

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
С появлением алгоритмов БПФ, позволяющих быстро вычислять преобразования Фурье, вычисление свертки через частотную область стало широко использоваться. При значительных размерах сигналов и длины ядра свертки такой подход позволяет в сотни раз сократить время вычисления свертки.
Выполнение произведения спектров может производиться только при одинаковой их длине, и оператор h(n) перед ДПФ необходимо дополнять нулями до размера функции s(k).
Второй фактор, который следует принимать во внимание, это цикличность свертки при ее выполнении в спектральной области, обусловленная периодизацией дискретных функций. Перемножаемые спектры являются спектрами периодических функций, и результат на концевых интервалах может не совпадать с дискретной линейной сверткой, где условия продления интервалов (начальные условия) задаются, а не повторяют главный период.
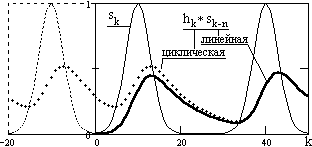
Рис. 19.25. Результаты двух видов свертки.
На рис. 19.25 приведены результаты свертки сигнала sk, заданного на интервале k=(0-50), с функцией hn = a⋅exp(-a⋅n), a = 0.1. Свертка, выполненная через ДПФ, в левой части интервала резко отличается от линейной свертки. Характер искажения становится понятным, если дополнить главный интервал с левой стороны его периодическим продолжением (на рисунке показана часть левого бокового периода, свертка с которым заходит в главный период). Для операторов hn со значениями n, вперед по положению, аналогичные искажения появятся и в правой части главного периода. Для устранения таких искажений сигнальная функция должна продлеваться нулями на размер оператора h(n), что исключит наложение боковых периодов главной трассы функции.
При выполнении свертки через БПФ ощутимое повышение скорости вычислений появляется только при большой длине функций и операторов (например, M>1000, N>100). Следует также обращать внимание на разрядность результатов, т. к. перемножение чисел дает увеличение разрядности в 2 раза. При ограниченной разрядности числового представления с соответствующим округлением это может приводить к погрешностям суммирования.
В системах оперативной обработки данных часто возникает потребность вычислить свертку сигнала, поступающего на вход системы последовательными порциями (например, от датчиков скважинных приборов). В таких случаях применяется секционная свертка. Суть ее состоит в том, что каждая из этих частей сворачивается с ядром отдельно, а полученные части объединяются. Для объединения достаточно размещать их друг за другом с перекрытием в N-1 точку (N – длина ядра свертки), и производить суммирование в местах перекрытия.
20. Случайные процессы и сигналы
20.1. Введение в случайные процессы и сигналы
Наряду с полезными информационными составляющими в реальных сигналах присутствуют помехи и шумы. К помехам обычно относят сигналы от других посторонних источников, "наводки" аппаратуры, влияние дестабилизирующих факторов на основной сигнал и т. п. Физическая природа помех, как правило, не случайна, и после соответствующего изучения может переводиться в разряд детерминированной помехи или исключаться из сигнала. К шумам относят случайные флуктуации сигнала, обусловленные природой его источника или устройств детектирования и формирования сигнала. При неизвестной природе помех они также могут относиться к числу случайных, если имеют случайное вероятностное распределение с нулевым средним значением и дельта-подобную функцию автокорреляции.
Теория вероятностей рассматривает случайные величины и их характеристики в "статике". Задачи описания и изучения случайных сигналов "в динамике", как отображения случайных явлений, развивающихся во времени или по любой другой переменной, решает теория случайных процессов.
В качестве универсальной координаты для распределения случайных величин по независимой переменной будем использовать, как правило, переменную "t" и трактовать ее, чисто для удобства, как временную координату. Распределения случайных величин во времени, а равно и сигналов их отображающих в любой математической форме, обычно называют случайными (или стохастическими) процессами. В технической литературе термины "случайный сигнал" и "случайный процесс" используются как синонимы.
В отличие от детерминированных сигналов значения случайных сигналов в произвольные моменты времени не могут быть вычислены. Они могут быть только предсказаны в определенном диапазоне значений с определенной вероятностью, меньшей единицы. Количественные характеристики случайных сигналов, позволяющие производить их оценку и сравнение, называют статистическими.
В процессе обработки и анализа физико-технических данных обычно приходится иметь дело с тремя типами сигналов, описываемых методами статистики. Во-первых, это информационные сигналы, отображающие физические процессы, вероятностные по своей природе, как, например, акты регистрации частиц ионизирующих излучения при распаде радионуклидов. Во-вторых, информационные сигналы, зависимые от определенных параметров физических процессов или объектов, значения которых заранее неизвестны, и которые обычно подлежать определению по данным информационным сигналам. И, в-третьих, это шумы и помехи, хаотически изменяющиеся во времени, которые сопутствуют информационным сигналам, но, как правило, статистически независимы от них как по своим значениям, так и по изменениям во времени. При обработке таких сигналов обычно ставятся задачи:
- обнаружение полезного сигнала, оценка параметров сигнала, выделение информационной части сигнала (очистка сигнала от шумов и помех), предсказание поведения сигнала на некотором последующем интервале (экстраполяция).
