

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
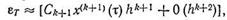 (8.76)
(8.76)
где х (k+1)(τ) — (k + 1)-я производная от решения x(t) в промежуточной точке tп < τ <tn+1; 0(hk+2) — члены отсечения, содержащие h в степени
k + 2 и выше и которыми обычно пренебрегают; Ck+1 — константа, характеризующая численный метод.
Например, для формулы Адамса—Мултона (8.51)
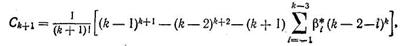
для формулы Гира (8.60) при постоянном шаге
![]()
для метода трапеций с учетом k = 1 С2 = 1/12 и др.
Следует отметить, что выражение (8.76) мало удобно для практических применений, поэтому для оценки локальной погрешности εт применяют различные косвенные методы.
Прежде всего, можно производные высоких порядков выразить приближенно через разности высоких порядков, используемые, например, в формуле (8.65):
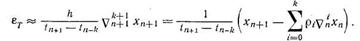 (8.77)
(8.77)
Далее можно применить экстраполяцию значений переменных xn+1(h) и xn+1(h/2), полученных интегрированием от точки tn до точки tn+1 один раз с шагом h и другой раз с шагом h/2, при этом
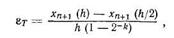 (8.78)
(8.78)
где k — порядок используемого метола интегрирования.
Наконец, можно использовать способ вложенных методов, когда на каждом шаге интегрирование выполняется дважды: методом порядка k и методом порядка k + 1. С помощью разности полученных значений
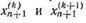
определим оценку локальной погрешности
![]() (8.79)
(8.79)
Здесь, как и при экстраполяции, имеется выбор: продолжать вычисления по значению, полученному методом порядка k или методом порядка k + 1.
Если учесть, что формулы прогноза (8.61), (8.63) и (8.64) имеют порядок на единицу больше, чем основные расчетные уравнения (8.60), (8.62) и (8.65), то к способу вложенных методов можно отнести следующую оценку локальной погрешности:
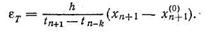 (8.80)
(8.80)
Следует отметить, что в выражение (8.80) входит то же значение х(0)п+1, которое используется в итерациях Ньютона при решении нелинейного уравнения (8.2). Справедливость уравнения (8.80) непосредственно следует из выражения (8.77), если учесть формулу (8.64).
Рассмотрим взаимосвязь локальной погрешности εт с общей (глобальной) погрешностью εmах, определяемой консультантом при моделировании различных консультируемых проблем и равной разности вычисляемых хп+1 и точных х*п+1 значений вектора переменных уравнений модели.
Чаще всего исходными при моделировании являются интервал интегрирования Т (t0, t0+T) и максимальная допустимая глобальная погрешность Еmах на этом интервале. Тогда допустимая на единичном шаге вычислений локальная погрешность определяется по формуле
![]() (8.81)
(8.81)
Экспериментальные исследования показывают, что при использовании выражения (8.81) решение получается часто более точным, чем требуется, особенно в начале интервала интегрирования, в результате чего выполняется завышенное число шагов вычислений.. Определенную избыточность решения можно уменьшить, если вместо соотношения (8.81) ввести другое, учитывающее действительный характер изменения переменных при решении уравнения модели объекта.
Например, линеаризация уравнения (8.1)
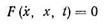
с учетом возможных аппроксимаций для производной вида (8.60)
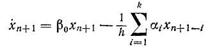
приводит к выражению:
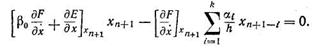 (8.82)
(8.82)
Теперь предположим, что общая погрешность невелика, так что производные, вычисленные при значениях хп+1 и х*п+1 можно считать равными, и учтем, что для точных значений вектора переменных уравнения модели консультируемой проблемы справедливо уравнение
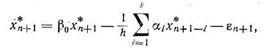
где
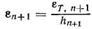
— локальная погрешность вычислений в единицу времени, определяемая с учетом уравнений (8.80) или (8.76). Тогда по аналогии с предыдущим записываем
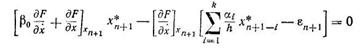 (8.83)
(8.83)
и, вычитая линеаризированные уравнения (8.82) и (8.83), находим искомое уравнение для общей (глобальной) погрешности
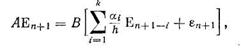 (8.84)
(8.84)
где
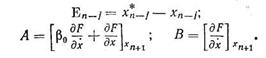
Следует отметить, что матрица А в полученном уравнении (8.84) совпадает с матрицей линеаризованного уравнения модели консультируемой проблемы, поэтому вычисления глобальной погрешности при известных матрицах L и U выполняются только процедурой прямой и обратной подстановок согласно выражениям (8.16) и (8.17). В результате оценка величины En+1 по выбранной εn+1 (и наоборот) не требует ни коренной переделки программы решения, ни чрезвычайно большего времени работы процессора.
