

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
В маршрутах консультирования сложных консультируемых проблем к числу основных консультационных процедур относятся верификация логических и функциональных схем, синтез и анализ тестов. В этих процедурах требуется многократное выполнение моделирования логических схем. Однако высокая размерность задач логического моделирования (сложные консультируемые проблемы насчитывают десятки—сотни тысяч элементов) существенно ограничивает возможности многовариантного анализа. Преодоление затруднений, обусловливаемых чрезмерной трудоемкостью вычислений, происходит в двух направлениях. Первое из них основано на использовании общих положений блочно-иерархического подхода и выражается в переходе к представлениям подуровня регистровых передач, рассмотренным в п.6.11. Второе направление основано на применении специализированных вычислительных средств логического моделирования, называемых спецпроцессорами или машинами логического моделирования (МЛМ).
Логико-электрическое моделирование. Логико-электрическое моделирование представляет собой разновидность многоуровневого моделирования, при котором в анализируемой схеме одновременно используются модели и методы, относящиеся как к схемотехническому, так и к функционально-логическому иерархическому уровню.
В анализируемой схеме выделяются подсхемы, подлежащие анализу с помощью логических и электрических моделей. Сопряжение моделей подсхем осуществляется с помощью специальных переходных моделей элементов и алгоритмов синхронизации событий в логической и электрической частях. Переходные модели служат для отображения процессов в элементах с преобразованием аналоговых переменных в логические и наоборот.
Логико-электрическое моделирование является незаменимым способом анализа сложных цифроаналоговых схем, поскольку позволяет резко сократить размерность задач, благодаря использованию логических моделей для цифровой части при сохранении необходимой точности анализа, благодаря использованию электрических моделей для аналоговой части схемы.
8.7. Методы многовариантного анализа
Анализ чувствительности. Анализ чувствительности входит составной частью в алгоритмы решения многих консультационных задач, в частности в алгоритмы оптимизации параметров консультируемых проблем градиентными методами. Для анализа чувствительности задаются ММ консультируемой проблемы и вектор тех внутренних и внешних параметров X, влияние которых на вектор выходных параметров Y требуется определить.
В большинстве случаев анализ чувствительности выполняют на основе численного дифференцирования, при котором поочередно задают приращения ∆xi элементам вектора X и определяют получающиеся при этом изменения ∆уj выходных параметров. Тогда абсолютный коэффициент влияния (коэффициент чувствительности) i-гo элемента xi вектора X на j-й выходной параметр уj определяется по формуле
aji = dyj/дxi ≈∆yj/∆xi;
относительный коэффициент влияния
bji= ai хiном/уjном,
где хiном и уjном — номинальные значения параметров xi и yj соответственно.
Такой метод анализа чувствительности называют методом приращений. Если п — размерность вектора X, то в методе приращений требуется п+l раз выполнить одновариантный анализ. Сравнительно большие трудоемкость и погрешности вычислений, присущие численному дифференцированию, относятся к недостаткам этого метода, а универсальность метода — к его преимуществам.
Повысить точность вычислений можно, если, определяя aji, производить одновариантный анализ при значениях параметра хi, равных хiном +∆xi и хiном —∆xi (остальные внутренние параметры при этом сохраняют номинальные значения). Тогда aji есть отношение разности значений уj, полученных в этих двух вариантах, к 2∆xi. Однако в этом методе увеличивается трудоемкость — нужно 2п раз выполнить одновариаитиый анализ.
Применяют также методы, имеющие менее универсальный характер, например методы анализа чувствительности функционалов зависимостей V(t), получающихся при интегрировании систем ОДУ. В этих методах или сокращается число вариантов интегрирования уравнений, или упрощается система интегрируемых уравнений.
Статистический анализ. Статистический анализ имеет целью получение информации о распределении вектора выходных параметров Y при заданном законе распределения случайного вектора X внутренних параметров консультируемой проблемы.
Основным методом статического анализа в САК является метод статистических испытаний (метод Монте-Карло). Каждое k-е статистическое испытание заключается в присвоении элементам xi вектора X случайных значений xik и расчете вектора выходных параметров Yk, с помощью одновариантного анализа. После выполнения запланированного числа N статистических испытаний их результаты Yk обрабатываются с целью оценки числовых характеристик распределений выходных параметров.