20.2. Случайные процессы и функции
Случайный процесс описывается статистическими характеристиками, называемыми моментами. Важнейшими характеристиками случайного процесса являются его стационарность, эргодичность и спектр мощности.
Случайный процесс в его математическом описании Х(t) представляет собой функцию, которая отличается тем, что ее значения (действительные или комплексные) в произвольные моменты времени по координате t являются случайными. Строго с теоретических позиций, случайный процесс X(t) следует рассматривать как совокупность временных функций xk(t), имеющих определенную общую статистическую закономерность. При регистрации случайного процесса на определенном временном интервале осуществляется фиксирование единичной реализации xk(t) из бесчисленного числа возможных реализаций процесса X(t). Эта единичная реализация называется выборочной функцией случайного процесса X(t). Отдельная выборочная функция не характеризует процесс в целом, но при определенных условиях по ней могут быть выполнены оценки статистических характеристик процесса. Примеры выборочных функций модельного случайного процесса X(t) приведены на рис. 20.1. В дальнейшем при рассмотрении различных параметров и характеристик случайных процессов для сопровождающих примеров будем использовать данную модель процесса.

Рис. 20.1. Выборочные функции случайного процесса
Функциональные характеристики случайного процесса.
С практической точки зрения выборочная функция является результатом отдельного эксперимента, после которого данную реализацию xk(t) можно считать детерминированной функцией. Сам случайный процесс в целом должен анализироваться с позиции бесконечной совокупности таких реализаций, образующих статистический ансамбль. Полной статистической характеристикой процесса является N-мерная плотность вероятностей р(xn; tn). Однако, как экспериментальное определение N-мерных плотностей вероятностей процессов, так и их использование в математическом анализе представляет значительные математические трудности. Поэтому на практике обычно ограничиваются одно - и двумерной плотностью вероятностей процессов.
Допустим, что случайный процесс X(t) задан ансамблем реализаций {x1(t), x2(t),… xk(t),…}. В произвольный момент времени t1 зафиксируем значения всех реализаций {x1(t1), x2(t1),… xk(t1),…}. Совокупность этих значений представляет собой случайную величину X(t1) и является одномерным сечением случайного процесса X(t). Примеры сечений случайного процесса X(t) по 100 выборкам xk(t) (рис. 9.1.1) в точках t1 и t2 приведены на рис. 20.2.
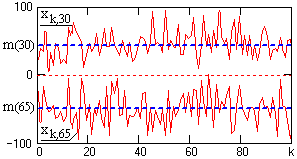
Рис. 20.2. Сечения случайного процесса X(t).
Одномерная функция распределения вероятностей F(x, ti) определяет вероятность того, что в момент времени ti значение случайной величины X(ti) не превысит значения x:
F(x, ti) = P{X(ti)≤x}.
Очевидно, что в диапазоне значений вероятностей от 0 до 1 функция F(x, t) является неубывающей с предельными значениями F(-∞, t)=0 и F(∞, t)=1. При известной функции F(x, t) вероятность того, что значение X(ti) в выборках будет попадать в определенный интервал значений [a, b] определяется выражением:
P{a<X(ti)≤b} = F(b, ti) – F(a, ti).
Одномерная плотность распределения вероятностей p(x, t) случайного процесса Х(t) определяет вероятность того, что случайная величина x(t) лежит в интервале {x ≤ x(t) ≤ x+dx}. Она характеризует распределение вероятностей реализации случайной величины Х(ti) в произвольный момент времени ti и представляет собой производную от функции распределения вероятностей:
p(x, ti) = dF(x, ti)/dx. (20.1)
Моменты времени ti являются сечениями случайного процесса X(t) по пространству возможных состояний и плотность вероятностей p(x, ti) представляет собой плотность вероятностей случайных величин X(ti) данных сечений. Произведение p(x, ti)dx равно вероятности реализации случайной величины X(ti) в бесконечно малом интервале dx в окрестности значения x, откуда следует, что плотность вероятностей также является неотрицательной величиной.
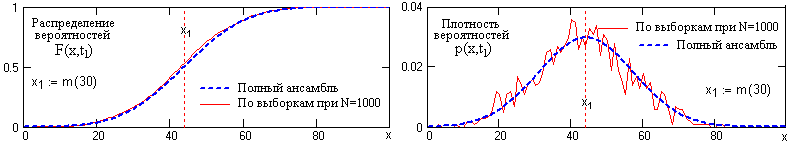
Рис. 20.3. Распределение вероятностей и плотность вероятностей сечения случайного процесса
На рис. 20.3 приведены примеры распределения вероятностей и плотности вероятностей сечения случайного процесса X(t) в точке t1 (рис. 20.1). Функции вероятностей определены по N=1000 выборок дискретной модели случайного процесса и сопоставлены с теоретическими распределениями при N → ∞.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 |
