
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Важный частный случай размытых понятий составляют размытые величины. Они сохраняют некоторые признаки математических величин, но не обладают четкостью последних. Пусть, например, мы добиваемся того, чтобы погрешность приближенного решения оказалась малой. Но что означает выражение «малая погрешность»? Это зависит от типа рассматриваемых задач, от традиций, возможных последствий ошибки и других явно или неявно не очень четко формулируемых условий, причем возникающие критерии малости сами являются размытыми. Допустим, что малой условились считать погрешность в 1%, а она получилась равной 1,5%. Тогда в большинстве случаев погрешность все равно назовут малой; погрешность в 10% вряд ли будет сочтена малой, а по поводу погрешности в 3% может возникнуть дискуссия, неизбежная при применении размытых понятий на нечеткой границе их действия.
При исследовании математических моделей широко применяется рассуждение по аналогии. Пусть, например, показано, что некоторый метод хорошо проявил себя при решении какой-то задачи З. Тогда часто тот же метод уже без дополнительного исследования применяют и при решении других задач, аналогичных З; ссылка на задачу З как бы служит обоснованием хорошего качества решения. Конечно, при этом можно и промахнуться, так как каждая новая задача имеет свою специфику. Но все же чаще разумная аналогия оказывается плодотворной, а если сохранять бдительность и действовать на основе здравого смысла и интуиции, то ошибок, как правило, удается избежать.
В исследование математической модели может быть включен численный или физический эксперимент и т. д. В книге содержится подробный анализ различных типов рассуждений, не обязательно вполне совершенных с позиций формальной логики, но полезных и потому широко применяемых при решении содержательных задач; там такие рассуждения названы рациональными.
3.8.12. О применении ЭВМ
ЭВМ превратились в повседневное орудие прикладной математики. Они не только повысили на много порядков скорость и точность вычислений для известных ранее классов задач, но и впервые сделали возможным решение огромного числа других задач. Однако ЭВМ потребовали существенного изменения многих вычислительных методов и даже всей «вычислительной идеологии».
Значительную роль приобрел вычислительный эксперимент. В раде случаев вместо попытки аналитического исследования свойств решений оказалось более целесообразным выяснить эти свойства, построив решения на ЭВМ. Это относится, в частности, к решениям дифференциальных уравнений, включая свойства, связанные с асимптотическим поведением решений, например с выяснением устойчивости. Разновидностью вычислительного эксперимента является так называемое имитационное моделирование, применяемое для анализа поведения сложных экономических и т. п. задач, для которых математическую модель в виде системы уравнений даже выписать затруднительно.
В качестве примера перестройки подходов, вызванной ЭВМ, укажем на решение нелинейных дифференциальных уравнений. В «домашинную» эру считалось само собой разумеющимся, что если в таком уравнении можно понизить порядок с помощью некоторой подстановки, то это следует сделать. Например, для решения уравнения
![]() (1)
(1)
рекомендовалось рассматривать зависимость ![]() от х, что приводит к уравнению первого порядка
от х, что приводит к уравнению первого порядка ![]()
![]() Если нам удастся найти его решение р=φ(х), удовлетворяющее заданным начальным условиям, то получаем соотношение
Если нам удастся найти его решение р=φ(х), удовлетворяющее заданным начальным условиям, то получаем соотношение ![]() и, вновь применяя начальное условие, приходим к конечному уравнению, связывающему t с х. Такая процедура при аналитическом исследовании иногда приводит к цели, однако это удается лишь в редких случаях (если не говорить о специально подобранных примерах) и приходится прибегать к численному интегрированию. Но для численного решения эта процедура плохо приспособлена, менее трудоемким оказывается непосредственное численное интегрирование уравнения (1) без понижения его порядка. Так и надо поступать при работе на ЭВМ. Таким образом, надо уметь хотя бы совсем грубо оценивать объем вычислительной работы, необходимой для доведения решения задачи до конца различными методами, имея в виду имеющиеся в распоряжении вычислительные средства.
и, вновь применяя начальное условие, приходим к конечному уравнению, связывающему t с х. Такая процедура при аналитическом исследовании иногда приводит к цели, однако это удается лишь в редких случаях (если не говорить о специально подобранных примерах) и приходится прибегать к численному интегрированию. Но для численного решения эта процедура плохо приспособлена, менее трудоемким оказывается непосредственное численное интегрирование уравнения (1) без понижения его порядка. Так и надо поступать при работе на ЭВМ. Таким образом, надо уметь хотя бы совсем грубо оценивать объем вычислительной работы, необходимой для доведения решения задачи до конца различными методами, имея в виду имеющиеся в распоряжении вычислительные средства.
В качестве другого примера такой перестройки укажем на вычисление сумм числовых рядов. Ранее для этого широко применялись разнообразные искусственные преобразования, некоторые из них и сейчас не потеряли актуальности; однако при применении ЭВМ нередко более эффективным оказывается непосредственное суммирование членов ряда. Но при этом, как и в других подобных случаях, весьма ответственным этапом является подготовка задачи к программированию, т. е. выбор алгоритма, наиболее эффективного для решения конкретной задачи.