В основе алгоритма задания случайных значений параметрам лежит формула
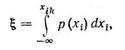
с помощью которой случайное значение ξ величины, равномерно распределенной в интервале [0, 1], преобразуется в случайное значение xik величины xi, имеющей плотность распределения p(xi). Для выработки значений ξ используют стандартные подпрограммы, имеющиеся в программном обеспечении любой универсальной ЭВМ. Выработанное значение ξ интерпретируется как значение F(xik) функции распределения величины xi, так как
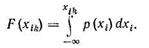
Функция распределения F(xi) монотонная, обычно представлена в памяти ЭВМ в табличной форме, и, следовательно, преобразование ξ в хik, сводится к поиску нужного интервала таблицы и определению результата с помощью интерполяции.
Вместо значений ξ равномерно распределенной случайной величины можно использовать значения иk нормированного нормально распределенного вектора U = (и1, и2, ..., ип) и в алгоритме осуществлять преобразование иik в хik. Но элементы вектора U некоррелированы, поэтому если требуется выработка значений коррелированных случайных величин хi, то вводятся промежуточный вектор коррелированных нормальных величин Z и матрица А преобразования U в Z. Тогда алгоритм задания случайных значений параметрам хi сначала вырабатывает п случайных значений иik, затем преобразует их в вектор Zk = AUk и далее значения этого вектора — в искомые значения хik коррелированных параметров элементов.
Матрица преобразования А, так же как и таблица преобразования Z (или U) в X, определяется на основе обработки результатов предварительно выполненных измерений параметров на партии тестовых образцов либо проблем данного или аналогичного типа.
Результаты статистических испытаний Yk используются для построения гистограмм, подсчета математических ожиданий и дисперсий выходных параметров. Можно рассчитать также коэффициенты корреляции между выходными уj и внутренними хi параметрами, которые используются для определения коэффициентов регрессии уj на хi. Поскольку относительные коэффициенты регрессии являются аналогами коэффициентов влияния xi на уj, регрессионный анализ, совмещаемый со статистическим анализом, следует рассматривать как возможный подход к анализу чувствительности.
Точность и трудоемкость статистических испытаний зависят от их числа N. Для получения большинства интересующих консультанта результатов статистического анализа с приемлемой погрешностью требуется выбирать N=50-200. Однако получение некоторых результатов (таких, как вероятность выхода годных изделий при значениях этой вероятности, близких к единице или нулю) с приемлемой точностью требует значительно большего числа испытаний. Отсюда следует вывод о значительной трудоемкости статистического анализа. Именно по этой причине статистический анализ проводят лишь на заключительных итерациях процесса консультирования.
Разработка тестов консультируемых проблем. Консультирование проблем включает в себя разработку тестов, с помощью которых проверяется эффективность (достоверность) сформированных рекомендаций по решению задач консультируемой проблемы.
Назовем тестируемый объект блоком. Входное воздействие обозначим вектором X=(х1, х2, ..., хп), а выходную реакцию — вектором Y= (у1, у2, ..., ут), где xi — булева переменная на i-м входе; уj — то же на j-м выходе. Определенному значению Хk вектора X в блоке эффективных рекомендаций соответствует значение Yk вектора Y. Пару {Xk, Yk} будем называть элементарной проверкой.
С помощью одной элементарной проверки нельзя выявить все неэффективных рекомендации даже ограниченного класса и тем более нельзя локализовать неэффективную рекомендацию. Поэтому тест представляет собой множество элементарных проверок. Число элементарных проверок в тесте называют его длиной. Тест, предназначенный только для установления факта наличия блока неэффективных рекомендаций, называют контролирующим (проверяющим), а тест, с помощью которого дополнительно устанавливается неэффективная рекомендация в блоке, — диагностическим. Тест, который выявляет все неэффективные рекомендации заданного класса, будем называть полным, а тест, из которого нельзя исключить ни одну элементарную рекомендацию без изменения его полноты, — неизбыточным.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 |
