
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Таблиця 7.8 Результати імітації випадкового числа ![]() .
.
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 0,737169 | 0,629109 | 0,692591 | 0,145206 | 0,281038 | 0,287717 | 0,877255 |
| 3 | 3 | 3 | 1 | 2 | 2 | 3 |
ІІ. Імітація нормально розподіленого неперервного випадкового числа.
Нехай ![]() - реалізація випадкового числа, рівномірно розподіленого на відрізку [0,1] з дисперсією
- реалізація випадкового числа, рівномірно розподіленого на відрізку [0,1] з дисперсією 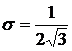 . Слід генерувати послідовність нормально розподілених випадкових величин
. Слід генерувати послідовність нормально розподілених випадкових величин ![]() з середнім значенням
з середнім значенням ![]() і дисперсією
і дисперсією ![]() . Для цього використовується апарат теорії імовірності. Відомо, що сума рівномірно розподілених випадкових величин
. Для цього використовується апарат теорії імовірності. Відомо, що сума рівномірно розподілених випадкових величин ![]() при великих значеннях
при великих значеннях ![]() близька до числа з нормальним законом розподілу при середньому значенні
близька до числа з нормальним законом розподілу при середньому значенні ![]() і дисперсією
і дисперсією ![]() . Щоб отримати необхідну для нас послідовність, залишається тільки провести наступне перетворення:
. Щоб отримати необхідну для нас послідовність, залишається тільки провести наступне перетворення:
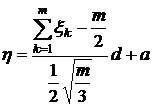
ІІІ. Імітація послідовності випадкових величин, розподілених за показниковим законом, можлива при використанні формули зворотнього перетворення, так званий, метод зворотніх функцій [].
![]() ,
,
де ![]() - послідовність випадкових чисел, розподілених по показниковому закону, з параметром
- послідовність випадкових чисел, розподілених по показниковому закону, з параметром ![]() ,
, ![]() - послідовність випадкових чисел, рівномірно розподілених на інтервалі [0,1].
- послідовність випадкових чисел, рівномірно розподілених на інтервалі [0,1].
Аналіз результатів імітаційних експериментів
Звичайно, дуже важливо, скільки експериментів слід для цього провести на ЕОМ, якщо зауважити, що на один експеримент витрачається як час, так і необхідні ресурси.
Після проведення ![]() імітаційних експериментів (прогонів) стає питання аналізу їх результатів.
імітаційних експериментів (прогонів) стає питання аналізу їх результатів.
В першу чергу, це статистичний аналіз. Наприклад, відповісти на питання:
- знаходити середнє та середне-квадратичне відхилення (корінь з оцінки дисперсії) значення виходу для різних градацій факторів впливу.
- чи суттєвий вплив фактору на вихідну величину ОУ; для цього існує факторний дисперсійний експеримент.
- перевірка статистичних гіпотез, які є суттєвими для ПР про управлінський вплив на ОУ.
Ціллю дисперсійного аналізу (ДА) є перевірка статистичної значимості різниці між оцінками середнього різних груп.
Кількість експериментів для нього визначається рівнянням:
| (7.5) |
де ![]() - число проведених експериментів,
- число проведених експериментів, ![]() - число факторів,
- число факторів, ![]() - число рівнів (можливих значень) кожного фактору,
- число рівнів (можливих значень) кожного фактору, ![]() - число повторень.
- число повторень.
Так, для прикладу 7.2 маємо: ![]() . Але, звичайно, чим менше факторів можна використати для дослідження, тим краще. Тому, природньо виглядає задача мінімізації:
. Але, звичайно, чим менше факторів можна використати для дослідження, тим краще. Тому, природньо виглядає задача мінімізації:
| (7.6) |
при обмеженні на отримання необхідної інформації про модельну систему.
