
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Основные типы языковых процессоров — трансляторы и интерпретаторы.
Транслятор преобразует описания с одного языка на другой за один или несколько проходов в зависимости от класса и структуры входного языка и генерирует так называемый объектный модуль представления входного описания на выходном языке. Этот модуль при необходимости можно многократно выполнять или использовать без повторной обработки на языковом процессоре.
Интерпретатор анализирует представление каждого предложения на исходном языке и сразу осуществляет действия, предписанные этим предложением. Это приводит к необходимости выполнять преобразования с помощью языкового процессора при каждом повторном использовании описания. В большинстве случаев применение трансляторов приводит к меньшим затратам времени и большим затратам оперативной памяти ЭВМ по сравнению с затратами при интерпретации.
В общем случае языковый процессор состоит из следующих функциональных блоков: блока ввода исходного описания, лексического анализатора, синтаксического анализатора, блока управления и семантической интерпретации, блока выдачи диагностических сообщений.
Блок ввода исходного описания предназначен для ввода и преобразования информации с алфавитно-цифровой или графической формы во внутримашинную двоичную. Для алфавитно-цифрового описания блок ввода обычно представлен простой подпрограммой, которая вызывается лексическим анализатором. Для графических языков блок ввода выполняется в виде программного процессора, который осуществляет преобразование данных от разнотипных графических устройств в единую промежуточную форму на основе унификации виртуальных устройств ввода.
Лексический анализатор распознает введенные терминальные символы исходного языка, заменяет цепочку терминальных символов некоторым внутренним представлением, которое более эффективно для обработки синтаксическим анализатором.
Синтаксический анализатор проверяет правильность синтаксиса введенной цепочки (предложения). Все синтаксически правильные цепочки передаются для исполнения в блок семантической интерпретации, который может выполнять требуемые подстановки для порождения цепочек выходного языка или осуществлять вызов программ, необходимых для выполнения действий, предписанных входной цепочкой.
Блок выдачи диагностических сообщений обычно выполняется в виде специализированной программы, которая по входному коду считывает текст сообщения из соответствующего файла и выводит его на экран дисплея и (или) в файл протокола работы и на устройство печати.
Средства поддержки лингвистического обеспечения. В зависимости от типа исходных языков и методов их обработки различают следующие три основные группы средств поддержки лингвистического обеспечения: проблемно-ориентированные системы или генераторы пакетов прикладных программ; макрогенераторы и другие расширяющие системы программирования, построенные по схеме предтрансляторов; метасистемы или системы построения трансляторов по схеме параметрических систем программирования.
Проблемно-ориентированные системы предназначены для построения на их основе специализированных программ. В качестве параметров настройки в системе этого класса может использоваться описание модели исследуемой проблемы (объекта) или предметной области. Система обеспечивает автоматизированный подбор программных модулей и конструирует на их основе программы для исследования научных проблем (объектов) заданного класса. Она может обеспечить также автоматический обмен данными между внутренней и внешней памятями ЭВМ или совмещение модулей, написанных на различных языках программирования.
Системы этого класса ориентированы на создание определенного сервиса для разработки программного обеспечения, и задачи автоматизации разработки и поддержки различных языков АСНИ при этом практически не решаются.
Макрогенераторы и предтрансляторы представляют средства для расширения языков программирования и занимают промежуточное положение между пакетами прикладных программ и специализированными языками исследования. С помощью набора макроопределений создается надстройка над базовым языком, которая отражает специфику предметной области применения. Общая схема использования метода предтрансляции показана на рис. 21.9.
Развитие возможностей этого метода основано на использовании синтаксических макропроцессоров, в которых выполнению макроподстановок предшествует синтаксический анализ программ на исходном языке. Ряд синтаксических макропроцессоров допускают возможность использования различных пар входных и выходных языков, что приближает их к системам построения трансляторов или метасистемам.
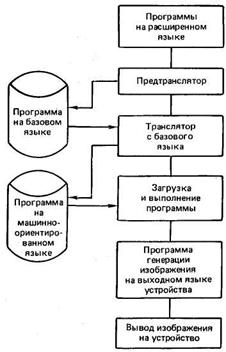
Рис. 21.9. Схема обработки входных языков методом предтрансляции
Метасистемы можно разделить на многоязыковые системы программирования и метатрансляторы. Многоязыковые системы программирования создаются на основе выделения общей части трансляторов с нескольких конкретных языков — ядра системы, которое реализует алгоритмы синтаксического контроля и анализа для определенного класса языков.
Если грамматика проектируемого языка Lk относится к классу языков, распознаваемых ядром системы, то создание языкового процессора Jk сводится к описанию грамматики языка Lk на специальном метаязыке системы и генерации таблиц описания грамматики Gk, которые обеспечивают настройку синтаксического анализатора на язык Lk.