Поясним сказанное на простом примере. Пусть мы хотим вычислить сумму бесконечного ряда
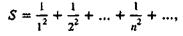
причем, понадеявшись на мощь ЭВМ, решили не применять никаких ухищрений, а просто подсчитывать и складывать члены ряда, пока они не обратятся в машинный нуль. Однако несложный подсчет, который мы предоставляем читателю, показывает, что для ЭВМ средней мощности на это уйдет около 10 ч; при этом итоговая ошибка, даже без учета округлений, получится на десять порядков выше последних слагаемых.
Описанная схема вычислений крайне нерациональна. Результат получится гораздо быстрее и точнее, если, например, просуммировать 104 первых членов ряда (это займет время порядка 0,1 с), а остаток заменить по приближенной формуле
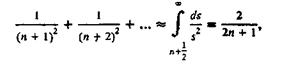
точность которой имеет порядок 0,1 п-3. Таким образом, разумная подготовка задачи к программированию позволила здесь уменьшить время работы более чем на пять порядков! (Конечно, в данном примере можно было воспользоваться и справочниками, согласно которым![]() но это редкий случай, когда сумма ряда явно выражается через известные константы.)
но это редкий случай, когда сумма ряда явно выражается через известные константы.)
В качестве еще одного примера неразумной и разумной организаций алгоритма приведем вычисление значения е-10, которое с точностью до 10-7 равно 4,54∙10-5. Вычисление на микрокалькуляторе по тейлоровскому разложению
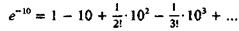
дает значение 1,112∙10-4, т. е. ошибку в 140 %! Причину этого нетрудно понять: хотя члены ряда в конечном счете стремятся к нулю, они перед этим успевают сильно возрасти, а так как вся сумма мала, т. е. эти возросшие члены почти взаимно уничтожаются, то погрешности в них оставляют существенный вклад (о подобной ситуации мы упоминали в ранее). Простая перестройка алгоритма в соответствии с формулой
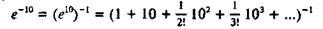
устраняет эту трудность и приводит к значению 4,57∙10-5 с погрешностью 0,7 %.
Если решение математической задачи не сводится к указанию одного или небольшого набора чисел, то возникает еще проблема представления результатов, чтобы можно было их обозреть и ими пользоваться. Такая проблема возникает, в частности, для задач, содержащих параметры. Приведем простой пример: пусть мы хотим составить таблицу, с помощью которой можно было бы решать полное кубическое уравнение
![]() (2)
(2)
при любых задаваемых коэффициентах а, b, с, d. Тогда, если допустить, что каждый из них может принимать 50 значений — а это не так уж много,— то всего получится ![]() комбинаций этих значений. Средней ЭВМ для выдачи результатов потребуется неделя непрерывной работы (основное время уйдет на печать), а результаты займут около 200 км ленты и ими практически невозможно будет пользоваться! Поэтому весьма актульным является един из основных тезисов, неоднократно подчеркиваемый Р. Хеммингом в книге, предназначенной для инженеров, имеющих дело с ЭВМ: прежде чем решать задачу, подумай, что делать с ее решением.
комбинаций этих значений. Средней ЭВМ для выдачи результатов потребуется неделя непрерывной работы (основное время уйдет на печать), а результаты займут около 200 км ленты и ими практически невозможно будет пользоваться! Поэтому весьма актульным является един из основных тезисов, неоднократно подчеркиваемый Р. Хеммингом в книге, предназначенной для инженеров, имеющих дело с ЭВМ: прежде чем решать задачу, подумай, что делать с ее решением.
На самом деле положение с таблицей для решения уравнения (2) не такое уж печальное. Сделав подстановку ![]() получаем уравнение для и:
получаем уравнение для и:
![]() (3)
(3)
Выберем α и β так, чтобы между новыми коэффициентами имели место такие соотношения:
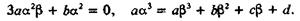
Отсюда находим
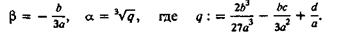
При таких![]() уравнение (3) после деления на
уравнение (3) после деления на ![]() приобретает вид
приобретает вид
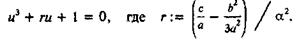 (4)
(4)
Это уравнение содержит всего один параметр r. Таблицу решений уравнения (4) в зависимости от r уже нетрудно составить с помощью ЭВМ, даже если r придать не 50, а 5000 значений. В результате решение уравнения (2) можно будет найти с помощью построенной таблицы и(r), извлечения корня (для чего потребуется еще одна таблица или микрокалькулятор) и простых арифметических действий по схеме:![]()
Это, конечно, несравненно проще, чем применение таблицы с четырьмя или даже с тремя входами.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 |
