

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
В п. 1 уже было замечено, что среди р + k + l + т компонент анализируемого многомерного признака (XT,ZT,UT,YT) могут быть как количественные, так и ординальные и номинальные переменные. Упомянутые выше подходы к решению центральной проблемы многомерного статистического анализа формировались именно с учетом природы исследуемых переменных. Соответствующая специализация этих подходов отражена в табл. 4. В ней же даны ссылки на литературные источники, в которых можно найти достаточно полное описание этих подходов.
Таблица 4.
Природа результирующих показателей Y | Природа объясняющих переменных x,z,u | Название обслуживающих разделов многомерного статистического анализа | Литературные источники |
Количественная | Количественная | Регрессионный анализ и системы одновременных уравнений | [1, гл. 15, 17] |
Количественная | Единственная количественная переменная, интерпретируемая как «время» | Анализ временных рядов | [1, гл. 16] |
Количественная | Неколичественная (ординальные или номинальные переменные) | Дисперсионный анализ | [4, гл. 13] |
Количественная | Смешанная (количественные и неколичественные переменные) | Ковариационный анализ, модели типологической регрессии | [4, гл. 13] |
Неколичественная (ординальные переменные) | Неколичественная (ординальные и номинальные переменные) | Анализ ранговых корреляций и таблиц сопряженности | [1.ГП.11] |
Неколичественная (номинальные переменные) | Количественная | Дискриминантами анализ, логит- и пробит-модели, кластер-анализ, таксономия, расщепление смесей распределений | [1, гл. 12-15] |
Смешанная (количественные и неколичественные переменные) | Смешанная (количественные и неколичественные переменные) | Аппарат логических решающих функций, Data Mining | [5] |
Тем не менее, практика статистического анализа и прогнозирования в бизнесе свидетельствует о том, что во всем спектре их математического инструментария бесспорное лидерство (по распространенности и актуальности) принадлежит трем разделам:
регрессионному анализу;
анализу временных рядов;
механизму формирования и статистического анализа экспертных оценок.
Кратко остановимся на каждом из этих разделов.
Регрессионный анализ
Как и прежде, будем описывать функционирование исследуемого реального объекта (фирмы, компании, процесса производства или дистрибуции продукции и т. п.) набором переменных Y,X,Z и U (их содержательный смысл описан в п. 2). Введем ряд определений и понятий, используемых в регрессионном анализе.
Результирующие (зависимые, эндогенные) переменные. Переменная у, характеризующая результат или эффективность функционирования анализируемой системы, называется результирующей (зависимой, эндогенной). Ее значения формируются в процессе и внутри функционирования этой системы под воздействием ряда других переменных и факторов, часть из которых поддается регистрации и, в определенной степени, управлению и планированию (эту часть принято называть объясняющими переменными, см. ниже). В регрессионном анализе результирующая переменная выступает в роли функции, значения которой определяются (правда, с некоторой случайной погрешностью) значениями упомянутых выше объясняющих переменных, выступающих в роли аргументов. Поэтому по природе своей результирующая переменная у всегда сто-хастична (случайна). В общем случае обычно анализируется поведение сразу нескольких (т) результирующих переменных y(1), y(2),…y(m).
Объясняющие (предикторные, экзогенные) переменные X = (x(1),x(2)…x(n))T
Переменные (или признаки), поддающиеся регистрации, описывающие условия функционирования изучаемой реальной экономической системы и в существенной мере определяющие процесс формирования значений результирующих переменных, называются объясняющими. Как правило, часть из них поддается хотя бы частичному регулированию и управлению. Значения ряда объясняющих переменных могут задаваться как бы «извне» анализируемой системы. В этом случае их принято называть экзогенными. В регрессионном анализе они играют роль аргументов той функции, в качестве которой рассматривается анализируемый результирующий показатель у. По своей природе объясняющие переменные могут быть как случайными, так и неслучайными.
Общая схема взаимодействия переменных в регрессионном анализе изображена на рисунке.
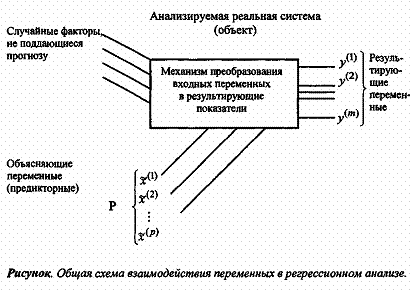