Метатрансляторы типа МТ-системы позволяют создавать языковые процессоры для входных языков с различными грамматиками. В качестве параметров в таких системах задается информация о синтаксической структуре языка и его семантике. Для описания синтаксиса часто используется нормальная форма Бэкуса — Наура, а семантика задается на специальном метасемантическом языке. Структура метатрансляторов типа МТ-систем приведена на рис. 21.10.
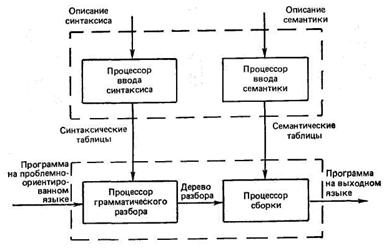
Рис. 21.10. Структура системы метатранслятора
В результате работы системы программа на входном языке преобразуется в выходной, которым в МТ-системе может быть любой язык программирования. Таким образом, метатрансляторы типа
МТ-системы позволяют автоматизировать создание языковых процессоров для различных входных языков, обеспечивая его перевод на любой выбранный язык программирования.
Для построения лексических и синтаксических анализаторов входных языков в составе операционных систем имеются соответствующие генераторы.
Автоматизация разработки диалоговых графических языков в системах автоматизированного исследования достигается за счет применения унифицирешенного интерпретатора с класса диалоговых языков и двуязыковой концепции проектирования диалоговых программ. Основу двуязыковой концепции составляет использование простого специализированного языка для описания диаграмм состояний параллельно с применением традиционных языков программирования.
Диалоговая программа состоит из описания диаграмм состояний на специализированном языке и семантического описания реакции системы на языке программирования. Тексты этих частей могут быть совмещены, если, например, включить строки описания диаграмм в программу семантического описания в качестве отмеченных комментариев используемого языка программирования. На рис. 21.11 приведен пример такой программы для диаграммы на рис. 21.8. Текст диалоговой программы подвергается трансляции двумя трансляторами: с языка описания диаграмм состояний и с языка программирования. В результате первой трансляции создается файл описания алфавита и синтаксиса ДГ-языка.
С Пример описания ДГ-языка и ДГ-программы для построения изо-
С бражения, состоящего из ломаных линий.
С Операторы с коментарием CD-операторы диалогового языка,
С включенные в текст исполняющей программы.
С
SUBROUTINE PLINE
NAME = Ø !Имя сегмента
С Определение диалогового языка
CD SUBLANG = „DRPLIN", STATE = 3, DIAGN = Ø;
С
!Ø Ø CALL INTERP
CALL INTPAR (IRET, NPR)
С Если IRET = Ø, то выходим из языка
IF(IRET. EQ. l) GOTO 999
С NPR — номер прикладной программы, подлежащей выполнению
GOTO (1 Ø, 2 Ø, 3 Ø, 4Ø) NPR
С
С____________________ Описание состояния N 1_________________
CD S1: MS =«3адайте первую точку ломаной линии»;
CD MS = «Точка задается локатором координат»;
CD MS = «Локатор координат — следящее перекрестье»;
С
CD LOC Р = 1 Ø, S = 2;
1Ø NAME = NAME+ 1
CALL GCTLC (NPT, X,Y) !Получить координаты точки
CALL GCRSG (NAME) !Открыть сегмент
CALL MOVA2 (X, Y) !Перейти в начало ломаной
GOTO 1 Ø Ø
С
С__________________ Описание состояния N 2 __________________
CD S2: MS = «Задайте очередную точку ломаной линии»;
CD MS = «Точка задается локатором координат»;
С
CD LOC, Р = Ø; S = 2;
CALL GGTLC (NRT. X.Y) !Получить координаты точки
CALL LINA2 (X, Y) !Вычертить отрезок ломаной
GOTO 1ØØ
С
CD, CHC = "НОВ—ЛОМ", Р = 3Ø, S = 1;
CALL GCLSG!3акрыть сегмент
GOTO 1ØØ
С
CD CHC, = "УДАЛ — ЛОМ" S = 3;
CD CHG = "КОН — РАБ", Р = 5Ø, S = R;
5Ø CALL GCLSG! Закрыть сегмент
GOTO 1ØØ
С
С_________________ Описание состояния N 3_________________ CD S3: MS = "Укажите удаляемую линию";
С
С PIC, Р = 4Ø, S = 3;
CALL GGTPC (NAMSEG, IPIC) !Получить имя сегмента
CALL GDSG (NAMSEG) !Удалить сегмент
GOTO 1ØØ
CD CHC = «НОВ — ЛОМ», S = 1;
CD END;
С
999 RETURN
END
Рис. 21.11. Текст диалоговой программы для диаграмм состояний рис. 21.7.
Применение двуязыковой концепции дает возможность использовать единственный язык для описания диаграмм состояний вместе с различными языками программирования высокого уровня. Это исключает необходимость расширять каждый язык программирования диалоговыми компонентами, улучшает технологию построения и отладку диалоговых программ. В зависимости от стадии исследования и уровня подготовки специалистов в области программирования на практике используются диаграммы состояний и несколько уровней спецификации семантического описания.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 |
