
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Этот метод имеет те же свойства, что и метод Мура, приведенный в разд. С. Если не считать некоторых дополнительных арифметических операций, он менее трудоемок, чем метод Мура, так как значение функции и производной приходится вычислять в одной и той же точке x(k). Для метода Мура производную приходится вычислять с использованием интервала X(k). Это в общем случае требует больше затрат, чем вычисление значений в одной точке x(k). Если интервал F2 вычисляется легко, то метод (15) с р = 1 предпочтительнее метода Мура. Эти результаты полностью справедливы лишь в теории, когда вычисления считаются точными. Если мы хотим гарантировать локализацию нулей при реализации метода на компьютере, то должны учесть влияние погрешностей округления. Это делается путем реализации всех действий в виде машинных интервальных операций. В частности, нам требуется вычислять f'(х(k)), используя машинную интервальную арифметику. В этом случае метод (15) при р = 1 требует, если не считать нескольких арифметических операций, того же объема вычислений, что и метод Мура. Так как приходится вычислять еше и интервал F2, следует, видимо, предпочесть метод Мура, если нужно учитывать погрешности округления.
Следует упомянуть, что существует следующий метод:
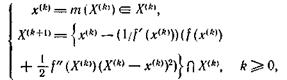
в предположении, что f дважды дифференцируема. Мы имеем ![]() Условия сходимости
Условия сходимости ![]() не приво-
не приво-
дятся. Если метод сходится, то последовательность d(X(k)) сходится к нулю квадратично, если ![]() По сравнению с методом (15) для р=1 мы должны на каждом шаге производить интервальное оценивание второй производной
По сравнению с методом (15) для р=1 мы должны на каждом шаге производить интервальное оценивание второй производной 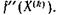 Это уменьшает постоянную сходимость, но не улучшает порядок сходимости. (То же верно для метода (15) при р= 1, если на каждом шаге заменить постоянный интервал F2 на
Это уменьшает постоянную сходимость, но не улучшает порядок сходимости. (То же верно для метода (15) при р= 1, если на каждом шаге заменить постоянный интервал F2 на 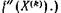 Использование этого метода на практике, т. е. с учетом погрешностей округления при вычислении
Использование этого метода на практике, т. е. с учетом погрешностей округления при вычислении![]() увеличивает объем вычислений еще примерно на треть. Так как сходимость не гарантирована, этот метод несколько менее привлекателен. Применяя метод (15), мы должны выбрать конкретный порядок р. Отметим еще, что при определенных предположениях метод (15) оптимален при р = 2, т. е. он является методом третьего порядка.
увеличивает объем вычислений еще примерно на треть. Так как сходимость не гарантирована, этот метод несколько менее привлекателен. Применяя метод (15), мы должны выбрать конкретный порядок р. Отметим еще, что при определенных предположениях метод (15) оптимален при р = 2, т. е. он является методом третьего порядка.
8.5. E. Интерполяционные методы
Как и в предыдущем разделе мы рассматриваем сходящиеся методы высшего порядка. На этот раз в основу положен хорошо известный интерполяционный метод нахождения нулей функции. Изменим его с помощью приемов из интервального анализа таким образом, чтобы всегда получать монотонную локализацию корней. Так же, как и в разд. D, нам нужны интервальные оценки старших производных функции f.
Различные методы определяются с помощью (п+l)-элементного множества неотрицательных параметров
![]()
Положим
![]()
и допустим, что
![]()
откуда следует, что r > 0 Мы хотим найти нyль 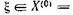
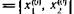 функции f, которая предполагается дифференцируемой нужное число раз в Х(0).
функции f, которая предполагается дифференцируемой нужное число раз в Х(0).
Теперь находятся интервалы Н и К, такие что имеет место
![]()
Чтобы описать очередной (k + 1 )-й шаг итерации, допустим, что мы уже имеем п+1 попарно различных приближений к нулю ξ:
![]()
и что последний из найденных локализующих интервалов Х(k) имеет вид ![]()
для некоторого![]() Допустим еще, что
Допустим еще, что
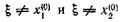
После исполнения описываемых ниже шагов (S1)—(S5) определяется улучшенный локализующий интервал — новая аппроксимация X(k+1)
(S1) Нахождение единственного интерполяционного многочлена Эрмита
удовлетворяющего интерполяционным условиям
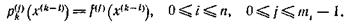
(Мы полагаем f(0) = f, и если mi = 0, то условия в точке x(k-i) отсутствуют.) Определяется интервал ![]() по формулам
по формулам
(S2) Нахождение вещественного корня yk многочлена pk(x) в интервале
Если такого корня нет, то переходим непосредственно к шагу (S5), положив
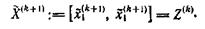
(S3) Вычисление интервала F(k), локализующего значение
![]() с помощью выражения
с помощью выражения
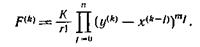
(S4) Вычисление улучшенного локализующего интервала по формуле
(S5) Нахождение нового приближения
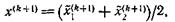
нового значения
и нового интервала
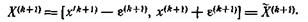
(Если оказывается, что некоторые из точек
 совпали между собой, то можно взять
совпали между собой, то можно взять 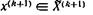 по формулам
по формулам

с подходящим ![]() гарантирующим несовпадение этих точек и соотношение
гарантирующим несовпадение этих точек и соотношение 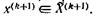 Такой выбор возможен всегда, когда
Такой выбор возможен всегда, когда
![]() Наконец, новое значение ε(k+1) выбирается по формуле
Наконец, новое значение ε(k+1) выбирается по формуле
что дает
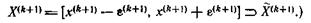
Следует отметить, что определение локализующих интервалов {X(k)} не использует перемен знака рассматриваемой функции. Это означает, что новый локализующий интервал будет вычислен всегда, даже если несколько последовательно вычисленных значений функции имеют один и тот же знак. Будет также показано, что шаги (S3) и (S4) могут быть пропущены лишь конечное число раз. Не требуется, чтобы локализующий интервал X(i) содержал какое либо из предыдущих приближений, кроме х(i). Свойства определенного выше алгоритма собраны в следующей теореме.
Теорема 6. Пусть f — вещественная функция, имеющая нуль ξ, для которого задан локализующий интервал
такой что
Пусть далее для ξ заданы попарно различные приближения
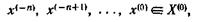
и производные функции f удовлетворяют условиям
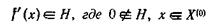
и
для интервалов Н, К и всех х в интервале Х(0) при заданных неотрицательных параметрах
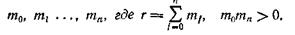
Тогда для итераций, заданных шагами (S1—S5), верны следующие утверждения:
![]() (19)
(19) ![]() (20)
(20)
или после конечного числа шагов последовательность стабилизируется на точке [ξ, ξ].
R-порядок итераций (S1) — (S5) (см. приложение А) (21)
равен![]() где s — единственный
где s — единственный
положительный корень многочлена
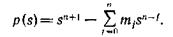
Доказательство (19): В силу (S1) мы имеем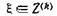 . Остаточный член интерполяционной формулы Эрмита дает
. Остаточный член интерполяционной формулы Эрмита дает
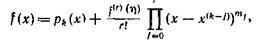
где число η лежит в интервале, образованном точками
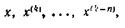

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 |