В залежності від кількості факторів, модель факторного експерименту (експериментальна модель) може буди однофакторною, двохфакторною, багатофакторною. Математична модель плану однофакторного експерименту визначається наступним рівнянням:
| (7.7) |
де ![]() - відповідь експериментальної моделі (наприклад, прибуток парку машин) при впливі і-го рівня фактору і j-тої повторності, А – загальний ефект всіх спостережень,
- відповідь експериментальної моделі (наприклад, прибуток парку машин) при впливі і-го рівня фактору і j-тої повторності, А – загальний ефект всіх спостережень, ![]() - вплив j-го рівня фактору,
- вплив j-го рівня фактору, ![]() - помилка спостережень, яка припускається розподіленою нормально з середнім значенням 0.
- помилка спостережень, яка припускається розподіленою нормально з середнім значенням 0.
Загальна варіація даних (значень ![]() ) – Q розподіляється на варіацію по градаціям фактору
) – Q розподіляється на варіацію по градаціям фактору ![]() , варіацію по повторенням
, варіацію по повторенням ![]() та варіацію залишку
та варіацію залишку ![]() :
:
| (7.8) |
Визначити кожну з варіацій можна по наступних формулах:
| (7.9) |
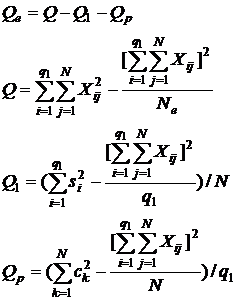 ,
,де ![]() - сума даних по повторностях для кожної градації факторів,
- сума даних по повторностях для кожної градації факторів, ![]() - сума даних по градаціям факторів для кожної повторності.
- сума даних по градаціям факторів для кожної повторності.
Степінь свободи для формул кожної варіації визначається відповідно:
| (7.10) |
За формулами (7.11) знаходяться дисперсії відповідних варіацій:
| (7.11) |
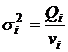 ,
,а також експериментальне значення статистичного F-критерію - ![]() як відношення і-тої дисперсії до залишкової дисперсії так, щоб у чисельнику знаходилася більша дисперсія.
як відношення і-тої дисперсії до залишкової дисперсії так, щоб у чисельнику знаходилася більша дисперсія.
Як відомо, відношення
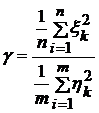
Суми квадратів незалежних нормально-розподілених величин ![]() називається розподілом Фішера-Снедекора з
називається розподілом Фішера-Снедекора з ![]() степенями свободи. (, , Теория вероятности и математическая статистика.-К.: «Выща школа», 1988.-439с.)
степенями свободи. (, , Теория вероятности и математическая статистика.-К.: «Выща школа», 1988.-439с.)
Анісімов В. В., І. Математична статистика.-Київ: МП «ЛЕСЯ», 1995.-104с.
Табличне значення критерію - ![]() з відповідними степенями свободи для чисельника і знаменника і для відповідного рівня значимості виводяться з таблиці (див. Додаток 1). Якщо
з відповідними степенями свободи для чисельника і знаменника і для відповідного рівня значимості виводяться з таблиці (див. Додаток 1). Якщо 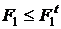 , тоді гіпотеза Н0 про несуттєвий вплив фактору приймається, інакше вона вважається невірною (фактор суттєво впливає на результат досліджень). Розглянемо однофакторний дисперсійний аналіз у прикладі 7.3.
, тоді гіпотеза Н0 про несуттєвий вплив фактору приймається, інакше вона вважається невірною (фактор суттєво впливає на результат досліджень). Розглянемо однофакторний дисперсійний аналіз у прикладі 7.3.
Приклад 7.3
Визначити суттєвість впливу кількості клієнтів на прибуток торгівельного пункту морозива за 1 час роботи, якщо є дані експериментів, проведених на імітаційній моделі (табл. 7.3).
Таблиця 7.3. Інформація за 1 час роботи торгівельного пункту морозива:
Число клієнтів | Повторення | |||
3 | 5,35 | 4,20 | 4,80 | 5,00 |
5 | 8,00 | 8,20 | 8,50 | 7,20 |
7 | 8,50 | 9,40 | 9,00 | 10,50 |
Кількість експериментів ![]() , кількість повторень
, кількість повторень ![]() , кількість градацій фактору
, кількість градацій фактору ![]() . Обчислимо необхідні значення:
. Обчислимо необхідні значення:

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 |
