
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Задачу кластеризации можно разными способами видоизменять. Например, можно, как в задаче многоклассовой классификации, строить кластеризатор ![]() для каждой точки х пространства признаков вычисляющий не только решение arg maxj fj(x) (помер кластера), но и уверенность в нем, равную maxj fj(x). Такой кластеризатор заодно может решать задачу обнаружения выбросов.
для каждой точки х пространства признаков вычисляющий не только решение arg maxj fj(x) (помер кластера), но и уверенность в нем, равную maxj fj(x). Такой кластеризатор заодно может решать задачу обнаружения выбросов.
Обучать такой кластеризатор можно следующим образом: потребовать, чтобы его решения удовлетворяли обычным вероятностным нормировкам ![]() и
и![]() и решать для обучающего набора X максимизационную задачу
и решать для обучающего набора X максимизационную задачу
![]() (1)
(1)
Для решения этой задачи возьмем какой-нибудь метод обучения классификаторов, максимизирующий суммарную оценку уверенностей распознавателя в ответе на обучающем наборе, и какую-нибудь, хоть бы и случайную, кластеризацию. Обучим классификатор классифицировать в соответствии с этим назначением кластеров. Затем каждый вектор признаков из обучающего набора классифицируем с помощью обученного классификатора. Хотя классификатор и обучался на этом же самом обучающем наборе, для некоторых обучающих векторов его ответ может отличаться от того, чему его учили. Для полученного разбиения на классы снова обучим классификатор, затем в соответствии с результатами обучения снова подправим классификацию и т. д. При обучении сумма уверенностей (1) монотонно не убывает. Обучение останавливается, когда эта сумма перестает возрастать. При таком обучении классификатор учится классифицировать не так, как задано в каком-то обучающем наборе, а так, как ему удобно максимизировать уверенность в своей работе. Результат обучения кластеризатора сильно зависит от начального разбиения на кластеры.
Подробно эмпирические методы выбора начального разбиения или, что эквивалентно, начального состояния классификаторов, здесь не обсуждаются. Например, можно начинать обучение так: выбрать из обучающего набора несколько случайных векторов, по одному на кластер, объявить их принадлежащими разным классам и обучить классификатор только на них, после чего продолжать обучение уже на всем обучающем наборе. Во время обучения тоже могут возникнуть неоднозначности, разрешаемые довольно произвольно. К какому кластеру отнести вектор, для которого некоторые из уверенностей в принадлежности к разным кластерам совпадают (варианты: к случайному, к кластеру с меньшим номером, к кластеру с меньшим количеством векторов, что в свою очередь неоднозначно.. . .)? Что делать, если какой-то кластер стал пустым (варианты: не обращать внимании, продолжать кластеризацию с меньшим числом кластеров, создать этот кластер заново, поместив в него вектор с наименьшей уверенностью,...)?
В качестве примера рассмотрим байесовский q-классовый классификатор на d-мерном евклидовом пространстве признаков ![]() для следующей порождающей модели: вероятности р(у) всех классов равны 1/q, а плотности условных вероятностей р(х|у) являются гауссовыми с единичной матрицей ковариации
для следующей порождающей модели: вероятности р(у) всех классов равны 1/q, а плотности условных вероятностей р(х|у) являются гауссовыми с единичной матрицей ковариации
![]()
Обучение модели состоит в подборе q векторов μ1,...,μq в пространстве ![]() При обучении методом наибольшего правдоподобия на обучающем наборе
При обучении методом наибольшего правдоподобия на обучающем наборе![]() с каким-то распределением у1,…,,уN обучающих векторов по кластерам, максимизируется произведение вероятностей
с каким-то распределением у1,…,,уN обучающих векторов по кластерам, максимизируется произведение вероятностей
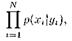
т. е. минимизируется сумма
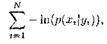
что эквивалентно минимизации суммы квадратов
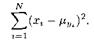
Квадратичная минимизация сводится к очень простой системе линейных уравнений, которая элементарно решается. Ответ получается такой: ![]()
т. е. каждый вектор параметров μj сдвигается в центр тяжести (среднее арифметическое) обучающих векторов j-гo кластера. Затем каждый обучающий вектор хі переводится в тот кластер j, для которого оценка байесовского распознавателя ![]() максимальна, т. е. расстояние
максимальна, т. е. расстояние ![]() минимально. Снова обучается классификатор, снова пересчитываются кластеры, и т. д., пока правдоподобие не перестанет увеличиваться, т. е. распределение обучающих векторов по кластерам не перестанет изменяться.
