
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
1. Доступ с помощью ключа, эквивалентного адресу;
2. Хэширование (метод произвольного доступа или рассеянной
памяти).
Использование первой группы методов доступа возможно в тех случаях, когда в качестве атрибута в запись включается адрес памяти, в котором будет размещена запись. При работе с БД этот атрибут будет использоваться в качестве ключа.
Методы второй группы широко используются для обеспечения быстрой выборки и обновления записей по заданному значению первичного ключа.
Основная идея хэширования заключается в том, что каждый экземпляр записи размещается в памяти по адресу, вычисляемому с помощью специальной хэш-функции. В этом случае экземпляры записей хранятся не в последовательных ячейках, выделенного блока памяти, а случайным образом рассеиваются по всему блоку. Причем каждая новая запись помещается в блок памяти таким образом, что ее присутствие или отсутствие может быть установлено без поиска по всему блоку.
Другими словами, в методе хэширования строится отображение множества ключевых значений экземпляров записей во множество физических адресов.
В качестве хэш-функций обычно выбирается некоторое правило, преобразующее значение типа записи в адрес.
Рассмотрим на примере алгоритм построения хэш-функции.
Пусть в памяти машины для хранения экземпляров записей выделен блок В из 1024 слов. Экземплярами записей zi, которые необходимо хранить в В, являются наборы символов длиной в два слова. Таким образом, в блоке В можно разместить 512 отличающихся записей zi.
Предположим, что начальный адрес блока в памяти α. Хэш-адресом для данного случая может быть цепочка Iz из девяти битов, поскольку формула α+2Iz будет давать адрес, попадающий внутрь блока. Цепочка Iz может быть вычислена для каждой записи длиной в два слова по следующему алгоритму. Пусть zi хранится в словах а и b. Тогда:
1. Умножим а на b и получим в результате с (произведение занимает два слова).
2. Сложим два слова, составляющие с, получим в результате d.
3. Возводим d в квадрат, получим в результате е.
4. Извлечем девять центральных битов из е и примем, что это и есть искомое значение Iz.
В зависимости от свойств битовых цепочек, представляющих экземпляры записей или их ключей, могут использоваться различные хэш-функции. При их подборе важно, чтобы хэш-функция равномерно распределяла все множество zi по выделенному блоку памяти.
Обычно выбранная хэш-функция не может быть полной гарантией того, что различные экземпляры записей получат различные хэш-адреса. Всегда в процессе хэширования возникает ситуация, когда два (или более) экземпляра записей получают один и тот же адрес, что приводит к коллизии. Коллизия возникает, когда при добавлении новой записи в блоке памяти выясняется, что позиция записи, задаваемая хэш-адресом, уже занята записью, отличной от той, которую собираются туда поместить.
Для разрешения коллизий имеется много методов. К ним относятся методы последовательного сканирования и цепочки.
Метод последовательного сканирования. Он состоит в том, что при возникновении коллизии просматриваются последовательно (сканируются) участки памяти, отведенные для хранения записей, до тех пор, пока не будет найдена свободная позиция, куда и помещается запись.
Метод цепочки. Вместо хранения самих элементов блока можно хранить в нем указатели на связанные списки экземпляров, записей, имеющих одинаковый хэш-адрес.
После хэширования экземпляра записи (ее ключа), если участок памяти по вычисленному адресу свободен, запись размещается по этому адресу. Если же участок памяти по вычисленному адресу занят, то происходит обращение по указанию к следующему участку памяти (элементу списка), на который и помещается запись.
При поиске записей действия выполняются в той же последовательности. Вначале проверяется участок памяти по вычисленному адресу. Если там находится запись с другим значением ключа, то по указателю обращаются к следующей записи, и так до тех пор, пока не будет найдена необходимая запись.
Память, выделяемую для организации списков, называют областью переполнения.
Индексно-последовательный метод доступа. Он строится на основе упорядоченного физически последовательного файла и иерархической структуры индексов блоков, каждый из которых упорядочен по значениям первичных ключей подобно записям в файле данных. Данный метод позволяет обеспечивать как последовательный, так и произвольный доступ к данным. С этой целью в рассмотрение вводится новый параметр — индекс блока. Индекс блока —представляет собой упорядоченную таблицу значений первичных ключей, в которой каждый элемент блока содержит наибольшее значение ключа среди всех записей в указанном блоке. С каждым значением ключа в индексе связан указатель соответствующего блока (рис. 22.35).
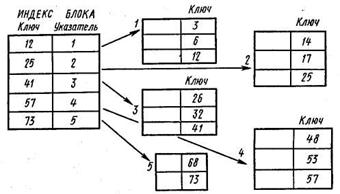
Рис. 22.35. Организация индекса блока
Использование упорядоченного индекса блока требует таких же записей данных в файле. Благодаря этой упорядоченности можно в каждом элементе индекса указать границы соответствующего блока: значение ключа представляет верхнюю границу, а указатель задает нижнюю границу, так как указывает адрес блока, точнее, адрес первой записи в блоке, содержащей наименьшее значение ключа.
