
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
В связи со сказанным упомянем о полезном понятии чувствительности функции у (х) при данном значении аргумента: это коэффициент пропорциональности между малыми относительными изменениями ![]() аргумента и
аргумента и ![]() функции, т. е.
функции, т. е. ![]() , откуда
, откуда
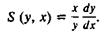
Аналогично определяется чувствительность функции нескольких переменных по каждой из них. Особенно просто выражается чувствительность для степенных функций: так, если ![]() то,
то, ![]()
Для оценки возможного влияния ошибок вычислительного метода наиболее убедительным является сравнение ответа с результатом решения той же задачи с помощью другого, независимого метода. Так, решение краевой задачи, полученное методом сеток, можно проверить, построив ее решение по методу Галеркина или методу конечных элементов. Возможна также проверка решения в рамках одного метода. Например, результат, полученный методом сеток, можно проверить, уменьшив шаг сетки; результат применения метода Галеркина можно проверить, изменив базис, и т. д. (Впрочем, для некоторых простых задач, например задачи Коши для обыкновенного дифференциального уравнения, выдерживание заданной точности может осуществляться автоматически с помощью стандартной программы на ЭВМ.) Если речь идет о решении серии однотипных задач, различающихся значениями параметров, то такой контроль полезно провести для нескольких наборов значений параметров, достаточно убедительно представляющих полный диапазон их значений. Для некоторых таких наборов решение или его компоненты (амплитуда и т. п.) могут быть известны из каких-либо дополнительных соображений — например, из эксперимента; соответствие построенного решения этим сведениям также повышает доверие к нему.
Что касается ошибок округления, то в эпоху ЭВМ они приобрели особую актуальность. Когда в длинных цепочках вычислений последующие выкладки все время опираются на результаты предыдущих, ошибки округления могут разрастаться до такой степени, что, начиная с некоторого момента, мы будем иметь дело в сущности с одними лишь ошибками — как бы шум полностью заглушит мелодию.
Вот яркий пример такого эффекта. Пусть нам надо вычислить интеграл 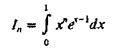
При ![]() Заметим, что при
Заметим, что при ![]() имеем
имеем ![]() и потому
и потому
![]() (1)
(1)
Кроме того, с помощью интегрирования по частям легко установить, что
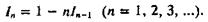 (2)
(2)
Поэтому, вычислив ![]() можно с помощью рекуррентной формулы (2) последовательно вычислить
можно с помощью рекуррентной формулы (2) последовательно вычислить ![]() Приведем результаты
Приведем результаты![]() вычисления таким методом значений
вычисления таким методом значений ![]()
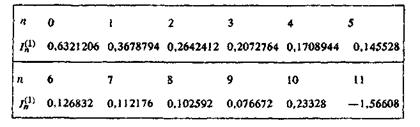
При п>9 эти результаты явно ошибочны, так как противоречат неравенствам (1).
Причины ошибки легко понять: при вычислении ![]() первоначальная погрешность округления f0 умножается на п!, а так как точное значение In, стремится к нулю при
первоначальная погрешность округления f0 умножается на п!, а так как точное значение In, стремится к нулю при ![]() то относительная погрешность стремительно возрастает.
то относительная погрешность стремительно возрастает.
Данные вычисления нетрудно перестроить так, чтобы погрешность не разрасталась, а уменьшалась. Для этого достаточно в соотношении (2) заменить п на п + 1 и переписать его в виде
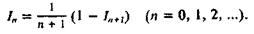
Теперь можно вычислять In, переходя от бóльших значений п к меньшим, положив некоторое стартовое In просто равным нулю, причем при последовательных вычислениях влияние погрешности этого допущения и последующих округлений будет затухать. Так, положив ![]() получаем значения
получаем значения
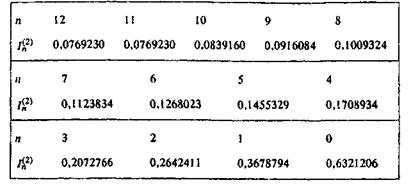
Более точные вычисления дают значения

а в остальных результатах для ![]() все выписанные цифры верны. Хорошо видно, как происходит приближение значений
все выписанные цифры верны. Хорошо видно, как происходит приближение значений ![]() к точным, и наоборот, удаление
к точным, и наоборот, удаление ![]() от них.