минимально. Снова обучается классификатор, снова пересчитываются кластеры, и т. д., пока правдоподобие не перестанет увеличиваться, т. е. распределение обучающих векторов по кластерам не перестанет изменяться.
Этот пример обучения кластеризатора по совместительству является самым распространенным примером описываемого в п. 3.9.2 векторного квантования. Он обычно называется "k-means" (k средних), где k — обозначение числа кластеров (то, что выше обозначалось буквой q), a "means" — память о вычислении средних арифметических. Как правило, метод k-means сходится быстро. Напоминаем, что получающаяся кластеризация зависит от начальной кластеризации и не обязательно оптимальна.
Метод k-means легко обобщить, допустив в качестве плотностей условных вероятности гауссианы с любыми матрицами ковариации, в том числе и с разными матрицами для разных кластеров.
Количество кластеров k может быть фиксировано заранее, а может, аналогично обучению распознавателей с pегуляризадней, подбираться минимизацией суммы какою-либо зависящею от k штрафа "за сложность" и убывающей функции от уверенности (1). Стандарных рецептов, как именно штрафовать и как минимизировать по дискретному параметру k, нет.
3.9.2. Векторное квантование и понижение размерности
Широко распространена следующая модификация задачи кластеризации. Одновременно с поиском хорошей кластеризующей функции f: →![]() бyдем искать "функцию центров" с: сопоставляющую каждому кластер y его типичного представителя с(у) называемого центром кластера. Желательно, чтобы центр кластера был достаточно близок ко всем объекам познания и созидания этого кластера.
бyдем искать "функцию центров" с: сопоставляющую каждому кластер y его типичного представителя с(у) называемого центром кластера. Желательно, чтобы центр кластера был достаточно близок ко всем объекам познания и созидания этого кластера.
В такой постановке задача кластеризации обычно называется векторным квантованием (vecloi quantization). Векторное квантование чаще всего применяется при необратимом сжатии информации для хранения или передачи по линиям связи. Информация любой природы представляется, возможно искусственно, в виде последовательности векторов признаков лежащих в пространстве признаков ![]() . При кодировании (сжатии) каждый вектор кодируется номером кластера, которому он принадлежит. При декодировании (раздутии) каждый номер кластера заменяется на его центр
. При кодировании (сжатии) каждый вектор кодируется номером кластера, которому он принадлежит. При декодировании (раздутии) каждый номер кластера заменяется на его центр
Задачу векторного квантования можно формализовав в том же стиле, что и задачу распознавания. Имеется:
пространство (векторов) признаков ![]() , точками которого кодируются квантуемые объекты и созидания, например d-мерное евклидово пространство Rd или любое метрическое пространство;
, точками которого кодируются квантуемые объекты и созидания, например d-мерное евклидово пространство Rd или любое метрическое пространство;
пространство кластеров обычно конечное, хотя возможны и обобщения;
пространство![]() кластеризующих функций f: , например, любых функций из
кластеризующих функций f: , например, любых функций из ![]() в
в ![]() ;
;
пространство С функций центров с: , как правило, пространство всех функций из ![]() в
в ![]() ;
;
пространство ![]() распределений (вероятностных мер) на
распределений (вероятностных мер) на ![]() , например, в случае евклидова пространства
, например, в случае евклидова пространства ![]() , — абсолютно непрерывных по мере Лебега, гауссовых смесей и т. п. ;
, — абсолютно непрерывных по мере Лебега, гауссовых смесей и т. п. ;
функция штрафа Е как правило неотрицательная и равная 0 при совпадении параметров, например, в случае евклидова пространства ![]() удобно взять
удобно взять ![]()
набор обучающих данных Х= (х1,…., хN), где ![]() считаются значениями независимых случайных величин с одним и тем же, но совершенно неизвестным распределением
считаются значениями независимых случайных величин с одним и тем же, но совершенно неизвестным распределением ![]() .
.
Необходимо по ![]() построить кластеризатор
построить кластеризатор ![]() и функцию центров
и функцию центров![]() минимизирующие ожидание штрафа
минимизирующие ожидание штрафа ![]()

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 |