В этом случае поиск экземпляра записи осуществляется посредством первоначального установления номера блока, в котором может находиться запись, а затем последовательного поиска в этом блоке, пока не будет установлено местонахождение искомой записи или ее отсутствие.
Данный метод позволяет обеспечивать быстрый доступ к записям баз данных и файлов большой размерности, в которых поиск по одному только индексу приводит к значительным затратам времени.
Индексно-произвольный метод доступа. Данный метод обеспечивает доступ к экземплярам записей на основе использования индекса. Поэтому метод называют также «метод доступа с полным индексом».
Полный индекс представляет собой такую организацию файла, при которой для каждого конкретного экземпляра записи предусмотрен соответствующий индекс. Этот индекс составляется из значения первичного ключа и указателя экземпляра записи, содержащий это значение (рис. 22.36).
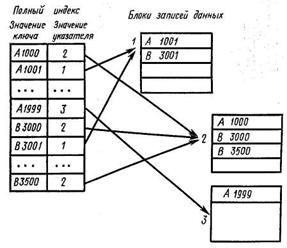
Рис. 22.36. Схема доступа с полным индексом
Обычно для ускорения поиска индексы упорядочиваются. При этом упорядочивание или физически близкое размещение хранимых записей не требуется.
После того как в индексе обнаружено искомое значение ключа, доступ к записи можно осуществить с помощью указателя, который хранится в индексе рядом со значением ключа. В этом случае, если искомое значение ключа в индексе не найдено, поиск завершается на уровне индекса. Допускается произвольный доступ к индексу посредством хэширования.
Метод доступа с полным индексом обеспечивает эффективную выборку одиночных записей, а также простоту операций обновления.
Методы доступа, основанные на использовании древовидных структур. Получили широкое распространение методы представления в памяти ЭВМ данных в виде древовидных сетевых структур и соответствующие методы доступа к ним. Эти методы стали конкурентами классических, таких, как индексно-последовательный метод или хэширование. К основным древовидным структурам обычно относят: бинарное дерево и В-дерево.
Бинарным (двоичным) деревом называется древовидный граф с двоичным ветвлением, т. е. с таким ветвлением, когда из каждой вершины (кроме концевых) выходят две дуги.
Бинарные деревья представляют собой широко используемый вид структур баз данных, обеспечивающий как произвольную, так и последовательный выбор данных.
Важную роль проектирования древовидных структур данных играет понятие сбалансированного дерева. Прежде чем его рассмотреть, введем некоторые дополнительные понятия. Уровень вершины i определяется длиной пути от корневой вершины Т до вершины i. Корневая вершина Т имеет нулевой уровень. Ветвь дерева определяется его максимальным уровнем.
Дерево называется сбалансированным, если разница уровней любых двух конечных вершин не превышает единицы.
Построение сбалансированного дерева делает равновероятным обращение к любой из его вершин, что позволяет минимизировать среднюю длину доступа. Механизм поиска по бинарному дереву основан на том, что каждая вершина дерева помечена отдельным ключом. Ключи упорядочены следующим образом: 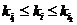 , где ki — ключ i-й вершины;
, где ki — ключ i-й вершины; ![]() —ключ i1 - вершины, соответствующей левой дуге i-й вершины (—);
—ключ i1 - вершины, соответствующей левой дуге i-й вершины (—); ![]() — ключ вершины, лежащей на
— ключ вершины, лежащей на
правой дуге. При поиске некоторого ключа k вначале просматривается корневая вершина дерева Т и сравнивается ключ k с ключом kТ корневой вершины. В случае k=kТ поиск завершен успешно. В том случае, когда k<kТ, поиск продолжается в левом поддереве, а при k>kT поиск продолжается в правом поддереве (рис. 22.37).
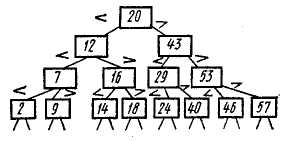
Рис. 22.37. Бинарное дерево поиска
Кроме бинарных деревьев в БД часто используются так называемые В-деревья. В-дерево представляет собой обобщение понятия бинарного дерева. В нем из каждой вершины могут выходить более двух ветвей. Обычно В-деревья используются только для организации индекса. Записи данных располагаются в отдельной области, для которой возможен произвольный доступ. Каждая вершина В-дерева состоит из совокупности значений первичного ключа, указателей индексов и ассоциированных данных. Указатели индекса используются для перехода на следующий, более низкий уровень вершины в В-дереве.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 |
