

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
![]()
Это следует из характера функции распределения: она является неубывающей, и, значит, ее производная неотрицательна.
Свойство 2. Несобственный интеграл от плотности распределения в пределах интегрирования по всей числовой оси равен единице:
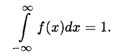
Это равенство означает достоверность события, что случайная величина Х примет значение, принадлежащее интервалу (-![]() ,
,![]() ), т. е. вероятность этого события Р(-
), т. е. вероятность этого события Р(-![]() < Х <
< Х < ![]() ) = 1.
) = 1.
Так, если все возможные значения случайной величины Х лежат внутри интервала (а, b), то

Числовые характеристики непрерывных случайных величин
Определения числовых характеристик дискретных случайных величин распространяются и на непрерывные величины. Разница состоит в том, что вместо сумм в формулах (18.5) и (18.10) берутся их интегральные аналоги.
Определение 4. Математическим ожиданием непрерывной случайной величины X, возможные значения которой находятся на отрезке [а, b], называется определенный интеграл:
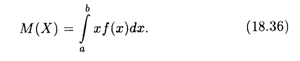
В том случае, когда возможные значения случайной величины Х заполняют всю ось Ох, пределы интегрирования а и b бесконечны: а = -![]() , b =
, b = ![]() . Возможны также случаи, когда один из пределов интегрирования бесконечен (возможные значения Х лежат на полупрямой).
. Возможны также случаи, когда один из пределов интегрирования бесконечен (возможные значения Х лежат на полупрямой).
Определение 5. Дисперсией непрерывной случайной величины Х называется математическое ожидание квадрата ее отклонения:
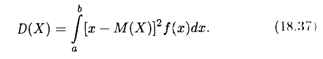
Все сказанное выше о случаях бесконечных пределов интегрирования остается справедливым и для дисперсии.
Среднее квадратичекое отклоенние непрерывной случайной величины определяется, как и прежде, по формуле (18.15):
σ(Х) = 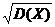 .
.
Для вычисления дисперсии употребляется более удобная формула, которая выводится из (18.37):
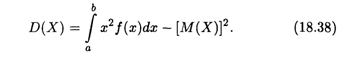
Пример 4. Найти математическое ожидание, дисперсию и среднее квадратическое отклонение случайной величины X, заданной плотностью распределения на отрезке [0, 1]:
![]()
Решение. Согласно формулам (18.36), (18.38) и (18.15) последовательно вычисляем искомые величины:
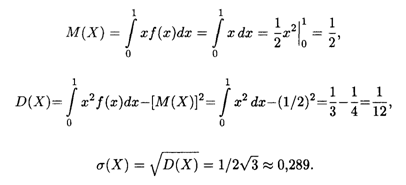
Пример 5. Найти основные числовые характеристики непрерывной случайной величины X, заданной функцией распределения на положительной полуоси Ох:
![]()
Решение. Найдем сначала плотность распределения:
![]()
Затем, как и в предыдущем примере, вычисляем соответствуцющие интегралы; при их вычислении применяем правило интегрирования по частям для определенного интеграла. В итоге получаем искомые величины:
18.5. Основные распределения непрерывных случайных величин
Равномерное распределение
Определение 1. Распределение вероятностей называется равномерным, если на интервале возможных значений случайной величины плотность распределения является постоянной.
Пусть на интервале (a, b) плотность распределения является постоянной величиной: f(x) = С. Определим значение С из условия (18.35):
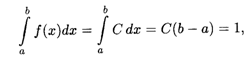
откуда получаем, что f(x) = С = 1/(b - а). Значит, искомая плотность равномерного распределения дается формулой
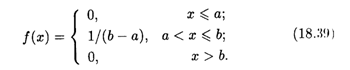
График плотности равномерного распределения указан на рис. 18.5.
Пример 1. Найти среднеквадратическое отклонение случайной величины X, распределенной равномерно на интервале (1, 5).
Решение. Согласно формуле (18.39), плотность распределения указанной случайной величины является ненулевой и равна 0,25 на интервале (1, 5). По формулам (18.36) и (18.38) последовательно вычисляем:

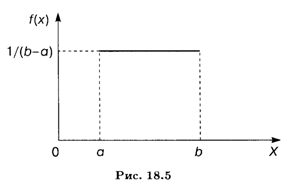
Пример 2. Радиус круга измерен приближенно на интервале (а, b). Полагая, что радиус является случайной величиной X, распределенной равномерно в этом интервале, найти математическое ожидание и дисперсию площади круга.
