Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Наконец, если выбор даты излома тренда осуществляется по минимуму коэффициента при переменной DT, отвечающей за изменение наклона тренда, то выбирается опять 1998:04 с тем же выводом о неотвержении UR-гипотезы.
Рассмотрим теперь модель, допускающую только изменение наклона тренда без сдвига траектории в форме аддитивного выброса (AO). Результаты применения процедуры PERRON97 для этой модели таковы:
break date TB = 1999:02; statistic t(alpha=1) = -3.59417 | |||
critical values at | 1% | 5% | 10% |
for 100 obs. | -5.45 | -4.83 | -4.48 |
number of lag retained : 12 | |||
explained variable : M1 | |||
coefficient | student | ||
CONSTANT | 104939.65455 | 20.48279 | |
TIME | 4832.56930 | 26.73200 | |
DT | 14335.07564 | 21.11189 | |
M1 {1} | -0.75752 | -1.54915 |
(Заметим, что при постулировании аддитивного выброса оценивание регрессионной модели при каждой испытываемой дате производится в два этапа. На первом шаге в правую часть регрессионной модели в качестве объясняющих включаются только переменные CONST, TIME, DT; в результате оценивания этой модели получаем ряд остатков et.. На втором шаге оценивается модель регресии et на et-1 и запаздывающие разности D et-1,¼, D et-p ).
Выбор осуществляется по минимуму статистики ta=1 для проверки гипотезы о равенстве 1 коэффициента при et-1 в последней модели. При этом дата излома определяется как 1999:02, ta=1= -3.594 (используются 12 запаздывающих разностей), 5% критическое значение равно –4.83, так что UR-гипотеза не отвергается и в этом случае.
Заметим, что распределение ошибок имеет в последней ситуации распределение, отличающееся от нормального (коэффициент эксцесса – “kurtosis” – превышает на 1.626 значение коэффициента эксцесса нормального распределения[4], равного 3). Как следует из работы [Zivot, Andrews (1992)], в таких ситуациях критические уровни уменьшаются, так что если использовать скорректированные на ненормальность критические уровни, то UR-гипотеза не будет отвергнута тем более.
Подведем итоги анализа ряда М1 на интервале 1995:06 по 2000:07, для наглядности поместив результаты применения различных процедур в одну таблицу.
Используемая процедура (критерий) | Исходная (нулевая) гипотеза | |
DS | TS | |
Критерий Дики-Фуллера (расширенный) | Не отвергается | |
Критерий Филлипса-Перрона | Не отвергается | |
Критерий DF-GLS | Не отвергается | |
Критерий KPSS | Отвергается | |
Отношение дисперсий Кохрейна | В пользу DS | |
Критерий Перрона (экзогенный выбор даты излома тренда) | Не отвергается | |
Обобщенный критерий Перрона (эндогенный выбор даты излома тренда) | Не отвергается |
Статистические выводы, полученные при применении всех перечисленных в таблице процедур, согласуются между собой: нулевая DS-гипотеза не отвергается, тогда как нулевая TS-гипотеза отвергается; поведение отношений дисперсий Кохрейна также говорит в пользу DS-гипотезы.
2.2.2. Денежный агрегат M0
Денежный агрегат M0 – Наличные деньги в обращении.
В качестве исходной информации используются данные: денежный агрегат M0, млрд. руб. (с 1998 г. млн. руб.) – месячные данные с 1990:12 по 2000:07; источник – ЦБ РФ.
В отличие от ряда М1, построение единой модели, описывающей поведение ряда M0, затруднительно из-за существенно различного характера поведения этого ряда на периодах до и после 1995 г. По этой причине, а также для возможности сравнения результатов, мы будем проводить эконометрический анализ ряда M0 (а затем и ряда M2) на том же периоде с 1995:06 по 2000:07, на котором исследовался ряд М1.
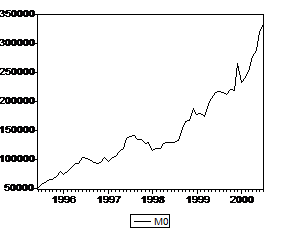
На этом периоде график ряда имеет вид
Напомним график ряда М1:
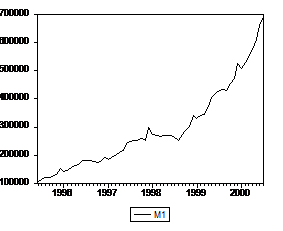
Как видно из сравнения графиков, выраженность возможного излома тренда у ряда М0 не столь велика, как у ряда М1, что может объясняться различием в скорости реструктуризации портфелей населения и предприятий. Посмотрим, как это отразится на статистических выводах при анализе ряда М0.
