
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
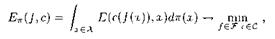 (2)
(2)
где ![]() . Как и в случае распознавания, можно сложную задачу минимизации интеграла подменить задачей минимизации приближающей его суммы
. Как и в случае распознавания, можно сложную задачу минимизации интеграла подменить задачей минимизации приближающей его суммы
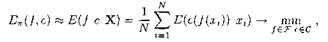 (3)
(3)
но тогда, чтобы обеспечить малость ожидания штрафа (2) можем понадобиться регуляризация. Следует обратить внимание на то, что отображения f и с входят в формулы (2) и (3) только в виде композиции с ◦ f.
Дальше, как и в случае распознавания можно забыть про вероятностную модель и решать задачу, подобную (3), а качество полученного квантования оценивать экспериментально, вычисляя штраф ![]() на независимом тестовом наборе X'. А можно продолжать изучать вероятностную модель и перенести на случай кластеризации и векторного квантования соображения об апостериорной вероятности или байесовском обучении.
на независимом тестовом наборе X'. А можно продолжать изучать вероятностную модель и перенести на случай кластеризации и векторного квантования соображения об апостериорной вероятности или байесовском обучении.
В таком виде задача обучения осмысленна и полезна не только при конечном пространстве ![]() , но при любом. Например если
, но при любом. Например если ![]() и
и ![]() — евклидовы пространствa dim(
— евклидовы пространствa dim(![]() )< dim(
)< dim(![]() ), а клacc С состоит из гладких или линейных функций, то обучение квантованию равносильно поиску dim(
), а клacc С состоит из гладких или линейных функций, то обучение квантованию равносильно поиску dim(![]() )-мерного подмножества (гладкой поверхности или плоскости, соответственно), хорошо аппроксимирующего встречающиеся вектора признаков. Но называется эта задача уже не квантованием, а понижением размерности (dimension reduction)
)-мерного подмножества (гладкой поверхности или плоскости, соответственно), хорошо аппроксимирующего встречающиеся вектора признаков. Но называется эта задача уже не квантованием, а понижением размерности (dimension reduction)
Квантование и понижение размерности можно рассматривать как частный случай задачи регрессии: пространство ответов ![]() совпадает с пространством признаков
совпадает с пространством признаков ![]() , и нужно приблизить тождественное отображение с помощью отображений вида с◦f, множество значений которых либо конечно (квантование), либо маломерно (понижение размерности)
, и нужно приблизить тождественное отображение с помощью отображений вида с◦f, множество значений которых либо конечно (квантование), либо маломерно (понижение размерности)
Такие методы классической статистики как факторный анализ (FA, factor analysis) и анализ главных компонент (РСЛ principal component analysis) также являются методами понижения размерности, работающими в предположении гауссовости распределений р(х}у).
3.10. Нечеткие кластеры
В разделе рассматриваются вопросы применении понятий теории нечетких множеств к неявной классификации. Они включают аксиоматический вывод понятий кластера и разбиения на кластеры, формальные условия существования кластеров и связи между такими формальными подходами и формулировками многозначной логики, особенно логики Лукасевича алеф 1. Рассматриваются также теоретические основы для оценки «кластеризуемости» выборки данных и для разработки методов иерархического разбиения на нечеткие кластеры.
3.10.1. Введение в нечеткий кластер-анализ
Методы математической классификации привлекали большое внимание исследователей и привели к созданию одного из основных классов автоматизируемых процедур, предназначенных описывать структурные характеристики выборочного множества по описаниям его компонентов.
Открытие структур, которые нелегко заметить с помощью стандартных процедур анализа данных, имеет первостепенную важность для понимания того, какие отношения регулируют поведение реальных систем. Появившаяся возможность выявить организационные схемы привела к широкому использованию классификационных процедур в прикладных и социальных науках познания и созидания.
Однако полезность процедур классификации ограничена двумя факторами.
Во-первых, большинство предложенных методов опирается на эвристические соображения, возникающие из конкретных приложений понятия классификации к частным задачам познания и созидания. Попытки расширить сферу применимости выведенных таким образом процедур часто дают неудовлетворительные результаты. Применение этих методов при решении конкретных задач познания и созидания приводит к различным классификациям, зависящим от использованной процедуры, и не позволяет проникнуть в сущность причин, вызывающих таксономические различия, и подвергнуть их аналитическому исследованию. В случаях, когда такие исследования проводились, обнаруживалось, что процедуры, подогнанные под характеристики конкретного примера познания и созидания и механически примененные для другого случая, оказывались непригодными для решения задачи.