 ,
,

Генезис наблюдений, образующих временной ряд. Речь идет о структуре и классификации основных факторов, под воздействием которых формируются
значения элементов временного ряда. Целесообразно выделить следующие 4 типа таких факторов.
(A) Долговременные, формирующие общую (в длительной перспективе) тенденцию в изменении анализируемого признака *(/) . Обычно эта тенденция описывается с помощью той или иной неслучайной функции /^ (t), как правило, монотонной. Эту функцию называют функцией тренда или просто трендом.
(Б) Сезонные, формирующие периодически повторяющиеся в определенное время года колебания анализируемого признака. Условимся обозначать результат действия сезонных факторов с помощью неслучайной функции <p(t). Поскольку эта функция должна быть периодической (с периодами, кратными сезонам, т. е. кварталам), в ее аналитическом выражении участвуют гармоники (тригонометрические функции), периодичность которых, как правило, обусловлена содержательной сущностью задачи.
(B) Циклические (конъюнктурные), формирующие изменения анализируемого признака, обусловленные действием долговременных циклов экономической, демографической или астрофизической природы (волны Кондратьева, демографические «ямы», циклы солнечной активности и т. п.). Результат действия циклических факторов будем обозначать с помощью неслучайной функции
КО-
(Г) Случайные (нерегулярные), не поддающиеся учету и регистрации. Их воздействие на формирование значений временного ряда как раз и обусловливает стохастическую природу элементов x(t), а следовательно, и необходимость интерпретации x(l)jc(2)f..j;(N) как наблюдений, произведенных над случайными величинами соответственно g(l)^(2),...,g(N). Будем обозначать результат воздействия случайных факторов с помощью случайных величин («остатков», «ошибок») s(t)1. Конечно, вовсе не обязательно, чтобы в процессе формирования значений всякого временного ряда участвовали одновременно факторы всех четырех типов. В одних случаях значения временного ряда могут формироваться под воздействием факторов (А), (Б) и (Г), в других - под воздействием факторов (А), (В) и (Г) и, наконец, - исключительно под воздействием одних только случайных факторов (Г). Однако во всех случаях предполагается непременное участие случайных (эволюционных) факторов (Г). Кроме того, как правило, принимается (в качестве гипотезы) аддитивная структурная схема влияния факторов (А), (Б), (В) и (Г) на формирование значений x(t), которая означает правомерность представления значений членов временного ряда в виде разложения:

Механизмы формирования и статистический анализ экспертных оценок
Обычно выделяются следующие основные типы организации работы группы экспертов ([6]):
• коллегиальный: «метод комиссий» (в виде открытой дискуссии по обсуждаемой проблеме); «метод суда» (в виде противостояния «защиты» и «обвинения» по каждому из вариантов обсуждаемого решения проблемы); «мозговая атака» и т.п.;
• частично коллегиальный: сценарный анализ типа «что — если», метод «Делфи» - многотуровое обсуждение проблемы с тайным голосованием экспертов или заполнением специальных анонимных анкет в конце каждого тура и работой независимой аналитической группы в промежутках между турами и т.п.;
• индивидуально-автономный: каждый из участников экспертной группы формирует и высказывает свое мнение (независимо от позиций других участников) в виде ранжирования обсуждаемых вариантов решения (или объектов), их парных сравнений или отнесения каждого из них к одной из заранее описанных градаций (см. формы представления исходных статистических данных в виде таблиц частот или таблиц сопряженности в п. 1). Иногда эксперты должны оценивать вероятность наступления того или иного события.
При любом из упомянутых выше типов организации работы экспертов приходится проводить статистический анализ экспертных мнений. К основным задачам статистического анализа экспертных оценок относятся:
(i) Исследование структуры совокупности экспертных мнений. Эта задача решается средствами многомерного статистического анализа - методами ранговой корреляции, кластер-анализа, многомерного шкалирования и т.п. (см. [1], гл. 12, 13]). Определив тот или иной способ вычисления «расстояния» между мнениями пары экспертов, мы можем решать затем задачу «кластеризации» экспертов, интерпретируя каждый из найденных таким образом кластер как группу экспертов-единомышленников.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 |