Решение. Площадь круга также является случайной величиной, вычисляемой по формуле Y = πX2; она имеет то же равномерное распределение, что и случайная величина X. По формулам (18.36) и (18.38) получаем
Нормальное распределение
Определение 2. Общим нормальным распределением вероятностей непрерывной случайной величины Х называется распределение с плотностью
![]()
Нормальное распределение задается двумя параметрами: а и σ. Согласно определениям математического ожидания и дисперсии (формулы (18.36) и (18.38)), после выполнения соответствующих интегрирований можно вывести, что для нормального распределения справедливы формулы
![]()
Определение 3. Нормальное распределение с параметрами а = 0 и σ = 1 называется нормированным; его плотность равна
![]()
Рассмотрим функцию нормального распределения как первообразную плотности распределения вероятностей. Для случая нормированного нормального распределения (18.41) она, согласно формуле (18.34), имеет вид
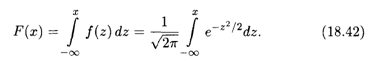
Поскольку функция (18.41) является четной, то неопределенный интеграл от нее является нечетной функцией, и потому вместо функции распределения (18.42) используется функция Лапласа (см. п. 17.5)
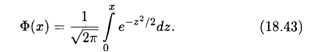
Функции (18.41) и (18.43) табулированы (см. Приложение).
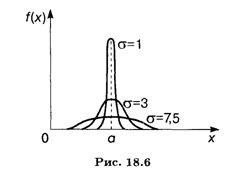
График плотности нормального распределения (18.40) для разных значений а показан на рис. 18.6.
Определение 4. Модой Мо(Х) называется возможное значение случайной величины X, при котором плотность распределения имеет максимум.
Определение 5. Медианой Ме(Х) называется такое возможное значение случайной величины X, что вертикальная прямая х = Me(X) делит пополам площадь, ограниченную кривой плотности распределения.
Нетрудно видеть, что график плотности нормального распределения симметричен относительно прямой х = а, и потому и мода и медиана в данном случае совпадают с математическим ожиданием:
![]()
Пусть случайная величина Х задана плотностью нормального распределения (18.40), тогда вероятность того, что Х примет значение на интервале (α, β), согласно формуле (18.33), равна
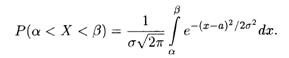
Преобразование этой формулы путем введения новой переменной интегрирования z = (х - а)/σ приводит к удобной вычислительной формуле:
![]()
где Ф — функция Лапласа, определенная по формуле (18.43).
Пример 3. Случайная величина распределена по нормальному закону с математическим ожиданием и средним квадратическим отклонением, соответственно равными 10 и 5. Найти вероятность того, что Х примет значение на интервале (20, 30).
Решение. Воспользуемся формулой (18.44). По условию а = 10, σ = 5, α = 20 и β = 30. Следовательно,
![]()
По табл. 2 Приложения находим соответствующие значения функции Лапласа и окончательно получаем
![]()
Пример 4. Магазин производит продажу мужских костюмов. По данным статистики, распределение по размерам является нормальным с математическим ожиданием и средним квадратическим отклонением, соответственно равными 48 и 2. Определить процент спроса на 50-й размер при условии разброса значений этой величины в интервале (49, 51).
Решение. По условию задачи а = 48, σ = 2, α = 49, β = 51. Используя формулу (18.44), получаем, что вероятность спроса на 50-й размер в заданном интервале равна
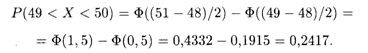
Следовательно, спрос на 50-й размер костюмов составит около 24%, и магазину нужно предусмотреть это в общем объеме закупки.
Асимметрия и эксцесс
В прикладных задачах, например в математической статистике, при теоретическом изучении эмпирических распределений, отличающихся от нормального распределения, возникает необходимость количественных оценок этих различий. Для этой цели введены специальные безразмерные характеристики.
Определение 6. Асимметрией теоретического распределения называется отношение центрального момента третьего порядка к кубу среднего квадратического отклонения:
![]()
Определение 7. Эксцессом теоретического распределения называется величина, определяемая равенством
![]()
где μ4 — центральный момент четвертого порядка.
Для нормального распределения As = Еk = 0. При отклонении от нормального распределения асимметрия положительна, если "длинная" и более пологая часть кривой распределения расположена справа от точки на оси абсцисс, соответствующей моде; если эта часть кривой расположена слева от моды, то асимметрия отрицательна (рис. 18.7, а, б).
