Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
![]() Оценивается модель 3
Оценивается модель 3 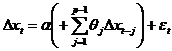
![]()
![]()
![]() Н0: j = 0 отвергается
Н0: j = 0 отвергается 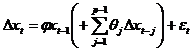
не отвергается
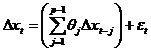
2. Эконометрический анализ макроэкономических динамических рядов
2.1. Статистическая база исследования
На данном этапе исследования основным критерием отбора временных рядов для эконометрического анализа являлась их доступность и наличие достаточного числа наблюдений, позволяющего использовать предложенную методологию анализа. В последующем предполагается проводить отбор рядов исходя из потребностей содержательных задач.
Для анализа были использованы данные о следующих макроэкономических показателях (в круглых скобках указаны рабочие названия соответствующих рядов):
Темпы прироста индекса потребительских цен (Inflation), % – месячные данные с 1991:01 по 2000:08;
Денежный агрегат M0 (M0), млрд. руб. (с 1998 г. млн. руб.) – месячные данные с 1990:12 по 2000:07;
Узкая денежная база (Denbaza), млрд. руб. (с 1998 г. млн. руб.) – месячные данные с 1992:05 по 2000:08;
Резервные деньги (Shirdenmas), млрд. руб. (с 1998 г. млн. руб.) – месячные данные с 1995:06 по 2000:07;
Денежный агрегат M1 (M1), млрд. руб. (с 1998 г. млн. руб.) – месячные данные с 1995:06 по 2000:07;
Денежный агрегат M2 (M2), млрд. руб. (с 1998 г. млн. руб.) – месячные данные с 1990:12 по 2000:07;
Широкие деньги (Shirdengi), млрд. руб. (с 1998 г. млн. руб.) – месячные данные с 1992:01 по 2000:07;
Объем экспорта (Export), млрд. долл. – месячные данные с1994:01 по 2000:04
Объем импорта (Import), млрд. долл. – месячные данные с 1994:01 по 2000:04;
Объем валового внутреннего продукта (GDP), млрд. руб. (с 1998 г. млн. руб.) – квартальные данные с 1994:1 по 2000:2;
Доходы федерального бюджета (Dokhfedbud), млрд. руб. (с 1998 г. млн. руб.) – месячные данные с1992:01 по 2000:05;
Налоговые доходы федерального бюджета (Dokhnalog), млрд. руб. (с 1998 г. млн. руб.) – месячные данные с 1992:01 по 2000:05;
Индекс интенсивности промышленного производства (Intprom) – сезонно скорректированные месячные данные с 1990:12 по 2000:07;
Фондовый индекс РТС-1 (RTS1) – дневные данные (значение закрытия) с 01/09/95 по 31/10/00;
Номинальный обменный курс руб./доллар (Rubkurs) – дневные данные с 01/07/92 по 01/11/00.
Общая численность безработных (на конец года), млн. человек (UNJOB) – месячные данные с 01/1994 по 08/2000.
Все исходные данные для эконометрического анализа приведены в приложениях П3.2–П3.9.
Общее представление о характере поведения перечисленных макроэкономических показателей дают графики изменения этих показателей (см. рис. 2-1 – 2-9).
 |
Рисунок 2-1. Инфляция