от них.
Ошибки округления при решении дифференциальных уравнений дискретными методами могут создать парадоксальную ситуацию: желая повысить точность результата, мы измельчаем шаги, но если применяемый метод выбран неудачно (неустойчив в вычислительном отношении), то из-за увеличения числа действий ошибки округления начинают сказываться сильнее и итоговая погрешность возрастает. Часто такая неустойчивость обнаруживается сама, порождая быстро разрастающиеся осцилляции решения и даже переполнение ячеек, совершенно не согласующиеся с реальным смыслом задачи. В менее острых ситуациях влияние ошибок округления можно выяснить с помощью повторного вычисления с удвоенной точностью, или с одной недостающей значащей цифрой, или с измененным шагом интегрирования и т. д.
3.8.11. Особенности процесса решения содержательных задач
Мы уже говорили, что при решении уравнений, составляющих математическую модель, за математическими величинами все время скрываются их физические прототипы. Это дает возможность в процессе решения в необходимых случаях опираться на интуицию, применять наглядные и физические соображения. Однако слишком вольные отклонения от строгих математических рассуждений могут приводить к существенным ошибкам; поэтому логические пробелы и другие слабые места в рассуждениях должны ясно осознаваться. В то же время интуицию, позволяющую выбрать правильный метод решения и избежать ошибок при наличии таких слабых мест, надо всячески развивать.
Одной из характерных черт прикладных математических исследований является широкое применение понятий, не вполне четко определенных с позиций строгой математики; такие понятия принято называть размытыми. Так, мы можем говорить, что тот или иной вычислительный метод в определенных условиях хорош или плох, что некоторый ряд или итерационный процесс сходится быстро или медленно, что погрешность приближенного решения велика или мала и т. п., не давая этим терминам (по существу, понятиям) строгого определения — что не мешает им нести полезную информацию.
Важным размытым понятием, широко применяемым при решении содержательных задач, является понятие практической сходимости бесконечного процесса, означающее возможность получения ответа за приемлемое число шагов с приемлемыми точностью и достоверностью. Допустим, что речь идет о бесконечном ряде. В курсе математики, изучая сходимость ряда, мы обычно считаем, что все его члены заданы явной формулой или удовлетворяют явно выписанному неравенству. В отличие от этого в приложениях математики (например, при применении метода малого параметра) обычно члены ряда просто вычисляют один за другим. Ясно, что при таком образе действий строго доказать сходимость ряда невозможно. Но этого и не делают; вместо этого сравнивают друг с другом последовательные частные суммы ряда и если обнаружится отчетливая тенденция к сходимости (кстати, это понятие также является размытым) и нет оснований ожидать, что дальнейшие члены нарушат эту тенденцию, то вычисления прекращают, принимая полученную частную сумму за полную сумму ряда. Аналогичным образом рассматривают на практике бесконечные процессы других типов, причем часто совершение 2— 3 шагов позволяет уловить тенденцию. Так, при применении метода сеток заключение о практической сходимости можно сделать, сравнив результаты вычислений при уменьшении шага сетки; если применяют метод типа Галеркина, то сравнивают результаты вычислений при расширении множества координатных функций и т. п.
К сказанному добавим, что признание того или иного процесса практически сходящимся или расходящимся существенно зависит от тех вычислительных средств, которыми мы располагаем. При этом бесконечный процесс — например, ряд,— сходящийся в чисто математическом смысле, не всегда является практически сходящимся; см. примеры в п. 3.8.12 или еще более эффективный пример
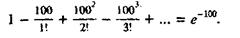
(Прикидка показывает, что для подсчета суммы этого «быстро сходящегося» с абстрактных позиций ряда с точностью до 10 верных цифр потребуется вычислить значения примерно 400 членов с точностью до 10-55, из-за чего средние члены в этой сумме придется подсчитывать со 100 верными цифрами!) И обратно, примеры п. 3.8.3 показывают, что ряд, расходящийся в смысле чистой математики, может оказаться практически сходящимся. Правильная квалификация процессов как практически сходящихся опирается не только на логические рассуждения, но и в еще большей мере на анализ своего и чужого опыта, на пробы и ошибки, позволяющие накопить правильную интуицию.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 |
