
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Выражения реляционного исчисления
{r|ψ(r)} или {х2, x2, ..., xn|ψ(x1, x2, ..., хп)}
служат основой реальных языков манипулирования данными.
В реляционном исчислении доказано, что для любого простого выражения исчисления существует эквивалентное ему выражение реляционной алгебры. Поэтому может быть построена универсальная процедура для перевода выражений реляционного исчисления в эквивалентное по смыслу алгебраическое выражение.
22. 5. Сетевая модель данных
В основе разработки сетевых моделей данных лежит возможность представления связей между данными в графической форме.
Наиболее развитой сетевой моделью является модель, предложенная Рабочей группой по базам данных (РГБД) Ассоциации по языкам обработки данных (КОДАСИЛ). Нужно отметить, что в основе модели КОДАСИЛ лежат понятия «сущность» и «связь», а к основным типам структур модели относят: элемент данных, агрегат, запись, набор.
Сущность — это собирательное понятие, некоторая абстракция реально существующего объекта предметной области, процесса или явления. Набор однородных объектов или явлений определяет тип сущности, а каждый конкретный объект в наборе представляет экземпляр сущности. Связи между сущностями фиксируются заданием множества отношений. При анализе связей между сущностями наиболее часто используются бинарные связи, т. е. связи между двумя сущностями. По характеру бинарные связи между типами сущностей различают:
- один к одному (1:1);
- один ко многим (1:М);
- многие к одному (М : 1);
- многие ко многим (М:М).
Элемент данных — это наименьшая единица данных, которой можно оперировать в БД и выполнять построение всех остальных структур. Можно отметить, что элемент данных представляет собой аналог поля в файловых системах. Элемент данных имеет имя, которое хранится в БД как часть описания базы. Именами элементов данных могут быть, например, ИНДЕКС ИЗДЕЛИЯ, ДАТА ВЫПУСКА, СТОИМОСТЬ и т. д. В сетевых моделях элементы данных используются для представления атрибутов сущности.
Агрегат данных — совокупность элементов данных, имеющих общее имя, которую можно рассматривать как единое целое. Например, агрегат данных ДАТА состоит из элементов данных: ЧИСЛО, МЕСЯЦ, ГОД.
Запись — совокупность элементов данных, которые описывают конкретный экземпляр объекта (сущности). Предположим, что сущность ТЕЛЕВИЗОР описывается элементами данных: МАРКА; ИНДЕКС, ЦЕНА. Тогда запись в этом объекте для конкретного изделия может быть: РЕКОРД, ВЦ-311, 640. Можно отметить, что запись эквивалентна кортежу в реляционных моделях данных.
Сетевая модель РГБД КОДАСИЛ в качестве базовых использует понятия «экземпляр» и «набор».
Тип — это общее понятие, представляющее собой собрание экземпляров записи. Каждый тип записи состоит из некоторого числа элементов данных, значения которых размещаются в экземплярах записи данного типа. В качестве связей между типами записей используются наборы. Каждый набор представляет собой отношение (связь) между двумя или несколькими типами записей. Он отображает множество связей между экземплярами записей типа «владелец» и «член». Для каждого типа набора один тип записи может быть объявлен «владельцем», а остальные — его «члены». При этом любой экземпляр записи типа «член» может быть связан не более чем с одним экземпляром типа «владелец».
Графическая интерпретация сетевой модели данных представляет собой ориентированный граф без петель. Причем, вершинам графа соответствуют типы записей, а дугам — наборы, отражающие связи между соответствующими типами записей. Направленные стрелки на дуге ориентированы от записи типа «владелец» к записи типа «член».
Подмножество дуг, соединяющих одну запись — владельца с несколькими записями— членами, называется экземпляром набора.
Рассмотрим, например, граф, отражающий упрощенную БД
комплектующих деталей телевизора (рис. 22.19).
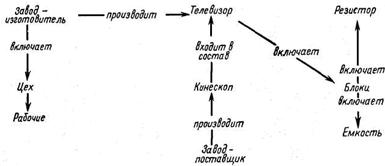
Рис. 22.19. Пример построения базы данных комплектующих телевизора
Стрелки между вершинами соответствуют наборам данных, отражающих связи между записями, а надписи над стрелками — именам наборов.
Как тип записи, так и набор данных в общем случае могут быть представлены таблицами. Но в отличие от таблиц реляционных моделей, в сетевых моделях данных они могут допускать дубликаты строк или записей.
В модели КОДАСИЛ вводится особый тип набора данных, называемый сингулярным и имеющий только один экземпляр набора этого типа. В нем запись «владелец» отсутствует (владельцем является система управления базой данных). Этот тип набора обычно используется для создания традиционного файла, состоящего из однотипных записей.
В сетевой модели данных КОДАСИЛ имеются несколько ограничений, которые надо учитывать при построении модели. Основным внутренним ограничением являются функциональность связей, так как нельзя реализовать связи типа М:М. В модели это ограничение соответствует положению: в конкретном экземпляре набора экземпляр записи числа может иметь не более одного экземпляра записи владельца.
