
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Одной из целей исследования, был анализ возможности обобщений понятия кластера с помощью объединяющих вложений. Соответственно общему подходу и в этом случае осуществлено стремление к строгому развитию результатов на базе ряда хорошо определенных задач, а не к изучению свойств эвристических формул объединения.
Общие цели, от которых обычно зависит подходящее направление обобщения, состояли в следующем:
1. С использованием понятия «склеивание» предполагалось по отношению подобия r, определенному на X, найти обобщение r*,
определенное на F(X2). Другими словами, нечеткие подмножества X желательно рассматривать как возможные объединения, и соответствующие обобщения r искать так, чтобы получить разумное отношение подобия между нечеткими множествами.
2. Выражение для оценки подобия между двумя нечеткими подмножествами f и g должно зависеть от значений функций принадлежности f и g и от степеней подобия r(х, у), таких, что или
![]() или
или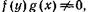 но не от каких других значений r.
но не от каких других значений r.
Заметим, что в результате склеивания получают нечеткие множества общего вида (с непустыми ядрами) и не ограничиваются нечеткими кластерами.
3. Сужение расширения r* на прямое произведение X2 (при естественном вложении элементов X как одноэлементных четких подмножеств X и, следовательно, как нечетких подмножеств множества X) должно быть эквивалентно r. Это условие гарантирует, что r* есть расширение r.
4. Если r — отношение похожести в X, то расширение r* должно быть отношением похожести в F (X).
Интерполяция по прототипам
Определение расширения функции подобия r на F(X) может рассматриваться как эквивалент определению подобия между воображаемыми центрами тяжести каждой нечеткой склейки. Каждая такая функция подобия будет определять подобие между нечеткими объединениями как взвешенное среднее степеней подобия между точками х, причем весовые значения определяются степенью принадлежности каждой точки соответствующим склейкам. Это — основная идея, обосновывающая представления для четкого случая. Для того чтобы получить приводимые далее формулы, в настоящем исследовании выдвигается дополнительное условие «евклидовой согласованности».
Для характеристики понятия «евклидовой согласованности» нужно дать следующее определение.
Определение. Центроидом нечеткого подмножества f евклидова пространства Rn называется точка xf, определенная выражением
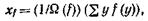
где суммирование проводится по точкам носителя f.
Условие «евклидовой согласованности» можно сформулировать в следующем виде.
Определение (евклидовой согласованности). Пусть X — подмножество евклидова пространства Rn и пусть функция подобия r есть дополнение евклидова расстояния d в X. Тогда расширение r до r*, равное дополнению к евклидову расстоянию между центроидами нечетких подмножеств из R (при котором предполагается переход от нечеткого множества к центроидному отображению и к евклидову расстоянию в выпуклой оболочке множества X), называется расширением (и единственным) R до X, удовлетворяющим условию евклидовой согласованности.
Введение понятия евклидовой согласованности гарантирует, что в евклидовом случае расширение будет согласовано с нашим собственным интуитивным представлением о расстоянии между центроидами в евклидовых пространствах. Кроме того, важность включения евклидовой согласованности как одного из условий подтверждается следующими результатами, которые связывают его с отношением похожести и, следовательно, с проблемой существования нечетких кластеров.
Теорема. Пусть r — отношение подобия в ![]() Если r есть
Если r есть
дополнение евклидова расстояния d в X, то его однозначное расширение r* удовлетворяет свойству евклидовой согласованности и определяется выражением
![]() (*)
(*)
где![]()
и где все суммы берутся по теоретико-множественному объединению носителей f u g.
Теорема. Пусть f и g — нечеткие подмножества исходного конечного множества X. Пусть r — отношение подобия в X и Q*(f, g) определяется выражением
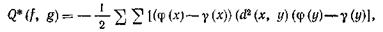
где φ и γ те же, что и в (*); d=1—r, и все суммы берутся по теоретико-множественному объединению носителей f и g.
