
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
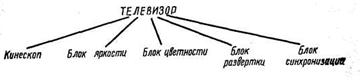
Рис. 22.29. Объединение агрегации
Понятие обобщения близко к понятию агрегации, но в отличие от последней, которая может быть представлена в виде составных частей, образующий некоторое «целое», обобщение связано только с «целыми». Обобщение относится к типу абстракции, в которой группа подобных элементов воспринимается как родовой элемент. При этом различия между отдельными элементами опускаются.
Например, УЧАЩИЙСЯ может быть воспринят как УЧАЩИЙСЯ школы, УЧАЩИЙСЯ ПТУ, УЧАЩИЙСЯ техникума.
Так же как и агрегация, обобщение может встречаться в двух формах:
1. В одном локальном представлении определено некоторое множество объектов, которое может быть объединено общим для этих объектов родовым понятием, а само оно указано в другом локальном представлении.
Пример.
I представление II представление
Цветные телевизоры Телевизоры
Черно-белые телевизоры
Здесь родовым понятием, объединяющим оба представления, будет ТЕЛЕВИЗОР.
2. Ни одно из объединяемых локальных представлений не содержит родового понятия.
I представление II представление
Цветные телевизоры Переносные телевизоры
Черно-белые телевизоры
В этом случае установить наличие родовой связи между специфичными типами объектов можно только в процессе сопоставления объектов из различных локальных представлений.
Использование объединения обобщением позволяет повысить эффективность доступа пользователей к данным, хранящимся в базе.
При формировании глобального представления данных путем комбинированного использования идентичности, агрегирования и обобщения можно отобразить в модели сложные связи, существующие между объектами и понятиями в предметной области.
Сам процесс объединения локальных представлений обычно носит интерактивный характер. В целях упрощения процесса объединения обычно осуществляют бинарное объединение, т. е. на каждом этапе объединяются только два локальных представления. Процесс попарного объединения повторяется для всех локальных представлений до тех пор, пока все они не будут интегрированы в одно глобальное (рис. 22.30).

Рис. 22.30. Бинарное объединение
В процессе объединения могут выявляться противоречия между отдельными локальными представлениями. Противоречия обусловлены обычно неполнотой или ошибочностью спецификаций или же некорректностью требования. Так, например, в одном локальном представлении связь между объектами может быть отнесена к типу 1 :1, а в другом —типу 1 :М или М:1. Большинство из противоречий такого вида может быть разрешено на этапе объединения путем выполнения соответствующих коррекций. Процесс объединения требует согласования и устранения всех выявленных противоречий.
После завершения объединения полученное глобальное представление служит исходной информацией для даталогического этапа проектирования БД. Данный этап предусматривает полученное инфологическое описание предметной области отобразить в описание БД.
Естественно, что отображение одного описания в другое будет зависеть от принятой за основу модели данных, поддерживаемой соответствующей СУБД. Существующие СУБД по виду поддерживаемой модели могут быть отнесены к одному из трех классов: реляционные, сетевые, иерархические.
В случае реляционной СУБД описание предметной области трансформируется в реляционную схему. Объекты при этом отображаются в отношения БД.
В случае сетевой СУБД описание предметной области отображается в граф. Типы объектов (сущностей) представляются в типы записей, а типы связей — в типы наборов.
В случае иерархической СУБД описание предметной области преобразуется в множество деревьев. Типы сущностей при этом также будут отображены в типы записей, а типы связей — в типы «исходный-порожденный».
Процесс этих преобразований является неформальным и во многом зависит от проектировщика.
Принципы проектирования физической базы данных. Физическая организация данных оказывает существенное влияние на эксплуатационные характеристики проектируемой БД, такие, как объем занимаемой памяти, время отклика базы на запрос пользователя и т. д.
Под проектированием физической БД будем понимать процесс создания эффективной ее структуры на выбранной логической
структуре.
Физическая база данных представляет собой совокупность совместно хранимых взаимосвязанных данных, состоящих из одного или нескольких типов хранимых записей.
Понятие структуры физической БД включает: формат хранимой записи, структуру путей доступа к данным и размещение записей на физических устройствах. Наиболее простой формой хранения данных в памяти ЭВМ является линейный список. Линейный список представляет собой конечное и упорядоченное множество объектов {х[1], х[2], ..., х[п]}, структурные свойства которого связаны только с линейными относительным расположением элементов данных. Порядковый номер, расположенный в квадратных скобках, указывает на относительное положение элементов в списке.
Линейные списки, естественно, используются в тех случаях, когда встречаются упорядоченные множества данных переменного размера и где операции включения, поиска, удаления элемента данных должны выполняться в произвольных местах.
Одномерный линейный список, используемый для хранения данных в памяти ЭВМ, называют также вектором данных.
Для линейного списка существует две возможности представления в ЭВМ: последовательное и связанное.
Последовательное представление. Является более простым и предполагает, что элементы списка размещаются в последовательных элементах памяти ЭВМ (рис. 22.31).
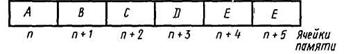
Рис. 22.31. Последовательное распределение памяти для представления линейного списка
При таком представлении списка возникают определенные сложности в реализации вставки нового элемента в середину. Например, чтобы включить в список между элементами D и Е новый элемент К, необходимо изменить место элементов Е и F. Точно так же удаление элемента из списка ведет к появлению в списке пустой ячейки и для его уплотнения необходимо осуществлять смещение оставшихся элементов.
Связное представление. Оно предусматривает задание для каждого элемента списка отношений следования и предшествования с помощью указателей, задающих связь между данными. При таком представлении каждая ячейка содержит элемент данных и указатель (адрес) на последующий элемент списка. При связанном распределении не требуется, чтобы список хранился в последовательных элементах памяти (рис. 22.32).
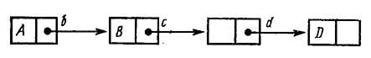
Рис. 22.32. Связанный список данных
Добавление или исключение некоторых данных в этом случае можно выполнить с помощью простой операции изменения значения указателя (рис. 22.33).
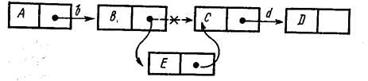
Рис. 22.33. Пример включения элемента в связанный список данных
Таким образом, использование связанных списков более удобно в случае динамически изменяющихся линейных структур.
Списки могут быть и двусвязанными (рис. 22.34).

