

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Определение 1. Законом распределения двумерной случайной величины (X, Y) называют множество возможных пар чисел (xi, yj) и их вероятностей p(xi, yj). Двумерную случайную величину можно трактовать как случайную точку А(Х, Y) на координатной плоскости.
Закон распределения двумерной случайной величины обычно задается в виде таблицы, в строках которой указаны возможные значения xi случайной величины X, а в столбцах — возможные значения yj случайной величины Y, на пересечениях строк и столбцов указаны соответствующие вероятности pij. Пусть случайная величина Х может принимать п значений, а случайная величина Y - т значений. Тогда закон распределения двумерной случайной величины (X, Y) имеет вид

Из этой таблицы можно найти законы распределения каждой из случайных компонент. Например, вероятность того, что случайная величина Х примет значение хk, равна, согласно теореме сложения вероятностей независимых событий,
![]()
Иными словами, для нахождения вероятности Р(хk) нужно просуммировать все т вероятностей по k-му столбцу таблицы (18.21). Аналогично получается вероятность того, что случайная величина Y примет возможное значение уr: Р(уr) получается суммированием всех n вероятностей r-й строки таблицы (18.21) (r = 1, 2, ... ,m). Отсюда следует, что сумма всех вероятностей в законе распределения (18.21) равна единице:

Пример 1. Задано распределение двумерной случайной величины:

