вариантов ответа (Highest value).
После щелчка на кнопке ОК и выполнения указанных преобразований в базе данных будет создана новая числовая переменная (q9_13t_n) с вариантами ответа согласно списку перекодировки. Список также выводится SPSS (в окне SPSS Viewer), он показан на рис. 1.25.
|
 |
 |
|
Как видно на рисунке, список разделен на три части: слева находятся значения исходной переменной (q9_13t); в среднем столбце расположены коды, под которыми данные текстовые значения представляются в новой переменной (q9_13t_n); правый столбец дублирует левый. Теперь по вновь созданной числовой переменной можно строить графики, а также использовать ее в других статистических процедурах.
1.5.4. Вычисление новых переменных
Вычисление новых переменных — весьма полезная возможность SPSS. При помощи данной функции можно производить расчеты по формулам любой сложности, задаваемым пользователем.
1.5.4.1. Вычисление новых переменных
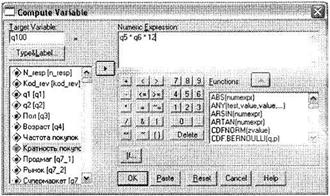
Кроме перекодирования переменных, SPSS позволяет создавать новые переменные, содержащие либо совершенно новые значения, либо значения, вычисленные на основании существующих переменных. Таким образом действует процедура Compute Variable, вызываемая при помощи меню Transform ► Compute (рис. 1.26).
В качестве примера мы рассчитаем годовой объем закупок сметаны на основании имеющихся данных о частоте покупок данного продукта в месяц (интервальная переменная q5) и кратности покупок (интервальная переменная q6).
|
 |
В поле Target Variable мы указали имя вновь создаваемой переменной, которая будет содержать вычисленные для каждого респондента годовые объемы покупок сметаны. Далее щелкните на кнопке Type&Label и укажите метку и ее тип (рис. 1.27). В нашем случае в качестве метки в поле Label мы указали Годовой объем закупок сметаны. Новая переменная будет содержать числовые значения, поэтому мы выбрали тип Numeric.
 |
|
После определения новой переменной в области Numeric Expression следует указать непосредственно рассчитываемое выражение. В нашем случае мы умножаем частоту покупок (q5) на кратность покупок (q6) и затем умножаем на 12 месяцев, чтобы получить объем покупок сметаны в год. После запуска процедуры вычисления новой переменной будет создана новая переменная q100, содержащая годовые объемы покупок сметаны каждым респондентом в выборке.
1.5.4.2. Подсчет значений переменных
Еще одной полезной возможностью SPSS, не рассмотренной при описании процесса модификации и отбора данных, является подсчет значений переменных (как правило, многовариантных).
Приведем пример. Предположим, у нас есть ответы респондентов на многовариантный вопрос Из каких источников Вы получаете информацию о рынке сантехники? с пятью вариантами ответа:
1. q22_l - газеты;
2. q22_2 — журналы;
3. q22_3 — выставки;
4. q22_4 — Интернет;
5. q22_5 — другие источники.
В результате работы описываемой процедуры мы получим новую переменную q100, в которой для каждого респондента в выборке будет отражаться количество используемых источников при поиске информации о рынке сантехники.
 |
Диалоговое окно Count Occurrences of Values within Cases, позволяющее выполнить поставленную задачу, открывается при помощи меню Transform ► Count (рис. 1.28). В полях Target Variable и Target Label следует указать соответственно имя вновь создаваемой переменной (q100) и ее метку (Количество используемых источников). В область Numeric Variables помещаются интересующие нас переменные q22_l - q22_5, значения которых необходимо подсчитать.
|
Диалоговое окно Count Occurrences of Values within Cases так же, как и многие другие окна SPSS, содержит кнопку If, позволяющую осуществить расчеты не для всех респондентов в выборке, а только для отдельных групп.
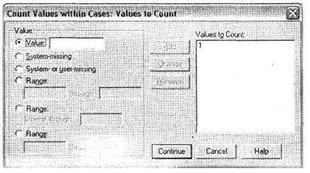
Щелкните на кнопке Define Values. Открывшееся диалоговое окно (рис. 1.29) предназначено для указания конкретных значений рассматриваемых переменных, подлежащих подсчету. Так как у нас есть пять дихотомических переменных, соответствующих вариантам ответа на многовариантный вопрос, мы указали 1 в качестве объекта подсчетов.
 |

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