Для того чтобы отобразить принятую схему данных в памяти ЭВМ, требуется описать все таблицы, соответствующие записям и наборам. Для этого группой КОДАСИЛ был предложен язык описания данных, позволяющий задать схему данных с помощью четырех типов статей.
Статья схемы задает имя схемы БД. Статья запишется как:
SCHEMA NAME IS имя схемы.
Статья области характеризует область памяти, в которой размещаются экземпляры записей БД. С помощью этой статьи можно в случае необходимости распределять БД по различным ЗУ. Поскольку в общем случае можно выделить под БД несколько различных областей, каждая из них должна иметь собственное уникальное имя и описываться следующим образом:
AREA NAME IS имя области;
Статья записи содержит описание типа записи, включающее имя записи и характеризующее все элементы данных, входящие в ее состав. Каждому типу записи соответствует своя статья. Статья записи начинается предложением:
RECORD NAME IS имя записи;
Следующий за этим предложением текст зависит от варианта реализованного языка КОДАСИЛ. Наиболее распространенными являются варианты ЯОД КОДАСИЛ. Поскольку ряд действующих СУБД реализуют вариант ЯОД-73, далее будем рассматривать случай, когда статья записи формируется на его основе. Тогда вторым предложением в схеме записи будет идти предложение:

где в фигурных скобках указано одно из возможных описаний.
DIRECT используется в том случае, когда предполагается, что номер страницы области для размещения записи будет определяться программой, выполняющей включение записи в БД.
CALC применяется, когда предполагается, что специальная программа будет использовать значение ключа БД.
Ключ базы данных — это идентификатор, уникально определяющий запись, помещенную в БД.
Для того, чтобы можно было различать отдельные экземпляры записей, хранящихся в БД, каждому экземпляру записи присваивается
значение ключа, который играет роль внутрисистемного инде-тификатора.
Зная значение ключа, можно быстро отыскать соответствующую запись. В формате CALC USING имя calc-элемента, в качестве имен сalc-элемента используются имена элементов данных записи.
В том случае если ключи не имеют дубликатов значений, то в варианте CALC следует указать DUPLICATES ARE NOT ALLOWED. Если ключ имеет дубликаты значений, например в качестве ключа задан элемент данных ФАМИЛИЯ в записи типа СТУДЕНТ, то следует указать DUPLICATES ARE ALLOWED.
VIA SET используется в том случае, когда требуется запись разместить физически как можно ближе к соответствующему экземпляру набора, в который она будет включена.
SYSTEM применяется в случае, если размещение записей возлагается на саму СУБД (в соответствии с заложенными в нее алгоритмами).
Для того чтобы приписать рассматриваемый тип записи к некоторой области, используется предложение
WITHIN имя области AREA
Для описания внутренней структуры записи в статью записи включается подсистема данных, имеющая вид
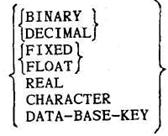
С помощью этой подсистемы каждому элементу данных приписывается тип значений данных: двоичное, десятичное, фиксированное, плавающее, натуральное, символьное, ключ БД.
Статья набора позволяет описать наборы БД. Формат задания набора имеет вид

Первое предложение статьи задает имя описываемого набора. Второе указывает имя типа записи, являющейся записью владельца набора. И последнее — на способ включения экземпляров записей— членов в экземпляры описываемого типа набора.
Обычно предполагается, что на внутреннем уровне экземпляры набора, включающие несколько членов записей, организованы в виде цепочки.
Цепочка записей реализуется с помощью специального служебного элемента — указателя, который содержит (указывает на) адpec записи, логически связанной с рассматриваемой. Посредством указателей можно организовать обращение не только к последующим записям, но и к предыдущим.
Команды, входящие в фигурные скобки третьего предложения схемы, как раз и позволяют организовать цепочку требуемым образом и означают:
FIRST — запись включается первой в цепочку перебора записей, т. е. сразу же после записи владельца (рис. 22.20).
LAST — запись включается последней (рис. 22.20).
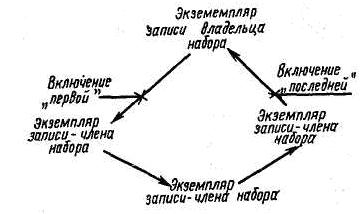
Рис. 22. 20. Реализация вариантов FIRST и LAST
NEXT — включение следующей записи, т. е. записи, следующей за текущей записью набора (рис. 22.21).
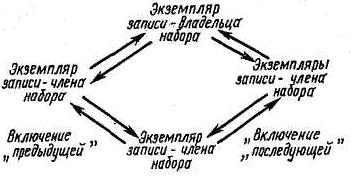
Рис. 22.21. Реализация вариантов NEXT і PRIOR
Под текущей записью набора понимается тот экземпляр записи конкретного экземпляра набора, на который указывает «текущая» запись, в типе набора.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 |
