
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
найти непрерывно дифференцируемую кривую
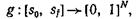
такую, что
![]()
![]()
![]() (где
(где![]() — скалярное произведение в RN),
— скалярное произведение в RN),
и такую, что
![]()
где криволинейный интеграл берется вдоль![]() — градиент функции обобщенного расстояния d* (g, h) от второго арумента, взятый при h=g.
— градиент функции обобщенного расстояния d* (g, h) от второго арумента, взятый при h=g.
Для экономии места производная точных формул для обобщения будет опущена.
Поскольку реальный расчет геодезических кривых на F(X) может быть слишком сложным, субоптимальное решение можно получить, следуя по линии «наименьшего сопротивления» от g0 к f, т. е. принимая v(s) за единичный вектор в конусе
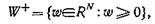
для которого скалярное произведение
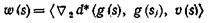
минимально.
Кластеризуемость
Геодезический подход к определению путей склеивания и, следовательно, иерархических таксономии в X, не обязательно дает семейство кривых, обладающих свойством определять единственный путь от каждого соответствующего нечеткого подмножества g множества f к множеству f.
Несмотря на то, что в большинстве прикладных задач эта трудность легко преодолевается с помощью правил, учитывающих природу конкретной задачи, отмеченное отсутствие единственности представляет теоретический интерес как свидетельство того, что структура подобия может все-таки определять и единственную таксономическую структуру на множестве.
Легко видеть, что экстремальные примеры столь бедных структур подобия характеризуются оптимальностью каждого пути склеивания.
Поэтому индуцируемая структурой подобия четкость определения геодезических путей есть хороший показатель «кластеризуемости». Важно отметить, что такие показатели имеют локальную природу, т. е. они описывают возможности кластеризации в окрестности точки множества F (X) (т. е. нечеткого подмножества X с непустым ядром) и, таким образом, оказываются полезными для идентификации подмножеств выборочных данных, трудных для классификации.
Точно так же, как значение второй производной действительной функции действительной переменной в окрестности точки минимума есть хороший показатель четкости изгиба кривой около этой точки, примеры количественных мер кластеризуемости в окрестности нечеткого подмножества g зависят от вариаций второго порядка минимизируемых функций. Один такой пример дают меры, связанные со второй вариацией функции длины L(g) (всякий раз, когда такая вариация определена) около геодезической кривой g*.
3.10.6. Представления и кластеризации
Одна из главных характеристик излагаемой здесь теории кластеризации состоит в проведении семантического и формального разграничения понятия кластера и кластеризации.
В предыдущем пункте приведено определение кластеров как особых подмножеств выборочного множества и обсуждены вопросы, связанные с этим определением.
Данный пункт в первую очередь посвящен проблеме представления выборок с помощью нечетких кластеров. В отличие от проблемы определения кластера, где требования, которым должны удовлетворять нечеткие кластеры, можно было установить в общем виде, проблема определения «адекватного» представления существенно зависит от контекста прикладной задачи. Далее кратко обсуждаются два подхода для случаев, когда цель проблемы представления неформальным образом можно охарактеризовать как поиск наиболее экономичного описания выборки с помощью нечетких кластеров. До конца пункта будет предполагаться, что исходное множество X содержит конечное число точек.
Минимальные представления
При первом подходе к описанию множества через кластеры выдинутые идеи обобщаются с помощью идентификации функционалов, определенных на множестве всех возможных представлений, которые затем оптимизируются для получения желаемой кластеризации. В этом случае основное отличие состоит в дололнительном условии, которое ограничивает множества компонентов представления нечеткими кластерами.
Определение. Пусть r — отношение похожести в X и пусть с и f — нечеткие подмножества X. Если
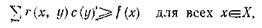
где суммы берутся по всем у![]() Х, то с называется нечетким r-представленпем нечеткого подмножества f (или, короче, просто представлением).
Х, то с называется нечетким r-представленпем нечеткого подмножества f (или, короче, просто представлением).
Примечание. Это определение выявляет формальный смысл понятия представления через требование, согласно которому выборочное множество f должно представляться линейной комбинацией нечетких кластеров в X (всех тех, которые имеют степень принадлежности 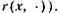 Особо отметим, что выведенное из модифицированной алеф-1 логики выражение для объединений нечетких множеств — выражение аддитивного типа.
Особо отметим, что выведенное из модифицированной алеф-1 логики выражение для объединений нечетких множеств — выражение аддитивного типа.
Определение. Пусть Н есть функция, отображающая нечеткие подмножества X в неотрицательные действительные числа. Тогда если с* таково, что а) с* есть представление f, для любого с-представления f, то с* называется Н-минимальным представлением f (или, короче, минимальным представлением).
Среди всех возможных определений для представления функционала Н имеются и такие, которые удовлетворяют ряду свойств, предъявляемых в качестве основных требований для любого такого функционала. Формулировка этих свойств и аксиоматическое определение функционалов, которые удовлетворяют им, показывают, что семейство функционалов
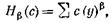
(где суммирование ведется по X и β — действительное число в открытом (0, 1) интервале числовой прямой) обладает определенными желаемыми характеристиками представления.
Итеративное порождение кластеров
Второй тип подходов отличается тем, что все нечеткие кластеры, которыми можно представить выборку, полностью характеризуются теоремой существования нечетких кластеров. Функция принадлежности для этих кластеров непосредственно связана с функцией подобия.
Поскольку кластеры, имеющие большие пересечения с выборочным множеством, более предпочтительны как компоненты экономичного представления, чем те, которые не пересекаются с ним, то рассмотрение подходов к проблеме представления, используемых в факторном анализе, приводит к следующему определению.
Определение. Пусть х — точка множества X, r — отношение похожести в X, f — нечеткое подмножество X. Если через rz обозначить нечеткое подмножество X, определенное выражением
то rх будет называться главной компонентой f тогда и только тогда, когда для всех у![]() Х
Х
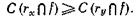
Несмотря на то, что в приведенной формуле можно использовать любое подходящее определение операции взятия пересечения нечетких множеств, однако отношение похожести и модифицированная логика алеф1, рассмотренные в п.3.10.4, предопределяют, что наилучшим вариантом выражения, максимизация которого (по всем х![]() Х) определит главную компоненту, будет
Х) определит главную компоненту, будет
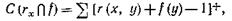
где сумма берется по всем у![]() Х.
Х.
Как только главная компонента rх определена (их может существовать несколько), не охваченная классификацией часть выборки
![]()
может быть сама по себе исследована для выделения основных компонент. Этот процесс может продолжаться до тех пор, пока не выполнится условие 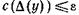 для некоторого малого положительного ε.
для некоторого малого положительного ε.
В заключение отметим, что представленные в этом разделе теоретические результаты дали возможность установить формальные и семантические связи между понятиями кластеризации, ранее введенными чисто эвристическим образом. Использование строгого аксиоматического подхода позволило идентифицировать связи между понятиями кластера, прототипа кластера, иерархической таксономии и кластеризуемости множества. Кроме того, понятие кластера (подмножества исходного выборочного множества, обладающего определенными специальными свойствами) было отделено от понятия кластеризации (в определенном смысле описания выборочного множества через его кластеры).
Это основание для рационального обсуждения вопросов, относящихся к проблемам автоматической классификации, используется в ряде исследований, которые включают:
1) сравнительное изучение различных подходов к представлению с точки зрения их применимости к классификации данных больших выборок,
2) разработку адаптивных процедур кластеризации, которые непрерывно и автоматически модифицируют таксономии в ответ на динамические изменения базовой структуры подобия,

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 |