Найти распределения Х, Y и Х + Y.
Решение. В нашем случае возможные значения случайной величины X: х1 = 1, х2 = 2, x3 = 3. Тогда, согласно формуле (18.22), имеем P(x1) = 0,1 + 0,2 = 0,3, P(x2) = 0,15 + 0,22 = 0,37, Р(x3) = 0,12 + 0,21 = 0,33. Отсюда получаем закон распределения X:
![]()
Аналогично получаем и для распределения Y: у1 = 1, y2 = 2; P(y1) = 0,1 + 0,15 + 0,12 = 0,37, P(y2) = 0,2 + 0,22 + 0,21 = 0,63;
![]()
Теперь найдем распределение X+Y. Возможные значения этой случайной величины: 2, 3, 4 и 5. Соответствующие вероятности Р(2) = 0,1, Р(3) = 0,15 + 0,2 = 0,35, Р(4) = 0,12 + 0,22 = 0,34, Р(5) = 0,21. Отсюда находим искомое распределение:
![]()
В случае системы двух случайных величин используются кроме математических ожиданий и дисперсий еще и другие числовые характеристики, описывающие их взаимосвязь.
Корреляционный момент
Определение 2. Корреляционным моментом случайных величин Х и Y (или ковариацией) называется математическое ожидание произведений их отклонений:
![]()
Корреляционный момент служит для описания связи между случайными величинами Х и Y. Из свойств математического ожидания легко убедиться в том, что μxy можно записать в следующем виде:
![]()
Для непосредственного вычисления корреляционного момента (ковариации) используется формула (см. распределение (18.21))
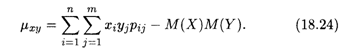
ТЕОРЕМА 3. Корреляционный момент двух независимых случайных величин Х и Y равен нулю.
Если корреляционный момент μxу не равен нулю, то, стало быть, величины Х и Y являются зависимыми.
Коэффициент корреляции
Из определения корреляционного момента следует, что его размерность равна произведению размерностей величин Х и Y; например, если Х и Y измерены в сантиметрах, то μxy имеет размерность см2.
Это обстоятельство затрудняет сравнение корреляционных моментов различных систем случайных величин. Для устранения этого недостатка вводят безразмерную числовую характеристику — коэффициент корреляции, величина которого не зависит от выбора системы измерения случайных величин.
Определение 3. Коэффициентом корреляции случайных величин Х и Y называется отношение их корреляционного момента к произведению средних квадратических отклонений этих величин:
![]()
Из определения и свойств математического ожидания и дисперсии следует важный вывод, что абсолютная величина коэффициента корреляции не превосходит единицы:
![]()
Определение 4. Две случайные величины Х и Y называются коррелированными, если их корреляционный момент (коэффициент корреляции) отличен от нуля; если же их корреляционный момент равен нулю, то Х и Y называются некоррелированными.
Таким образом, две коррелированные случайные величины (т. е. при rxy ≠ 0) являются также и зависимыми. Обратное утверждение неверно, т. е. две зависимые величины могут быть как коррелированными, так и некоррелированными.
Пример 2. Найти корреляционный момент и коэффициент корреляции двух случайных величин Х и Y, распределения которых заданы в предыдущем примере 1.
Решение. Воспользуемся формулами (18.24), (18.26), а также формулой вычисления центрального момента второго порядка (18.19); последовательно вычисляем: М(Х) = 2,03, М(Y) = 1,63, D(X) = 0,629, D(Y) = 0,233,
В данном случае коэффициент корреляции близок к нулю; это означает, что случайные величины Х и Y слабокоррелированы.
Линейная регрессия
Пусть (X, Y) — двумерная случайная величина, где Х и Y — зависимые случайные величины. Оказывается возможным приближенное представление величины Y в виде линейной функции величины X:
![]()
где а и b — параметры, подлежащие определению. Обычно эти величины определяются с помощью метода наименьших квадратов (см. п. 8.5).
Определение 5. Функция (18.27) называется наилучшим приближением в смысле метода наименьших квадратов, если математическое ожидание M[Y — g(Х)]2 принимает наименьшее возможное значение. Функцию g(х) называют среднеквадратической регрессией Y на X.
ТЕОРЕМА 4. Линейная средняя квадратическая регрессия Y на Х имеет вид
![]()
где rxy определяется формулой (18.25), ту = M(Y) и mx = М(Х) — математические ожидания соответственно случайных величин Y и X.
Коэффициент b = rxуσу / σx называют коэффициентом регрессии Y на Х, а прямую
![]()
реализующую линейную зависимость (18.28) случайной величины Y от случайной величины X, называют прямой среднеквадратической регрессии Х на Y. Поскольку зависимость (18.28) является приближенной, то существует погрешность этого приближения, называемая остаточной дисперсией:
![]()
Аналогичную форму записи имеет прямая среднеквадратическая регрессия Х на Y:
![]()
Пример 3. Найти линейную среднюю квадратическую регрессию и остаточную дисперсию случайной величины Y на случайную величину Х по данным примеров 1 и 2.
Решение. Для двумерной случайной величины (X, Y), приведенной в примере 1, все необходимые числовые характеристики указаны в решении примера 2: mx = 2,03, ту = 1,63, rху = -0,023, σx = ![]() = 0,793, σy =
= 0,793, σy = ![]() = 0,483. Из уравнения (18.28) получаем искомое соотношение:
= 0,483. Из уравнения (18.28) получаем искомое соотношение:
![]()
Остаточная дисперсия рассчитывается по формуле (18.29):
![]()