Эксцесс характеризует "крутизну" подъема кривой распределения по сравнению с нормальной кривой: если эксцесс положителен, то кривая имеет более высокую и острую вершину; в случае отрицательного эксцесса сравниваемая кривая имеет более низкую и пологую вершину (рис. 18.7, в).
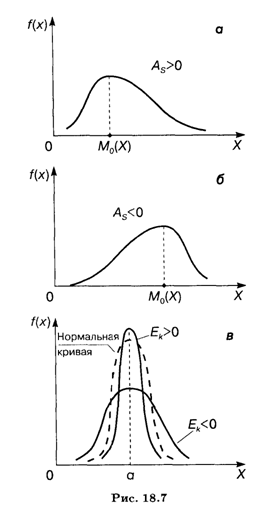
Следует иметь в виду, что при использовании указанных характеристик сравнения опорными являются предположения об одинаковых величинах математического ожидания и дисперсии для нормального и теоретического распределений.
Пример 5. Пусть дискретная случайная величина Х задана законом следующего распределения:
![]()
Найти асимметрию и эксцесс теоретического распределения.
Решение. Найдем сначала математическое ожидание случайной величины:
![]()
Затем вычисляем начальные и центральные моменты 2, 3 и 4-го порядков и среднее квадратическое отклонение (см. формулы (18.27)-(18.31)):
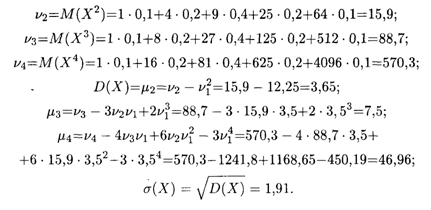
Теперь по формулам (18.45) и (18.46) находим искомые величины:
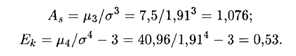
В данном случае "длинная" часть кривой распределения расположена справа от моды, причем сама кривая является несколько более островершинной, чем нормальная кривая с теми же величинами математического ожидания и дисперсии.
18.6. Некоторые элементы математической статистики
Задачи математической статистики
Первой задачей математической статистики является указание методов сбора и группировки статистических сведений, которые получены в результате экспериментов или наблюдений. Вторая задача — это разработка методов анализа статистических данных: оценки неизвестных вероятности события, а также функции и параметров распределения; оценка зависимости случайной величины от других случайных величин; проверка статистических гипотез о виде и величинах параметров неизвестного распределения. Рассмотрим некоторые из этих вопросов.
Выборки
На практике сплошное исследование (каждого объекта из интересующей нас совокупности) проводят крайне редко. К тому же если эта совокупность содержит большое число объектов или исследование объекта требует нарушения его функционального стандарта, то сплошное исследование нереально. В таких случаях из всей совокупности случайно отбирают ограниченное число объектов и подвергают их исследованию.
Введем основные понятия, связанные с выборками. Генеральной совокупностью называется совокупность объектов, из которых производится выборка. Выборочной совокупностью (выборкой) называется совокупность случайно отобранных объектов из генеральной совокупности. Число объектов в совокупности называется ее объемом.
Пример 1. Пусть из 2000 изделий отобрано для обследования 100 изделий. Тогда объем генеральной совокупности N = 2000, а объем выборки п = 100.
Выборку можно осуществлять двумя способами. Если после исследования объект из выборки возвращается в генеральную совокупность, то такая выборка называется повторной; если объект не возвращается в генеральную совокупность, то выборка называется бесповторной.
Выборка называется репрезентативной (представительной), если по ее данным можно достаточно уверенно судить об интересующем признаке генеральной совокупности.
Способы отбора
Различают два способа отбора: без расчленения генеральной совокупности на части и с расчленением. К первому относятся простые случайные отборы (либо повторный, либо бесповторный), когда объекты извлекают по одному из всей генеральной совокупности; такой отбор можно производить с использованием таблицы случайных чисел.
Второй способ отбора включает в себя следующие разновидности, соответствующие способам расчленения генеральной совокупности. Отбор, при котором объекты отбираются из каждой "типической" части генеральной совокупности, называется типическим. Например, отбор деталей из продукции каждого станка, а не из их общего количества является типическим. Если генеральную совокупность делят на число групп, равное объему выборки, с последующим отбором из каждой группы по одному объекту, то такой отбор называется механическим. Серийным называется отбор, при котором объекты отбираются не по одному, а сериями; этот способ используется, когда исследуемый признак имеет незначительные колебания в различных сериях.