Как и в случае ряда М1, коррелограмма ряда разностей у ряда М0 имеет значимый пик на лаге 12; для учета автокоррелированности ошибок в оцениваемые уравнения будем включать первоначально 13 запаздывающих разностей.
Оценивание начнем с расширенной модели Дики-Фуллера с включением в правую часть оцениваемой статистической модели константы и тренда:
ADF Test Statistic | 1.368149 | 1% Critical Value* | -4.1584 | |
5% Critical Value | -3.5045 | |||
10% Critical Value | -3.1816 | |||
*MacKinnon critical values for rejection of hypothesis of a unit root. | ||||
Augmented Dickey-Fuller Test Equation | ||||
Dependent Variable: D(Z) | ||||
Method: Least Squares | ||||
Sample(adjusted): 1996:08 2000:07 | ||||
Included observations: 48 after adjusting endpoints | ||||
Variable | Coefficient | Std. Error | t-Statistic | Prob. |
Z(-1) | 0.204696 | 0.149616 | 1.368149 | 0.1808 |
D(Z(-1)) | -0.194405 | 0.228411 | -0.851122 | 0.4010 |
D(Z(-2)) | -0.316411 | 0.228968 | -1.381904 | 0.1766 |
D(Z(-3)) | -0.201863 | 0.216740 | -0.931362 | 0.3586 |
D(Z(-4)) | -0.365408 | 0.205424 | -1.778799 | 0.0848 |
D(Z(-5)) | -0.336200 | 0.174358 | -1.928221 | 0.0627 |
D(Z(-6)) | -0.102447 | 0.181976 | -0.562972 | 0.5774 |
D(Z(-7)) | -0.054527 | 0.214887 | -0.253748 | 0.8013 |
D(Z(-8)) | -0.205422 | 0.221867 | -0.925878 | 0.3614 |
D(Z(-9)) | -0.630249 | 0.212157 | -2.970678 | 0.0056 |
D(Z(-10)) | -0.195244 | 0.234221 | -0.833589 | 0.4107 |
D(Z(-11)) | -0.451913 | 0.232739 | -1.941718 | 0.0610 |
D(Z(-12)) | 0.632189 | 0.249860 | 2.530179 | 0.0165 |
D(Z(-13)) | -0.651846 | 0.266730 | -2.443841 | 0.0202 |
C | -9353.863 | 5632.908 | -1.660575 | 0.1066 |
@TREND(1995:06) | -232.7007 | 423.7413 | -0.549158 | 0.5867 |
R-squared | 0.636001 | Mean dependent var | 4816.396 | |
Adjusted R-squared | 0.465377 | S. D. dependent var | 12589.30 | |
S. E. of regression | 9205.038 | Akaike info criterion | 21.35409 | |
Sum squared resid | 2.71E+09 | Schwarz criterion | 21.97782 | |
Log likelihood | -496.4982 | F-statistic | 3.727491 | |
Durbin-Watson stat | 1.979912 | Prob(F-statistic) | 0.000867 |
Полученное значение t-статистики положительно, так что гипотеза единичного корня не отвергается.
Попробуем повысить мощность критерия Дики-Фуллера путем исключения из правой части оцениваемого уравнения запаздывающих разностей со статистически незначимыми коэффициентами. Результаты последовательного исключения таких разностей приведены в следующей таблице.
Порядок запаздывания исключаемой разности | SC | P-val LM-автокорр. | P-val White | P-val J-B | t-статистика критерия |
– (полная модель с 13 запаздывающими разностями) | 21.978 | 1 – 0.746 2 – 0.781 | 0.249 | 0.227 | 1.368 |
7 | 21.899 | ||||
6 | 21.826 | ||||
10 | 21.761 | ||||
3 | 21.699 | ||||
1 | 21.619 | ||||
8 | 21.557 | ||||
2 | 21.502 | ||||
4 | 21.471 | ||||
5 (выбор и по GS и по SC) | 21.411 | 1 – 0.717 2 – 0.778 | 0.162 | 0.775 | 0.416 |
11 | 21.415 |
Обе процедуры редукции модели – “от общего к частному” и SC – приводят к одной и той же модели, результаты проверки которой приведены в предпоследней строке таблицы.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 |
 Основные порталы (построено редакторами)
Основные порталы (построено редакторами)