Чтобы величина Q*(f, g) была неотрицательной для всех пар (непустых ядер) нечетких подмножеств f и g в F(X), необходимо и достаточно, чтобы r было отношением похожести. Если r — отношение похожести, то Q* определяет отношение подобия r* в F(X):
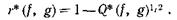
К тому же r* само есть отношение похожести в F(X).
Таким образом, отношения похожести не только гарантируют существования кластеров в X, но и могут быть расширены до отношения похожести на множество F (X) всех нечетких множеств X с непустыми ядрами. Расширение r* можно использовать (формируя нечеткое фактор-множество множества F(X) по r*) для определения нечетких кластеров, имеющих нечеткие подмножества X в качестве типичных элементов (т. е. обобщенных «центроидов»).
Иерархические кластеры и геодезические пути
Теперь, используя представленные ранее теоретические результаты, можно рассмотреть формально заложенную в процедуры объединения эвристическую идею получения иерархической таксономии выборочных данных.
Процесс, с помощью которого (в традиционном контексте) к растущим кластерам добавляются точки до тех пор, пока не закончится классификация всей выборки (т. е. пока не будет достигнут корень дерева), можно рассматривать как процесс нахождения пути, который начинается в одноэлементном подмножестве {х} множества X и проходит по возрастающим по мощности элементам множества Р(Х) всех подмножеств множества X, пока не достигнет всего выборочного множества X.
Аналогично этому в нечетком случае путь склеивания можно рассматривать как непрерывную кривую, проходимую процессом склеивания во множестве F(X) всех нечетких подмножеств X с непустыми ядрами. Этот путь опять начинается в соответствующем нечетком подмножестве выборочного множества, проходит по все большим и большим нечетким подмножествам X (бóльшим — в смысле включения нечетких множеств), пока, наконец, не достигнет полного множества f выборочных данных. Однако в отличие от обычного случая проходимые на пути склеивания нечеткие подмножества становятся не кластерными компонентами таксономии, а скорее, как это обсуждалось, их прототипными элементами.
Поскольку в нечетком случае путь, который объединяет нечеткие подмножества f с полным выборочным множеством f непрерывный, то для анализа вопросов, связанных с задачей определения их путей, можно применять все методы непрерывного анализа.
Так как в силу рассмотренного обобщения понятия кластера множество F(X) представляет собой непрерывное метрическое пространство, то свойства путей склеивания можно описать в терминах структуры расстояния. Из всех возможных свойств, которыми должен обладать путь склеивания, особенно привлекательно, чтобы он был минимальным или геодезическим путем. Это условие интересно по крайней мере, с двух точек зрения.
1. Длина пути между двумя нечеткими подмножествами f и g представляет собой предел суммы расстояний (т. е. криволинейный интеграл) вдоль пути. Каждый член в этих суммах есть расстояние между двумя последовательными элементами ломаной, которая аппроксимирует криволинейный путь. Таким образом, кривая, колеблющаяся между различными нечеткими множествами (в ранее обсуждавшемся смысле) будет иметь бóльшую длину, чем кривая, соединяющая данные конечные точки и проходящая через «близкие» элементы F(X). Поэтому общая длина пути представляет собой адекватную классификационную характеристику пути, рассматриваемого как способ организации подмножсств множества X в иерархическую структуру, наилучшим образом отображающую существующую метрическую структуру множества X. Следовательно, определение геодезических путей эквивалентно оптимизации этой меры адекватности.
2. Принцип оптимальности Беллмана гарантирует, что дуги оптимального пути будут также оптимальными частями пути между конечными точками.
Следовательно, два оптимальных пути, исходящих из нечетких подмножеств g1 и g2 и пересекающихся в общей для них точке могут быть оптимально продолжены от h до f. Получающееся в результате семейство оптимальных путей образует иерархическую структуру, имеющую своим корнем выборочное множество f.
Если предположить, что X содержит конечное число N точек и если нечеткие множества в X представлены векторами, имеющими N действительных компонент (каждая из которых принадлежит [0, 1]), то проблему определения оптимального пути склеивания можно формально описать следующим образом ( обычных производных и общих дифференциальных выражениях употребляется буква δ во избежание путаницы с функцией расстояния d):

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 |