На практике часто употребляется комбинирование указанных выше способов отбора. Например, генеральную совокупность разбивают на серии одинакового объема, затем случайным образом отбирают несколько серий и в завершение случайным извлечением отдельных объектов составляют выборку. Конкретная комбинация способов отбора объектов из генеральной совокупности определяется требованием репрезентативности выборки.
Статистическое распределение выборки
Пусть из генеральной совокупности извлечена выборка объема п, в которой значение x1 некоторого исследуемого признака Х наблюдалось п1 раз, значение x2 — п2 раз, ..., значение xk — nk раз. Значения xi называются вариантами, а их последовательность, записанная в возрастающем порядке,— вариационным рядом. Числа ni называются частотами, а их отношения к объему выборки
![]()
— относительными частотами. При этом ![]() ni = п. Модой Мo называется варианта, имеющая наибольшую частоту. Медианой те называется варианта, которая делит вариационный ряд на две части с одинаковым числом вариант в каждой. Если число вариант нечетно, т. е. k = 2l + 1, то me = xl+1; если же число вариант четно (k = 2l), то те = (xl + xl+1)/2. Размахом варьирования называется разность между максимальной и минимальной вариантами или длина интервала, которому принадлежат все варианты выборки:
ni = п. Модой Мo называется варианта, имеющая наибольшую частоту. Медианой те называется варианта, которая делит вариационный ряд на две части с одинаковым числом вариант в каждой. Если число вариант нечетно, т. е. k = 2l + 1, то me = xl+1; если же число вариант четно (k = 2l), то те = (xl + xl+1)/2. Размахом варьирования называется разность между максимальной и минимальной вариантами или длина интервала, которому принадлежат все варианты выборки:
![]()
Перечень вариант и соответствующих им частот называется статистическим распределением выборки. Здесь имеется аналогия с законом распределения случайной величины: в теории вероятностей — это соответствие между возможными значениями случайной величины и их вероятностями, а в математической статистике — это соответствие между наблюдаемыми вариантами и их частотами (относительными частотами). Нетрудно видеть, что сумма относительных частот равна единице: ![]() Wi = 1.
Wi = 1.
Пример 2. Выборка задана в виде распределения частот:
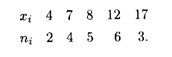
Найти распределение относительных частот и основные характеристики вариационного ряда.
Решение. Найдем объем выборки: п = 2 + 4 + 5 + 6 + 3 = 20. Относительные частоты соответственно равны W1 = 2/20 = 0,1; W2 = 4/20 = 0,2; W3 = 5/20 = 0,25; W4 = 6/20 = 0,3; W5 = 3/20 = 0,15. Контроль: 0,1 + 0,2 + 0,25 + 0,3 + 0,15 = 1. Искомое распределение относительных частот имеет вид
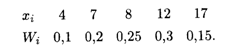
Мода этого вариационного ряда равна 12. Число вариант в данном случае нечетно: k = 2 ∙ 2 + 1, поэтому медиана me = x3 = 8. Размах варьирования, согласно формуле (18.48), R = 17 – 4 = 13.
Эмпирическая функция распределения
Пусть nх — число наблюдений, при которых значение признака Х меньше х. При объеме выборки, равном п, относительная частота события Х < х равна nx/n.
Определение 8. Функция
![]()
определяющая для каждого значения х относительную частоту события Х < х, называется эмпирической функцией распределения, или функцией распределения выборки.
В отличие от эмпирической функции распределения F*(x) выборки функция распределения F(x) генеральной совокупности называется теоретической функцией распределения. Различие между ними состоит в том, что функция F(x) определяет вероятность события Х < х, a F*(x) — относительную частоту этого события. Из теоретических результатов общей теории вероятностей (закон больших чисел) следует, что при больших п вероятность отличия этих функций друг от друга близка к единице:
![]()
Нетрудно видеть, что F*(x) обладает всеми свойствами F(x), что вытекает из ее определения (18.49):
1) значения F*(x) принадлежат отрезку [0, 1];
2) F*(x) является неубывающей функцией;
3) если х1 — наименьшая варианта, то F*(x) = 0 при х ≤ х1; если xk — максимальная варианта, то F*(x) = 1 при x > xk.
Сама же функция F*(x) служит для оценки теоретической функции распределения F(x) генеральной совокупности.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 |