Для оценки среднеквадратичной погрешности линейной регрессии обычно используют величину ε, в нашем случае она составляет
![]()
18.4. Непрерывные случайные величины
Функция распределения и ее свойства
Пусть Х — непрерывная случайная величина (см. определение 3 п. 18.1), значения которой сплошь заполняют интервал (а, b). Теперь уже нельзя составить перечень всех возможных значений X, как это было сделано в случае дискретной случайной величины. Тем не менее существует способ задания любых видов случайных величин. Пусть х — действительное число. Обозначим вероятность события того, что Х примет значение, меньшее x, через F(x).
Определение 1. Функцией распределения случайной величины Х называется функция F(x), определяющая вероятность того, что Х примет значение, меньшее х:
![]()
Геометрический смысл приведенного определения: F(x) — это вероятность того, что случайная величина Х примет значение, изображаемое точкой на числовой оси левее точки х. По виду функции F(x) определяется и вид случайной величины. Уточним понятие непрерывной случайной величины.
Определение 2. Случайная величина называется непрерывной, если ее функция распределения есть непрерывная кусочно-дифференцируемая функция с непрерывной производной.
Таким образом, дискретную случайную величину можно считать кусочно-непрерывной.
Функция распределения обладает рядом фундаментальных свойств, указанных ниже.
Свойство 1. Область значений функции распределения лежит на отрезке [0,1]:
![]()
Свойство 2. Функция распределения является неубывающей, т. е.
![]()
Свойство 3. Если возможные значения случайной величины находятся на интервале (а, b), то F(x) = 0 при х ≤ а и F(x) = 1 при х ≥ b.
Из указанных свойств вытекают важные следствия.
1. Вероятность того, что случайная величина Х принимает значения, заключенные внутри интервала (α, β), равна разности значений функции распределения на концах этого интервала:
![]()
2. Вероятность того, что непрерывная случайная величина Х примет одно определенное значение, равна нулю.
3. Если возможные значения непрерывной случайной величины Х расположены на всей числовой оси, то
![]()
График функции распределения непрерывной случайной величины показан на рис. 18.2.
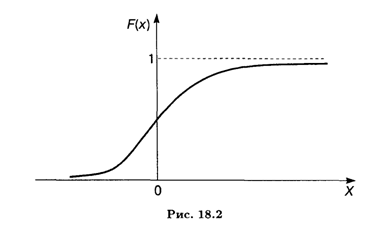
Пример 1. Найти функцию распределения процентного изменения стоимости акций по данным примера 3 п. 18.1 и построить ее график.
Решение. Перепишем таблицу распределения дискретной случайной величины в порядке возрастания ее возможных значений:
![]()
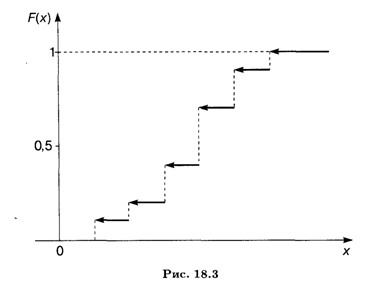
Если х ≤ 5, то F(x) = 0. Если 5 < х ≤ 10, то F(x) = 0,1. На интервале 10 < х ≤ 15 применяем теорему сложения вероятностей, так как события Х < 10 и 10 < Х ≤ 15 несовместны: F(x) = 0,1 + 0,1 = 0,2. Аналогично определяются значения F(x) на других интервалах: при 15 < х ≤ 20 F(x) = 0,4; при 20 < х ≤ 25 F(x) = 0,7; при 25 < х ≤ 30 F(x) = 0,9; при х > 30 имеем достоверное событие (все случаи изменения стоимости акций исчерпаны), т. е. F(x) = 1. Таким образом, искомая функция распределения имеет следующую аналитическую форму записи:
График этой функции распределения показан на рис. 18.3.
Плотность распределения вероятностей и ее свойства
Определение 3. Производная от функции распределения непрерывной случайной величины Х называется плотностью распределения вероятностей X:
![]()
Из этого определения следует, что функция распределения является первообразной для плотности распределения или неопределенным интегралом от нее. Плотность распределения — это "скорость" изменения вероятности Р(Х < х). Из свойства 2 функции распределения следует справедливость следующей фундаментальной теоремы.
ТЕОРЕМА 5. Вероятность того, что непрерывная случайная величина Х примет значение на интервале [α, β), определяется по формуле
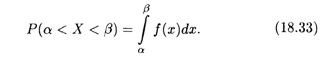
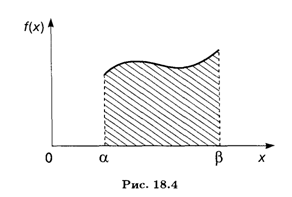
Вспоминая геометрический смысл определенного интеграла (см. п. 7.5), можно сказать, что вероятность того, что непрерывная случайная величина Х примет значение, принадлежащее интервалу (α, β), равна площади криволинейной трапеции, ограниченной сверху кривой плотности распределения f(x), снизу — осью Ох, а с краев — вертикальными прямыми х = α и х = β (рис. 18.4).
Связь между функцией распределения и плотностью распределения вероятностей устанавливается, согласно (18.32), формулой
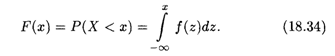
Пример 2. Случайная величина Х задана функцией распределения
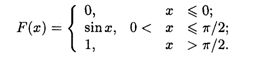
Найти плотность распределения X.
Решение. Функция F(x) является кусочно-дифференцируемой. Согласно формуле (18.32), дифференцируя F(x) по интервалам ее задания, получаем
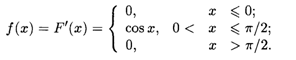
Пример 3. Непрерывная случайная величина Х задана плотностью распределения на всей числовой оси:
![]()
Найти вероятность того, что Х примет значение на интервале (-1, 1).
Решение. Согласно формуле (18.33), искомая вероятность равна
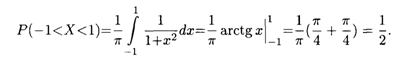
Плотность распределения обладает рядом свойств, основные из них указаны ниже.
Свойство 1. Плотность распределения является неотрицательной функцией:

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 |