Во-вторых, большинство предложенных процедур пытались применять для классификации точек по принадлежности к подходящим множествам по степени подобия между точками выборочных данных. Но это, как будет подробнее рассмотрено в п. 3.10.3, недостижимая цель для большинства практических применений, и так поставленная проблема познания и созидания может не иметь решения. Искусные усовершенствования процедур, обычно используемые для разрешения этой проблемы познания и созидания, такие как деформация первоначальной меры подобия (как это делается, например, в односвязывающем методе) или ослабление классификационных требований (например, некоторые сходные точки разрешается относить к разным классам) совершенно неприемлемы вследствие плохого качества полученных результатов.
Для успешной постановки этих проблем познания и созидания в данном разделе будем придерживаться строгой аналитически развитой методологии, основанной на аксиоматической теории, которая объясняет и связывает различные понятия и подходы, используемые в кластерном анализе, для получения осмысленных и полезных решений проблемы классификации в качестве основы для описания как выборочных данных, так и их классификаций, предлагается использовать теорию нечетких множеств. Существенная особенность излагаемого материала состоит в систематическом введении соответствующих понятий на аксиоматической основе и идентификации отношений между полученными таким образом понятиями и основными положениями теории нечетких множеств и нечеткой логики.
В п.3.10. 2 кратко рассматривается логическое обоснование нечеткого кластер-анализа и затем обсуждаются основные неустранимые трудности, с которыми сталкиваются при решении проблемы кластеризации традиционными методами. В п.3.10.3 дается аксиоматическая разработка понятия кластера и устанавливаются условия существования кластеров в выборочных данных. В п.3.10.4 устанавливается связь между определением нечеткого кластера и формальной интерпретацией транзитивности нечеткого отношения в логике Лукасевича алеф1. В п.3.10.5 обсуждаются различные пути обобщения, проясняющие понятие кластера и ведущие к более глубокому пониманию понятия кластерного прототипа, чем обеспечивается важная характеризация проблем иерархической классификации выборки и оценки кластеризуемости или определения классификационного потенциала кластера. В п.3.10.6 понятие кластеризации противопоставляется понятию кластера и приводятся результаты, относящиеся к аксиоматическому определению понятия кластеризации как наиболее экономного способа представления выборки кластерами.
3.10.2. Нечеткие множества, нечеткие кластеры, нечеткая кластеризация
Нечеткая кластеризация как поход к представлению данных
Нечеткое разбиение на кластеры было введено как путь решения некоторых проблем представления традиционного разбиения на кластеры, позволяющий достигнуть осмысленных решений во многих классификационных проблемах, неподдающихся анализу с помощью традиционных методов.
Неформально проблему разбиения выборочного множества на классы можно сформулировать следующим образом:
«Сгруппировать точки выборочного множества в подмножества (называемые кластерами) так, чтобы подобные точки относились к одному и тому же подмножеству, а не подобные — к различным подмножествам».
В типичной задаче кластеризации предполагается, что подобие (не следует путать с нечетким отнощением эквивалентности, определенным Заде) между точками определяется с помощью функции, которая назначает неотрицательные действительные значения каждой паре точек выборочного множества.
Простые примеры, когда два или больше хорошо определенных множеств соединяются «мостиками» из внутренне связанных объектов выборки, показывают, что в общем случае не существует решения этой проблемы, если только не ослабить требования и не рассматривать ее решение в другом контексте. Как отмечает далее , теория нечетких множеств обеспечивает желаемый перенос выборов таксономических решений из дискретного метрического пространства в непрерывное пространство, в котором понятие «похожая классификация» можно определить более содержательно
Далее, теория нечетких множеств, заменяя строгую принадлежность множеству на непрерывную степень принадлежности, позволяет более удовлетворительно представлять точки, которые лежат снаружи ядра или прототипной части каждого кластера (например, «мостики»). Гносеологические рассмотрения показывают, что нечеткие множества более пригодны в качестве инструмента представления непрерывных кластеров, чем теория вероятностей.
Степень принадлежности служит для представления сходства точки с прототипным элементом кластера, а не вероятности ошибки в классификации.
Некоторые проблемы, возникающие при анализе нечетких множеств как нечетких кластеров
Методы, предложенные , опирались на определение нечеткой кластеризации как разбиения множества данных на совокупность его нечетких подмножеств. Оптимальная нечеткая кластеризация определялась как разбиение на нечеткие подмножества, доставляющие оптимальное значение некоторому функционалу, определенному на множестве всех возможных разбиений. Этот функционал определялся так, чтобы он соответствовал интуитивному понятию «качества классификации».

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 |