Найденное по уравнению (8.84) значение общей погрешности En+1 используется наряду с максимально допустимой ее величиной Emax для управляемого выбора допустимого значения локальной погрешности
![]() (8.85)
(8.85)
где δ = 0,5 (0 < δ < 1) — коэффициент надежности, при этом выбирают εт, 0 = 0,1Еmах и ограничивают εт, min≠0.
Выражение (8.85) можно получить, если учесть из уравнения (8.84) ропорциональность Еn+1 и εn+1, а из выражения (8.76) зависимость h и εт, т. е. записать
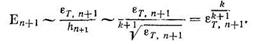 (8.86)
(8.86)
Стратегии выбора шага (порядка). Подставляя формулу (8.76) в выражение (8.81), находим взаимосвязь максимально допустимой погрешности на единичном шаге вычислений ε с максимальным размером шага h:
![]() (8.87)
(8.87)
которая изображена на рис. 8.3 для k = 1, 2, 3, и 4.
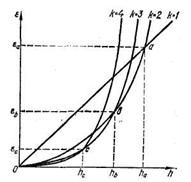
Рис. 8.3. Кривые зависимости допустимой погрешности на единичном шаге вычислений от изменений порядка k алгоритма
Из рисунка следует, что при ε>εа алгоритм первого порядка (неявный метод Эйлера) обеспечивает наибольший допустимый шаг вычислений, при εb< ε < εа — алгоритм второго порядка (метод Ших-мана), при εс< ε < εb — алгоритм третьего порядка и при ε < εс — алгоритм четвертого и более высоких порядков. Так как положение кривых на рис. 8.3 зависит от текущих значений Ck+1 и x(k+1)(tn+1), то даже при выбранном постоянном ε оптимальные порядок k алгоритма и шаг вычислений h могут изменяться от одного временного шага к другому. Как следует из рис. 8.3, любое увеличение допустимой погрешности ε не приведет к увеличению порядка формулы для максимизации шага вычислений и любое уменьшение ε не может привести к уменьшению оптимального порядка k используемого метода. Для достижения максимальной вычислительной эффективности целесообразно в процессе интегрирования одновременно изменять порядок алгоритмов и шаг с помощью многошаговых алгоритмов.
С точки зрения программирования изменение порядка алгоритма эквивалентно смене набора коэффициентов, определяющих ту или иную многошаговую формулу. При увеличении порядка k алгоритма увеличивается число коэффициентов в наборе. Это сопровождается ростом загрузки памяти ЭВМ для хранения «прошлых» значений вектора переменных, используемых для оценки приближения формулами высоких порядков. Как правило, указанные дополнения не требуют существенных затрат. Наоборот, изменение шага связано со значительными вычислительными затратами, так как часто хранимые «прошлые» значения вектора переменных, соответствующие шагу hj-1 необходимо интерполировать для получения преобразованных «прошлых» значений, соответствующих новому шагу вычислений hj. Процедура интерполяции упрощается, если «прошлые» значения хранить в виде вектора обратных разностей
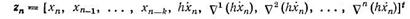
или в виде вектора Нордсика
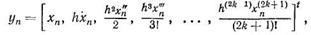
старые и новые значения которых связаны матрицей, НЭ которой зависят только от коэффициента q = hj/hj-1.
Успешно используются разные стратегии изменения порядка и шага методов интегрирования. В соответствии с одной из них, предложенной Гиром, выбор шага осуществляется по формуле
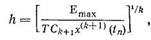 (8.88)
(8.88)
получаемой на основании выражений (8.87) и (8.81).
На основании одного из выражений (8.76) или (8.80) оценивается погрешность вычисления каждой составляющей вектора х сразу для методов трех ближайших порядков
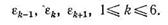 (8.89)
(8.89)
Далее выбираются погрешности, соответствующие наименее точным составляющим вектора переменных х:
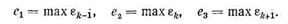
Порядок метода после каждых k шагов вычислений выбирается равным порядку, при котором величина еi минимальна (i = 1, 2, 3). Новое значение шага h определяется в соответствии с выражением (8.88). При этом шаг вычислений при неизменном порядке метода корректируется не сразу, а только при достижении определенных соотношений между действительной и заданной погрешностями вычислений между используемым и разрешенным значениями шага интегрирования. Напомним, что в соответствии с табл. 8.1 частые и большие изменения шага не разрешаются, при этом

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 |