Рис. 22.34. Двусвязанный список данных
При таком задании списка необходимо кроме прямого указателя для каждого элемента вводить в рассмотрение и обратный.
Структура линейного списка, представленная с помощью связанного распределения, называется также цепной структурой или цепью. Физическая последовательная и связанная структуры являются основными для большинства числа методов доступа к данным.
Методы доступа. Под методом доступа понимается совокупность технических и программных средств, обеспечивающих возможность хранения и выборки данных, расположенных на физических устройствах ЭВМ. В методе доступа выделяют два компонента: структура памяти и механизм поиска.
Наиболее широко используемыми методами доступа являются: последовательный; прямой произвольный; индексно-последовательный; индексно-прямой; основанный на использовании явных древовидных структур.
Последовательный доступ. Он реализует доступ к данным базы путем последовательного просмотра записей.
Рассмотрим случай, когда физически последовательная структура содержит несколько смежных записей. Записи могут быть неупо-рядочены или упорядочены по значениям первичного ключа. Обычно каждая запись располагается в отдельном блоке.
Среднее количество физических блоков Ncp, к которым осуществляется доступ при поиске произвольной записи, равно Ncp=(1+N)/2. Данное выражение справедливо как для упорядоченных, так и неупорядоченных записей при условии, что искомая запись существует. В случае если искомая запись отсутствует, то для
неупорядоченного файла Ncp = N, т. е. будут проверены все записи. Таким образом, неупорядоченный файл является неэффективным, если приходится часто обращаться к поиску отсутствующей записи.
Поскольку внесение изменений в произвольном порядке в последовательную структуру требует большого количества операций по перемещению записей, режим внесения изменений строго ограничивают.
Прямой доступ. В том случае, когда имеется возможность выделить в памяти для каждой записи место, определяемое уникальным значением ее первичного ключа, можно построить простую функцию преобразования ключа в адрес, обеспечивающую запоминание и выборку каждой записи в точности за один произвольный доступ к блоку.
Использование прямого доступа позволяет эффективно с точки зрения временных затрат осуществлять поиск данных в базе.
Методы прямого доступа подразделяются на две группы:

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 |