Рисунок 2-2. Денежные агрегаты

Рисунок 2-3. Экспорт и импорт

Рисунок 2-4. Объем валового внутреннего продукта
 |
Рисунок 2-5. Доходы
 |
Рисунок 2-6. Индекс интенсивности промышленного производства
 |
Рисунок 2-7. Индекс РТС1
 |
Рисунок 2-8. Обменный курс руб./долл.
 |
Рисунок 2-9. Безработица.
Как видно из приведенных выше графиков, большинство рядов развивается во времени неоднородным образом с выраженными сменами режимов. Вместе с тем, обнаруживается некоторая схожесть поведения денежных рядов, а также схожесть поведения налоговых рядов
Наличие у рядов выраженных трендов требует решения вопроса о том, являются ли эти тренды детерминированными или стохастическими, и изучение этого вопроса является исходным этапом анализа каждого ряда. Разумеется, было бы желательным построение модели, описывающей поведение ряда на всем периоде его наблюдения. Однако наличие смен режима эволюции рядов затрудняет построение такой единой модели, вследствие чего для некоторых рядов приходится строить различные модели эволюции ряда на различных интервалах (например, до и после августовского кризиса 1998 г.).
Как правило, при подборе моделей экономических временных рядов по годовым, квартальным, месячным и недельным данным можно ограничиться классом линейных моделей (случайное блуждание и модели ARIMA), тогда как использование дневных данных требует привлечения более сложных нелинейных моделей (ARCH, GARCH и их модификации, см., например, [Bollerslev (1986)], [Engle (1983)], [Engle, Granger (1991))]. Поэтому мы начнем анализ с исследования рядов с квартальными и месячными данными и только после этого перейдем к рядам с дневными данными.
2.2. Анализ временных рядов для денежных агрегатов
Мы уже обращали внимание на схожесть в общих чертах эволюции различных номинальных денежных агрегатов, порожденную инфляционным эффектом масштаба цен. Сходное поведение имеют следующие пары рядов:
· Наличные деньги (M0) и узкая денежная база (Denbaza);
· M2 и резервные деньги (Shirdengi);
· М1 и широкие деньги (Shirdenmas).
Поэтому ниже мы будем анализировать результаты только для одного из представителей каждой группы, а именно, ряды М0, М1 и М2.
Анализ временных рядов для денежных агрегатов мы начнем с денежного агрегата M1, поведение которого позволяет произвести анализ ряда на всем периоде его наблюдения, в отличие от денежных агрегатов M0 и M2.
2.2.1. Денежный агрегат М1
Денежный агрегат M1 – сумма денег вне банков и депозитов до востребования в банковской системе (без депозитов органов государственного управления), т. е. представляет собой все денежные средства в экономике страны, которые могут быть использованы как средство платежа.
В качестве исходной информации используются данные: денежный агрегат M1, млрд. руб. (с 1998 г. млн. руб.) – месячные данные с 1995:06 по 2000:07; источник – ЦБ РФ.
График ряда Xt = M1 имеет следующий вид[3]:
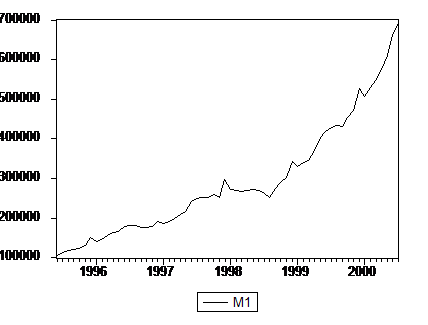
График показывает выраженный излом тренда ряда в конце 1998 – начале 1999 г., связанный с финансово-экономическим кризисом 1998 года, и сезонный характер изменений темпов увеличения денежного предложения, резкое увеличение денежной массы М1 в декабре, сменяющееся затем значительным изъятием денег из экономики в январе.
Проверку ряда М1 на принадлежность его классу DS процессов (остационариваемых путем дифференцирования) начнем с использования критерия Дики-Фуллера (его расширенного варианта). Хотя по графику видно, что ряд М1 имеет выраженный тренд, применим здесь для полноты процедуру Доладо и др.([Dolado, Jenkinson, Sosvilla-Rivero (1990)]), последовательно перебирающую различные комбинации оцениваемой статистической модели (SM) и процесса порождения данных (DGP).
На шаге 1 процедуры Доладо оценивается статистическая модель, допускающая наличие тренда, содержащая в правой части уравнения константу и трендовую составляющую:
SM: ![]()
и при использовании таблицы критических значений предполагается, что данные порождаются моделью
DGP: ![]()
Критерий принадлежности ряда классу DS формулируется как критерий единичного корня (UR – Unit Root) в авторегрессионном представлении ряда. Проверяемой в рамках данной статистической модели является гипотеза H0 : j = 0; альтернативная гипотеза HA : j < 0.
Ввиду наличия на коррелограмме ряда разностей пика на лаге 12, включим в правую часть оцениваемой статистической модели (помимо константы и тренда) 12 запаздывающих разностей. Получаемое в результате оценивания такой расширенной модели значение t-статистики критерия Дики-Фуллера 1.495 положительно и не позволяет отвергнуть гипотезу единичного корня (UR-гипотезу) в пользу гипотезы стационарного относительно линейного тренда ряда (5% и 10% критические значения указанной t-статистики в предположении, что данные порождаются моделью случайного блуждания со сносом, во всяком случае, отрицательны).
Попробуем повысить мощность критерия Дики-Фуллера путем исключения из правой части оцениваемого уравнения запаздывающих разностей со статистически незначимыми коэффициентами. Результаты последовательного исключения таких разностей приведены в следующей таблице.
Порядок запаздывания исключаемой разности | SC | P-val LM-автокорр. | P-val White | P-val J-B | t-статистика критерия |
– (полная модель с 12 запаздывающими разностями) | 22.492 | 1 – 0.208 2 – 0.316 | 0.341 | 0.964 | 1.495 |
5 | 22.413 | ||||
7 | 22.333 | ||||
2 | 22.255 | ||||
3 | 22.281 | ||||
4 | 22.105 | ||||
6 | 22.050 | ||||
8* | 22.030 | 1 – 0.595 2 – 0.851 | 0.116 | 0.699 | 2.085 |
11 | 22.037 | ||||
1 | 22.007 | ||||
10** | 21.976 | 1 – 0.689 2 – 0.410 | 0.119 | 0.484 | 0.850 |
В первом столбце таблицы указаны запаздывания разностей, последовательно исключаемых из правой части оцениваемой статистической модели. Запаздывающая разность исключается из уравнения, если коэффициент при этой разности признается статистически незначимым на 10% уровне значимости.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 |
 Основные порталы (построено редакторами)
Основные порталы (построено редакторами)